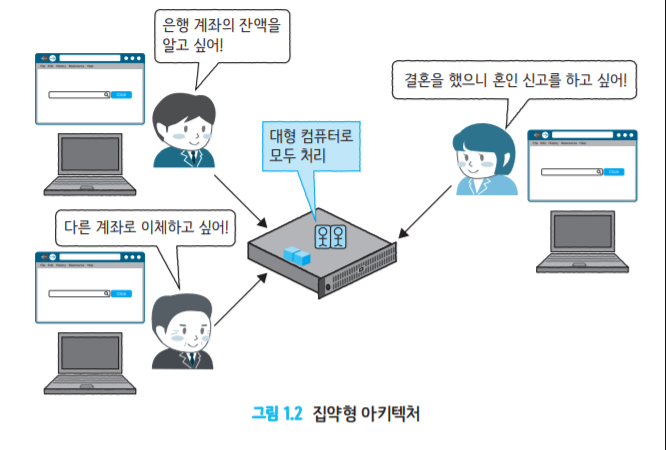
서버란? 물리서버와 논리 서버로 구성 컴퓨터 자체(하드웨어)를 가리크는 물리 서버 컴퓨터에서 동작하고 있는 소프트웨어 논리 서버 (웹서버, DB서버)
분할형 아키텍처는 역할 분담에 따라 구분
수직 분할형 아키텍처
수평 분할형 아키텍처
수직 분할형 아키텍처
역할에 따라 위 또는 아래 계층으로 나뉨
2가지 존재 - 클라이언트-서버형 아키텍처 - 3계층형 아키텍처
클라이언트-서버형 아키텍처
서버 1개에서 모든 클라이언트 처리를 접수한다.
클라이언트 측에 전용 소프트웨어를 설치해야 한다.
서버 처리에 집중되면 확장성에 한계 발생
이런 단점을 극복하고자 3계층형 아키텍처가 나옴
3계층형 아키텍처
클라이언트-서버형을 발전 시킴
프레젠테이션 계층 / 애플리케이션 계층 / 데이터 계층 3층 구조로 분할하여 서버 부하 집중을 개선
스프링의 MVC와 비슷
프레젠테이션 계층 : 사용자의 요청을 받아서 화면에 표시(웹 서버)
애플리케이션 계층 : 무엇을 할지 판단해서 필요한 경우 데이터 계층에 질의 (애플리케이션(AP)서버)
데이터 계층 : 데이터 입출력을 담당한다.(DB서버)
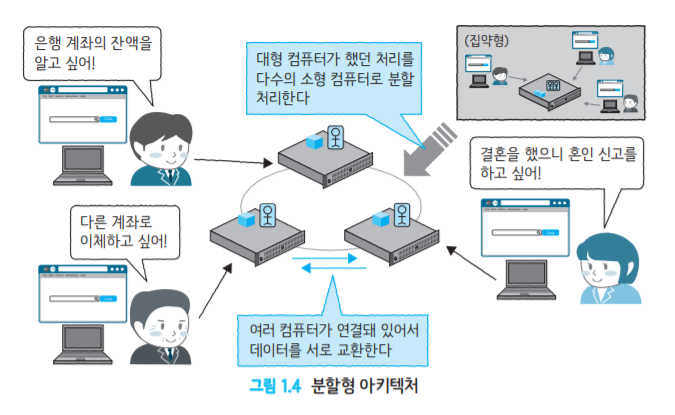
수평 분활형 아키텍처
수직 분활형 아키텍처를 하나 더 늘려 확장성, 안정성을 향상시키는 것
단순 수평 분할형 아키텍처 & 공유형 아키텍처로 나뉨
단순 수평 분할형 아키텍처
샤딩 또는 파티셔닝이라고 불린다.
잘 안쓰임 (본사, 동탄 따로 서버쓰는 꼴) -> 공유형 아키텍처
장점
수평으로 서버를 늘리기 때문에 확장성이 향상된다.
분할한 시스템이 독립적으로 운영되므로 서로 영향을 주지 않는다.
단점
데이터를 일원화해서 볼 수 없다.
애플리케이션 업데이트는 양쪽을 동시에 해 주어야 한다.
처리량이 균등하게 분할돼 있지 않으면 서버별 처리량에 치우침이 생긴다.
공유형 아키텍처
공유형은 단순형과 달리 일부 계층에서 상호 접속이 이루어진다.
장점
수평으로 서버를 늘리기 때문에 확장성이 향상된다.
분할한 시스템이 서로 다른 시스템의 데이터를 참조할 수 있다.
단점
분할한 시스템 간 독립성이 낮아진다.
공유한 계층의 확장성이 낮아진다.
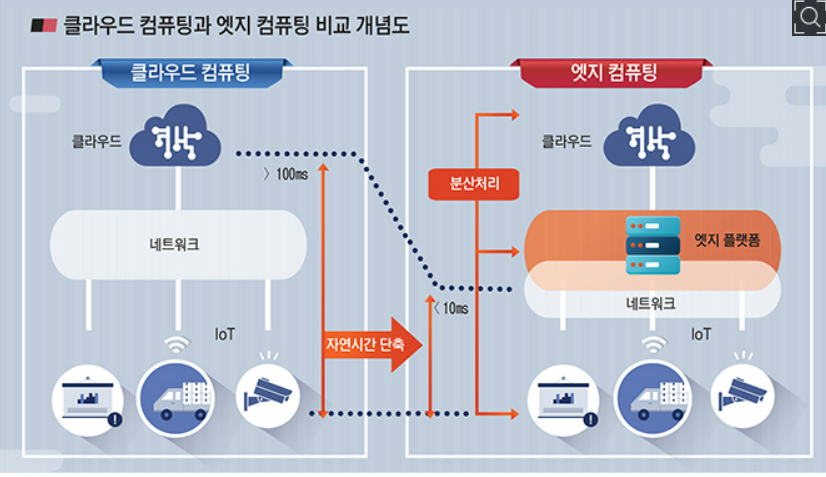
아키텍처 트랜드 오픈화(분산) -> 가상화/클라우드(집중) -> 엣지 컴퓨팅(분산) * 엣지 컴퓨팅 : 최신 키워드, 지리적으로 가까운 위치에 있는 서버로 처리하고, 처리 결과만 중앙으로보내는 아키텍처 엣지 컴퓨팅에서는 관리를 위한 수고를 줄이면서, 서버를 분산하는 것이 중요하다.
지리 분할에 따른 아키텍처
스탠바이형 아키텍처와 재해 대책형 아키텍처
스탠바이형 아키텍처
액티브 - 스탠바이로 구성
액티브 측이 고장나면 스탠바이를 이용
단점은 한 쪽이 계속 놀고 있는 상태가 되기 때문에 양쪽 서버로를 교차이용 하는 경우도 많음
@Lob에는 지정할 수 있는 속성이 없고, 대신에 매핑하는 필드 타입이 문자면, CLOB으로 매핑하고 나머지는 BLOB로 매핑한다.
@Transient
객체 임시로 어떤 값을 넣고 싶을 때 사용하고 데이터베이스에는 반영이 안된다.
데이터 베이스 스키마 자동 생성
사실상 운영에선 사용하진 않고, 개인적으로 개발할때 정도 사용한다.
DDL을 애플리케이션 실행 시점에 자동 생성
테이블 중심 -> 객체 중심
데이터베이스 방언을 활용해서 데이터베이스에 맞는 적절한 DDL 생성
xml 다음과 같이 입력하면 초기 실행 시 자동으로 테이블을 생성한다.
<property name="hibernate.hbm2ddl.auto" value ="create"/>
위의 value 속성은 개발 단계마다 다르게 생성할 수있다.
개발 초기 단계에는 create 또는 update
테스트 서버는 update 또는 validate(엔티티와 테이블이 정상 매핑되었는지만 확인)
스테이징과 운영서버는 validate 또는 none
운영 장비에는 절대 create, create-drop, update 사용하면 안된다.
기본 키 매핑
기본 키 매핑 어노테이션
@Id
@GeneratedValue
@Id @GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
기본 키 매핑 방법
데이터베이스마다 기본 키를 생성하는 방식이 서로 다르므로 이 문제를 해결하기는 쉽지 않다. JPA는 이런 문제들을 어떻게 해결하는지 알아보자
직접 할당 : @Id만 사용
자동 생성(@GeneratedValue)
IDENTITY : 데이터베이스에 위임(DB에 따라서 알아서(임의로) 해줌), MYSQL, PostgreSQL, SQL Server, DB2에서 사용
MySQL의 AUTO_INCREMENT
SEQUENCE : 데이터베이스 시퀀스 오브젝트 사용, ORACLE
@SequenceGenerator 필요
TABLE : 키 생성용 테이블 사용, 모든 DB에서 사용
@TableGenerator 필요
기본 키 직접 할당 전략
@Id 적용 가능 자바 타입
자바 기본형
자바 래퍼wrapper형
String
java.util.Date
java.sql.Date
java.math.BigDecimal
java.math.BigInteger
SEQUENCE 전략
sequenceName 속성의 이름으로 BOARD_SEQ 를 지정했는데 JPA는 이 시퀸스 생성기를 실제 데이터베이스 BOARD_SEQ 시퀀스와 매핑한다. sequenceName을 따로 설정하지 않으면 hibernate_sequence와 같이 자동으로 설정된다.
@Entity
@SequenceGenerator(
name = "BOARD_SEQ_GENERATOR".
sequenceName = ”BOARD_SEQ”, //매핑할 데이터베이스 시퀀스 이름
initialvalue = 1,
allocationsize = 1)
public class Board {
@IdQGeneratedValue(
strategy = GenerationType.SEQUENCE,
generator = "BOARD_SEQ_GENERATOR")
private Long id;
...
}
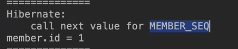
call next value for MEMBER_SEQ란? 영속성 컨텍스트에 의해 JPA는 항상 PK값을 알아야한다. 그래서 MEMBER_SEQ값에서 id값을 조회한다. 그러고 나서 em.persist를 해준다.
commit 하는 시점에 insert쿼리가 날라간다.
SquenceGenerator.allocationSize의 기본값이 50인 이유는 최적화 때문이다 allocationSize 값이 50이면 시퀀스를 한 번에 50 증가 시킨 다음에 1~50까지는 메모리에서 식별자를 할당한다. 이 최적화 방법은 시퀀스 값을 선점 하므로 여러 JVM이 동시에 동작 해도 기본 키 값이 충돌하지 않는 장점이 있다. 반면에 데이터베이스에 직접 접근해서 데이터를 등록할 때 시퀀스 값이 한번에 많이 증가한다는 점을 염두해 두어야 한다. 참고로 앞서 설명한 hibernate.id.new_generator_mappings 속성을 true로 설정해야 지금까지 설명한 최적화 방법이 적용된다.
TABLE 전략(운영에서 잘 쓰이지 않음)
TABLE 전략은 키 생성 전용 테이블을 하나 만들고 여기에 이름과 값으로 사용할 컬럼을 만들어 데이터베이스 시퀀스를 흉내내는 전략이다.
장점 : 모든 데이터베이스에 적용 가능
단점 : 성능
@Entity
@TableGenerator(
name = "BOARD_SEQ_GENERATOR",
table = ”MY_SEQUENCES",
pkColumnValue = ”BOARD_SEQ”,
allocationsize = 1)
public class Board {
@Id
@GeneratedValue(
strategy = GenerationType.TABLE,
generator = '' BOARD_SEQ_GENERATOR''
)
private Long id;
...
}
TABLE 전략과 최적화 TABLE 전략은 값을 조회하면서 SELECT 쿼리를 사용하고 다음 값으로 증가시키기 위해 UPDATE 쿼리를 사용한다. 이 전략은 SEQUENCE 전략과 비교해서 데이터베이스와 한번 더 통신하는 단점이 있다. TABLE 전략을 최적화하려면 TableGenerator.allocationSize를 사용하면 된다.
권장하는 식별자 전략
기본 키 제약 조건 : null 아님, 변하면 안된다.
미래까지 이 조건에 만족하는 자연키는 찾기 어렵다. 대리키(대체키)를 사용하자.
예를 들어 주민등록번호도 기본 키로 적절하지 않다.
권장 : Long형 + 대체키 + 키 생성전략 사용
AUTO 전략
GenerationType.AUTO는 선택한 데이터베이스 방언에 따라 IDENTITY, SEQUENCE, TABLE 전략 중 하나를 자동으로 선택한다. AUTO 전략의 장점은 데이터베이스를 변경해도 코드를 수정할 필요가 없다는 것이다. AUTO를 사용할 때 SEQUENCE나 TABLE 전략이 선택되면 시퀀스나 키 생성용 테이블을 미리 만들어 두어야 한다.
IDENTITY 전략
기본 키 생성을 데이터베이스에 위임
IDENTITY 전략은 지금 설명한 AUTO INCREMENT를 사용한 예제처럼 데이터베이스에 값을 저장하고 나서야 기본 키 값을 구할 수 있을 때 사용한다.
문제점 : IDENTITY 전략은 데이터를 데이터베이스에 INSERT한 후에 기본 키 값을 조회할 수 있다. 티티가 영속 상태가 되려면 식별자가 반드시 필요하다. 그런데 IDENTITY 식별자 생성 전략은 엔티티를 데이터베이스에 저장해야 식별자를 구할 수 있으므로 em.persist()를 호출하는 즉시 INSERT SQL 이 데이터베이스에 전달된다. 따라서 이 전략은 트랜잭션을 지원하는 쓰기 지연이 동작하지 않는다. 왜냐하면 JPA는 보통 트랜잭션 커밋 시점에 INSERT SQL 실행합니다. 그리고 AUTO_INCREMENT는 데이터베이스에 INSERT SQL을 실행한 이후에 ID 값을 알 수 있습니다.
결합 인덱스란 두 개 이상의 컬럼을 합쳐서 인덱스를 만드는 것을 말합니다. 주로 단일 컬럼으로는 나쁜 분포도를 가지지만 여러 개의 컬럼을 합친다면 좋은 분포도를 가지고, Where절에서 AND 조건에 많이 사용되는 컬럼들을 결합 인덱스로 구성합니다.
결합 인덱스 컬럼 선택
1.where절에서 and 조건으로 자주 결합되어 사용되면서 각각의 분포도 보다 두 개 이상의 컬럼이 결합될 때 분포도가 좋아지는 컬럼들
2.다른 테이블과 조인의 연결고리로 자주 사용되는 컬럼들
3.order by에서 자주 사용되는 컬럼들
4.하나 이상의 키 컬럼 조건으로 같은 테이블의 컬럼들이 자주 조회될 때
결합 인덱스의 컬럼 순서 결정
결합 인덱스를 만들 때 결합 인덱스를 구성하는 컬럼들의 배열 순서는 아주 중요하기에 신중하게 결정하여야 합니다.컬럼의 순서를 잘못 배열하면 결합 인덱스의 발동 확률이 매우 낮아질 수 있기 때문입니다.만약 select 문의 where절에 결합 인덱스의 첫 번째 컬럼을 조건에 사용하였다면 그 질의문은 결합 인덱스를 사용할 수 있습니다. 하지만 개발자가 결합 인덱스의 두번째 컬럼만을 where 절에 조건으로 사용하고 결합 인덱스를 사용하고자 했다면 실행계획은 인덱스를 사용하지 못합니다.따라서 쿼리문 작성 시 결합 인덱스를 사용하고자 한다면 반드시 결합 인덱스의 컬럼 중 선행하는 컬럼부터 조건에 지정하여 사용하여야 합니다.조건은 컬럼 전체를 순서대로 사용할 수도 있고, 아니면 선행하는 일부 컬럼을 순서대로 사용할 수 있습니다.
결합 인덱스 컬럼의 설정 시 고려해야 할 우선순위
1.where절 조건에 많이 사용되는 컬럼이 우선시
2. Equal('=')로 사용되는 컬럼 우선
3.분포도가 좋은 컬럼을 우선
4.자주 이용되는 순서대로 결합 인덱스 컬럼의 순서 결정
결합 인덱스 사용 예시
결합 인덱스 생성
create index emp_pay_idx on emp_pay(급여년월, 급여코드, 사원번호);
emp_pay 테이블에서 급여년월, 급여코드, 사원번호 컬럼으로 emp_pay_idx라는 결합 인덱스를 생성하였습니다.
select * from emp_pay where 급여년월 = '202107';
select * from emp_pay where 급여년월 = '202107' and 급여코드 ='정기급여';
select * from emp_pay where 급여년월 = '202107' and 급여코드 = '정기급여' and 사원번호 = '20210401';
select 문장의 where 절에서는 다음과 같은 조건 조합에서 인덱스가 사용되게 됩니다.
결합 인덱스의 효율성이 떨어지는 경우
결합 인덱스도 일반적인 인덱스와 마찬가지로 데이터들이 정렬되어 보관되기 때문에 소수의 데이터를 빠르게 찾는 것에는 유리하지만 아래와 같이 스캔이 많이 생기게 된다면 효율성이 떨어지게 됩니다. 아래의 예시들은 emp_pay_idx 인덱스를 사용하기는 하지만 스캔이 많이 생기는 경우로 인덱스의 효율성이 떨어지는 경우들의 예시입니다.
select * from emp_pay where 급여년월 LIKE '2021%' and 급여코드 = '정기급여';
위 조건절의 경우 결합 인덱스의 첫 번째 컬럼인 급여년월의 조건이 있더라도 Equal(=)이 아닌 범위 연산자인 LIKE '2021%' 조건을 사용했으므로, 세개의 칼럼이 모두 필요한 emp_pay_idx 인덱스를 찾을 때 두번째 칼럼인 급여코드에 대한 조건을 B*Tree에서 쉽게 찾을수가 없게 됩니다. 이는 결합 인덱스가 각 칼럼별로 정렬이 되어 있는 것이 아니라 첫번째, 두번째, 세번째 칼럼이 결합이 되어 정렬이 되어있기 때문입니다. 이때 급여코드에 대한 조건은 인덱스를 찾아가는 검색조건이 아니라 인덱스 값이 조건에 맞는지 여부를 검증하는 체크 조건이 됩니다.
select * from emp_pay where 급여년월 = '202107' and 사원번호 = '20210401';
위 조건절의 경우는 결합 인덱스의 첫번째 칼럼인 급여년월의 조건이 equal(=)이더라도 두번째 컬럼인 급여코드에 대한 조건이 없으므로 세번째 칼럼인 사원번호 조건을 검색 조건이 아닌 체크 조건으로 밖에 사용할 수 없게 됩니다. 즉 결합 인덱스에서 급여년월인 모든 데이터를 찾아서 사원번호 조건에 맞는지 일일이 확인하는 풀 테이블 스캔이 일어나고 있는 셈입니다.
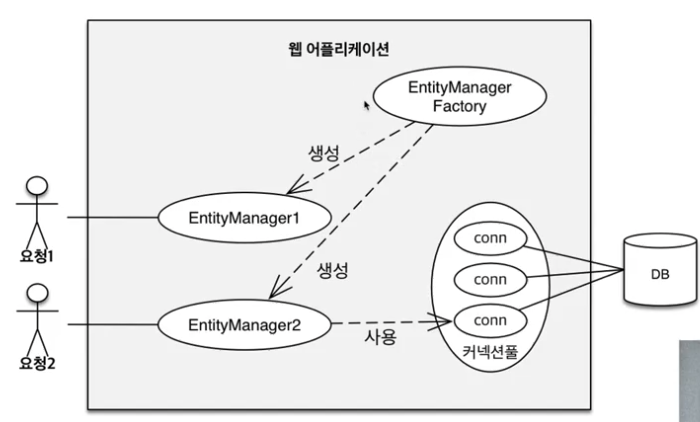
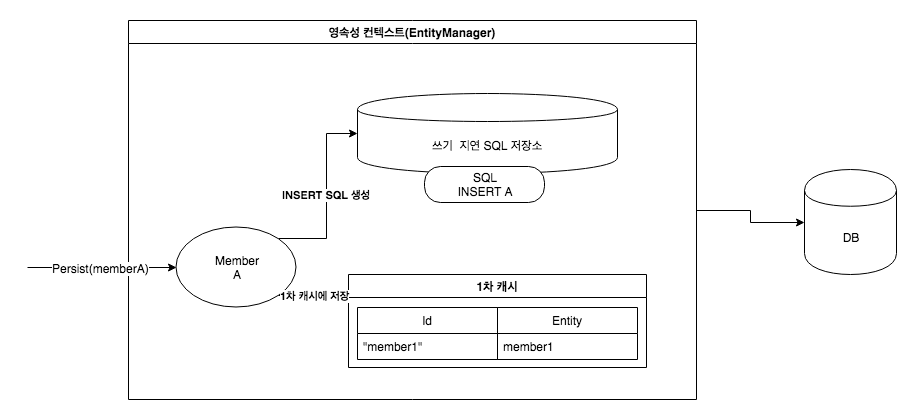
우리는 .persist를 해당 entity를 DB에 저장한다고 이해했다. 그렇지않고 우리는 entity를 DB에 저장하는 것이 아닌 영속성 컨텍스트에 저장하는 것이다.
영속성 컨텍스트는 논리적인 개념이다.
눈에 보이지 않는다.
엔티티 매니저를 통해서 영속성 컨텍스트에 접근
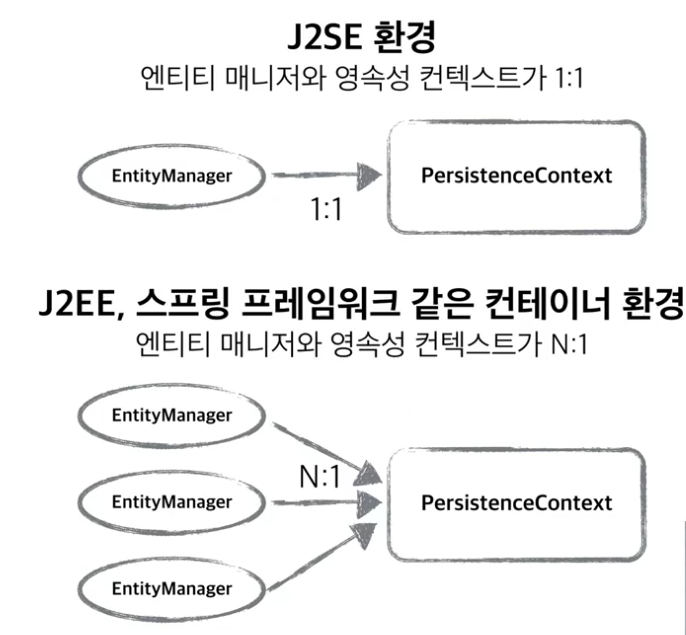
영속성 컨텍스트 생성 과정
EntityManasger를 생성하면 위 그림 처럼 영속성 컨텍스트가 생성됩니다.
엔티티의 생성주기
비영속(new/transient)
영속성 컨텍스트와 전혀 관계가 없는 새로운 상태
영속(managed)
영속성 컨텍스트에 관리되는 상태
준영속(detached)
영속성 컨텍스트에 저장되었다가 분리된 상태
삭제(removed)
삭제된 상태
비영속 상태(JPA랑 전혀 관계 없는 상태)
영속
DB에는 언제 저장하는가?
em.persist(member);
위의 상태에서는 DB에 저장한 것이 아닌 영속성 컨텍스트에 저장한 것이다. 그렇다면 언제 DB에 저장하는 것 인가?
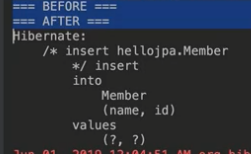
확인 코드
System.out.print("=== before ===");
em.persist(member);
System.out.print("=== after ===");
결과 : before와 after사이에 insert문이 날라가지 않는다.
이유
tx.commit;
트랜잭션 커밋 상태에서 결국 query가 날라가게 된다.
준영속, 삭제
회원 엔티티를 영속성 컨텍스트에서 분리, 준영속 상태
em.detach(member);
객체를 삭제한 상태
em.remove(member);
영속성 컨텍스트의 이점
바로 db에 저장하지 않고 중간과정을 거친다. 그래서 얻는 것은 다음과 같다.
1차 캐시
동일성 보장
트랜잭션을 지원하는 쓰기 지연
변경 감지
지연 로딩
엔티티 조회, 1차 캐시
1차 캐시로 저장하고 db에 저장한다.
어느 시점에? 트랜잭션
데이터베이스에서 조회
단, 한 트랜잭션안에서만 동작하기 때문에 큰 이점은 없다. 즉, 트랜잭션이 끝나면 휘발성으로 날라간다. 우리가 아는 캐싱을 적용하려면 2차캐싱을 적용해야한다.
영속 엔티티의 동일성 보장
1차 캐시로 반복 가능한 읽기(Repeatable read) 등급의 트랜잭션 격리 수준을 데이터베이스가 아닌 애플리케이션 차원에서 제공
엔티티 등록 트랜잭션을 지원하는 쓰기 지연
1차 캐시에 저장과 동시에 INSERT SQL 생성하여 쓰기 지연 SQL 저장소에 저장한다.
그리고 transactio.commit();을 만나면 flush가 되면서 db에 날라가고 commit이 된다.
jpa batch 라는 것으로 size를 관리한다.
약간 bulk insert 같은 느낌으로 버퍼를 모으는 느낌
★엔티티 수정 변경 감지(Drity Checking)★
EntityManager em = emf.createENtityManager();
EntityTransaction tr = em.getTransaction();
tr.begin(); //트랜잭션 시작
//영속 엔티티 조회
Member memberA = em.find(Member.class, "memberA");
//영속 엔티티 데이터 수정
MemberA.setUserName("hi");
MemberA.setAge(10);
//em.update(member) 이런 코드가 있어야 하지 않을까?
tr.commit(); //트랜잭션 커밋
위의 코드를 보면 memberA라는 객체에 setName, setAge를 해주고 update 쿼리를 해주지 않았는데도 자동으로 update가 된다. 왜그럴까? 뭔가 set을 해주고 persist를 해줘야 반영이 될 것 같은데 말이다.
1차 캐시안에는 @Id, Entity, 스냅샷이라는 것이 있다. 스냅샷은 최초로 영속성 컨텍스트에 들어온 값을 임시 저장하는 것이다. 그러고 Entity(새로 들어온 값) 스냅샷과 변경이 감지되면 update 쿼리를 쓰기 지연 SQL 저장소에 저장해버리고 DB에 반영한다.
플러시
영속성 컨텍스트의 변경내용을 데이터베이스에 반영
플러시 발생
변경 감지
수정된 엔티티 쓰기 지연 SQL 저장소에 등록
쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송
등록, 수정, 삭제 쿼리
영속성 컨텍스트를 플러시 하는 방법
em.flush() - 직접 호출 트랜잭션 커밋 전에 강제 느낌 (거의 사용x)
트랜잭션 커밋 - 플러시 자동 호출
JPQL 쿼리 실행 - 플러시 자동 호출
em.persist(memberA);
em.persist(memberB);
em.persist(memberC);
// 중간에 JPQL 실행
query = em.createQuery("select m from Member m", member.class);
List<Member> members = query.getResultList();
em.persist의 memberA,B,C는 아직 데이터베이스에 Insert 전이다.
따라서 select 문에서 조회가 안될 것 같지만, JPQL은 flush가 자동으로 된다. 그래서 조회가 된다.
flush 여부 설정 가능
FlushModeType.AUTO... or COMMIT
준영속 상태
영속 -> 준영속
영속 상태의 엔티티가 영속성 컨텍스트에서 분리(detached)
영속성 컨텍스트가 제공하는 기능을 사용 못함
거의 비영속 상태에 가깝다.
영속성 컨텍스트가 관리하지 않으므로 1차 캐시, 쓰기 지연, 변경 감지, 지연 로딩을 포함한 영속성 컨텍스트가 제공하는 어떤한 기능도 동작하지 않는다.
식별자 값을 가지고 있다.
비영속 상태는 식별자 값이 없을 수도 있지만 준영속 상태는 이미 한 번 영속상태였으므로 반드시 식별자 값을 가지고 있다
지연 로딩을 할 수 없다.
//1 : 떼어내기
em.detach(member);
tx.commit();//commit을 해도 em은 반영되지 않는다.
//2 1차 캐시를 조회함 그래서 같은 내용 또 조회해도 select 쿼리가 또 나감
em.clear();
//3. em.close() : 종료
REST의 uniform interface를 지원하는 것은 쉽지 않기 때문에, 많은 서비스가 REST에서 바라는 것을 모두 지원하지 않고 API를 만들게 된다. REST API의 모든 스타일을 구현하지 못할 경우에는 Web API 혹은 Http API라고 부른다.
Web API 디자인 가이드
- URI는 정보의 자원을 표현해야 한다.
- 자원에 대한 행위는 HTTP Method(GET, POST, PUT, DELETE)로 표현한다.
웹 API의 이점
Web API는 분산 시스템에서 서비스를 제공하는 조직에 도움이 됩니다.다음은 웹 API의 몇 가지 이점입니다.
비즈니스:Web API는 오픈 소스이므로 일관된 비즈니스 데이터를 유지하기 위해 논리 중앙 집중화에 대한 복잡성을 줄입니다.저대역폭 데이터(JSON/XML)는 구문 분석이 쉽고 가벼우며 이상적인 데이터 교환 형식이므로 모든 언어와 통합할 수 있습니다.또한 Web API는 ASP.NET 프레임워크의 필수적인 부분이므로 유지 관리 및 이해가 매우 간단합니다.
기술:Web API의 주요 기술 이점 중 하나는 복잡한 구성이 필요하지 않다는 것입니다. 경량 아키텍처이기 때문에 대역폭이 제한된 장치(스마트폰)에 이상적입니다.OData(공개 데이터), 라우팅, 모델 바인딩 및 MVC와 유사한 유효성 검사를 지원합니다.
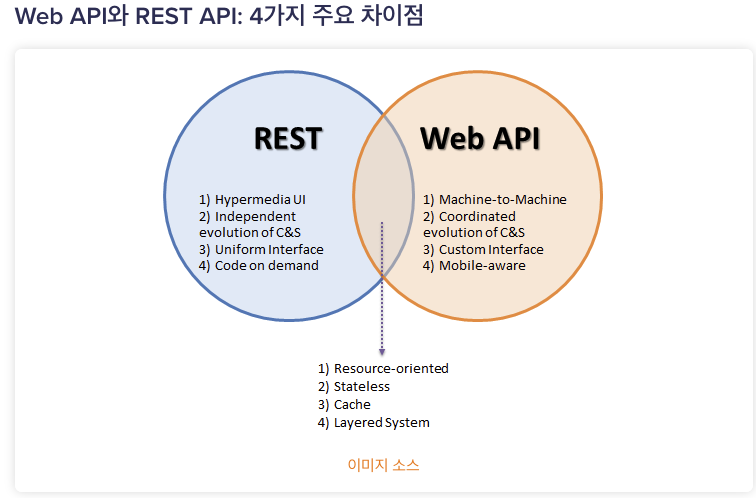
Web API와 REST API의 4가지 주요 차이점
1) 웹 API 대 REST API: 프로토콜
Web API는 서비스가 웹을 통해 다양한 클라이언트에 도달할 수 있도록 하는 HTTP/s 프로토콜 및 URL 요청/응답 헤더에 대한 프로토콜을 지원합니다.반면 REST API의 모든 통신은 HTTP 프로토콜을 통해서만 지원됩니다.
2) 웹 API 대 REST API: 형식
API는 동일한 작업을 수행하지만 Web API는 모든 통신 스타일에 유연성을 제공합니다.REST API는 통신을 위해REST, SOAP 및 XML-RPC를 사용할 수 있습니다.
3) 웹 API 대 REST API: 디자인
Web API는 경량 아키텍처이므로 스마트폰과 같은 장치에 제한된 가제트용으로 설계되었습니다.이와 대조적으로 REST API는 시스템을 통해 데이터를 송수신하여 복잡한 아키텍처를 만듭니다.
4) 웹 API 대 REST API: 지원
Web API는 IIS(인터넷 정보 서비스)또는 XML 및 JSON 요청을 지원하는 자체에서만 호스팅될 수 있습니다 .대조적으로 REST API는 표준화된 XML 요청을 지원하는 IIS에서만 호스팅될 수 있습니다.
성능 향상을 위해서 Batch Insert를 도입하는 과정 중 JPA, Mysql 환경에서의 Batch Insert에 대한 방법과 제약사항들에 대해서 정리했습니다. 결과적으로는 다른 프레임워크를 도입해서 해결했으며 본 포스팅은 JPA Batch Insert의 정리와, 왜 다른 프레임워크를 도입을 했는지에 대해한 내용입니다.
Batch Insert 란 ?
# 단건 insert
insert into payment_back (amount, order_id) values (?, ?)
# 멀티 insert
insert into payment_back (amount, order_id)
values
(1, 2),
(1, 2),
(1, 2),
(1, 2)
insert rows 여러 개 연결해서 한 번에 입력하는 것을 Batch Insert라고 말합니다. 당연한 이야기이지만 Batch Insert는 하나의 트랜잭션으로 묶이게 됩니다.
Batch Insert With JPA
위 Batch Insert SQL이 간단해 보이지만 실제 로직으로 작성하려면 코드가 복잡해지고 실수하기 좋은 포인트들이 있어 유지 보수하기 어려운 코드가 되기 쉽습니다. 해당 포인트들은 아래 주석으로 작성했습니다.JPA를 사용하면 이러한 문제들을 정말 쉽게 해결이 가능합니다.
// 문자열로 기반으로 SQL을 관리하기 때문에 변경 및 유지 보수에 좋지 않음
val sql = "insert into payment_back (id, amount, order_id) values (?, ?, ?)"
val statement = connection.prepareStatement(sql)!!
fun addBatch(payment: Payment) = statement.apply {
// code 바인딩 순서에 따라 오동작 가능성이 높음
// 매번 자료형을 지정해서 값을 입력해야 함
this.setLong(1, payment.id!!)
this.setBigDecimal(2, payment.amount)
this.setLong(3, payment.orderId)
this.addBatch()
}
// connection & statement 객체를 직접 close 진행, 하지 않을 경우 문제 발생 가능성이 있음
fun close() {
if (statement.isClosed.not())
statement.close()
}
쓰기 지연 SQL 지원 이란 ?
EntityMaanger em = emf.createEnttiyManager();
ENtityTranscation transaction = em.getTransaction();
// 엔티티 매니저는 데이터 변경 시 트랜잭션을 시작해야 한다.
transaction.begin();
em.persist(memberA);
em.persist(memberB);
// 여기까지 Insert SQL을 데이터베이스에 보내지 않는다.
// Commit을 하는 순간 데이터베이스에 Insert SQL을 보낸다
transaction.commit();
엔티티 매니저는 트랜잭션을 커밋 하기 직전까지 데이터베이스에 엔티티를 저장하지 않고 내부 쿼리 저장소에 INSERT SQL을 모아둔다. 그리고 트랜잭션을 커밋 할 때 모아둔 쿼리를 데이터베이스에 보내는데 이것을 트랜잭션을 지원하는 쓰기 지연이라 한다.
회원 A를 영속화했다. 영속성 컨텍스트는 1차 캐시에 회원 엔티티를 저장하면서 동시에 회원 엔티티 정보로 등록 쿼리를 만든다. 그리고 만들어진 등록 쿼리를 쓰기 지연 SQL 저장소에 보관한다.
다음으로 회원 B를 영속화했다. 마찬가지로 회원 엔티티 정보로 등록 쿼리를 생성해서 쓰지 지연 SQL 저장소에 보관한다. 현재 쓰기 지연 SQL 저장소에는 등록 쿼리가 2건이 저장되어 있다.
마지막으로 트랜잭션을 커밋 했다. 트랜잭션을 커밋 하면 엔티티 매니저는 우선 영속성 컨텍스트를 플러시 한다. 플러시는 영속성 컨텍스트의 변경 내용을 데이터베이스에 동기화하는 작업인데 이때 등록, 수정, 삭제한 엔티티를 데이터베이스에 반영한다.이러한 부분은 JPA 내부적으로 이루어지기 때문에 사용하는 코드에서는 코드의 변경 없이 이러한 작업들이 가능하다.
addBatch 구분을 사용하기 위해서는rewriteBatchedStatements=true속성을 지정해야 합니다. 기본 설정은false이며, 해당 설정이 없으면 Batch Insert는 동작하지 않습니다. 정확한 내용은 공식 문서를 참고해 주세요.
MySQL Connector/J 8.0 Developer Guide : 6.3.13 Performance Extensions Stops checking if every INSERT statement contains the “ON DUPLICATE KEY UPDATE” clause. As a side effect, obtaining the statement’s generated keys information will return a list where normally it wouldn’t. Also be aware that, in this case, the list of generated keys returned may not be accurate. The effect of this property is canceled if set simultaneously with ‘rewriteBatchedStatements=true’.
hibernate.jdbc.batch_size: 50Batch Insert의 size를 지정합니다. 해당 크기에 따라서 한 번에 insert 되는 rows가 결정됩니다. 자세한 내용은 아래에서 설명드리겠습니다.
@Entity
@Table(name = "payment_back")
class PaymentBackJpa(
@Column(name = "amount", nullable = false)
var amount: BigDecimal,
@Column(name = "order_id", nullable = false, updatable = false)
val orderId: Long
){
@Id
@Column(name = "id", updatable = false) // @GeneratedValue를 지정하지 않았음
var id: Long? = null
}
interface PaymentBackJpaRepository: JpaRepository<PaymentBackJpa, Long>
엔티티 클래스는 간단합니다. 중요한 부분은@GeneratedValue을 지정하지 않은 부분입니다.
@SpringBootTest
@TestConstructor(autowireMode = TestConstructor.AutowireMode.ALL)
internal class BulkInsertJobConfigurationTest(
private val paymentBackJpaRepository: PaymentBackJpaRepository
) {
@Test
internal fun `jpa 기반 bulk insert`() {
(1..100).map {
PaymentBackJpa(
amount = it.toBigDecimal(),
orderId = it.toLong()
)
.apply {
this.id = it.toLong() // ID를 직접 지정
}
}.also {
paymentBackJpaRepository.saveAll(it)
}
}
}
paymentBackJpaRepository.saveAll()를 이용해서 batch inset를 진행합니다. JPA 기반으로 Batch Insert를 진행할 때 별다른 코드가 필요 없습니다. 컬렉션 객체를saveAll()으로 저장하는 것이 전부입니다.hibernate.show_sql: true으로 로킹 결고를 확인해보겠습니다.
로그상으로는 Batch Insert가 진행되지 않은 것처럼 보입니다. 결론부터 말씀드리면 실제로는 Batch Insert가 진행됐지만hibernate.show_sql: true기반 로그에는 제대로 표시가 되지 않습니다. Mysql의 실제 로그로 확인해보겠습니다.
show variables like 'general_log%'; # general_log 획인
set global general_log = 'ON'; # `OFF` 경우 `ON` 으로 변경
해당 로그 설정은 성능에 지장을 줄 수 있기 때문에 테스트, 개발 환경에서만 지정하는 것을 권장합니다.해당 기능은 실시간으로 변경 가능하기 때문에 설정 완료 이후/var/lib/mysql/0a651fe44d20.log파일에 로그를 확인할 수 있습니다.
실제 mysql 로그에서는 Batch Insert를 확인할 수 있습니다. 그런데 왜 2번에 걸쳐서 Batch Insert가 진행되었을까요?hibernate.jdbc.batch_size: 50설정으로 Batch Insert에 대한 size를 50으로 지정했기 때문에 rows 100를 저장할 때 2번에 걸쳐 insert를 진행하는 것입니다.만약hibernate.jdbc.batch_size: 100이라면 1번의 insert로 저장됩니다.
위 쿼리는hibernate.jdbc.batch_size: 100으로 지정한 결과입니다. 그렇다면 왜batch_size옵션을 주어서 한 번에 insert 할 수 있는 데이터의 크기를 제한하는 것일까요? 아래 코드에서 해답을 찾을 수 있습니다.
When you make new objects persistent, employ methods flush() and clear() to the session regularly, to control the size of the first-level cache.
하이버네이트 공식 가이드의 내용입니다.batchSize값을 기준으로flush();,clear();를 이용해서 영속성 컨텍스트를 초기화 작업을 진행하고 있습니다.batchSize에 대한 제한이 없으면 영속성 컨텍스트에 모든 엔티티가 올라가기 때문에OutOfMemoryException발생할 수 있고, 메모리 관리 측면에서도 효율적이지 않기 때문입니다. 하이버네이트의 공식 가이드에서도 해당 부분의 언급이 있습니다.
Hibernate caches all the newly inserted Customer instances in the session-level cache, so, when the transaction ends, 100 000 entities are managed by the persistence context. If the maximum memory allocated to the JVM is rather low, this example could fail with an OutOfMemoryException. The Java 1.8 JVM allocated either 1/4 of available RAM or 1Gb, which can easily accommodate 100 000 objects on the heap.
long-running transactions can deplete a connection pool so other transactions don’t get a chance to proceed
JDBC batching is not enabled by default, so every insert statement requires a database roundtrip. To enable JDBC batching, set the hibernate.jdbc.batch_size property to an integer between 10 and 50.
쓰기 지연 SQL 제약 사항
batchSize: 50경우PaymentBackJpa객체를 50 단위로 Batch Insert 쿼리가 실행되지만, 중간에 다른 엔티티를 저장하는 경우 아래처럼 지금까지의PaymentBackJpa에 대한 지정하기 때문에 최종적으로batchSize: 50단위로 저장되지 않습니다.
em.persist(new PaymentBackJpa()); // 1
em.persist(new PaymentBackJpa()); // 2
em.persist(new PaymentBackJpa()); // 3
em.persist(new PaymentBackJpa()); // 4
em.persist(new Orders()); // 1-1, 다른 SQL이 추가 되었기 때문에 SQL 배치를 다시 시작 해야 한다.
em.persist(new PaymentBackJpa()); // 1
em.persist(new PaymentBackJpa()); // 2
이러한 문제는hibernate.order_updates: true,hibernate.order_inserts: true값으로 해결 할 수 있습니다.
JPA Batch Insert의 가장 큰 문제…
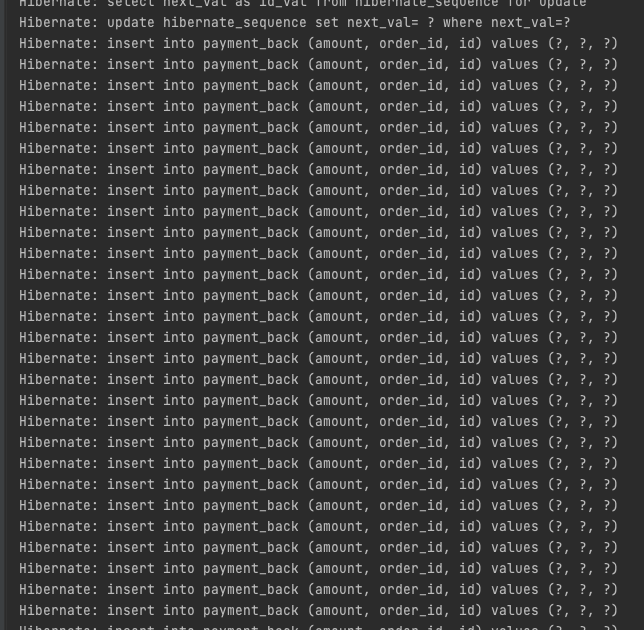
위에서 설명했던 부분들은 Batch Insert에 필요한 properties 설정, 그리고 내부적으로 JPA에서 Batch Insert에 대한 동작 방식을 설명한 것입니다.실제 Batch Insert를 진행하는 코드는 별다른 부분이 없고 컬렉션 객체를saveAll()메서드로 호출하는 것이 전부입니다.이로써 JPA는 Batch Insert를 강력하게 지원해 주고 있습니다.하지만 가장 큰 문제가 있습니다.@GeneratedValue(strategy = GenerationType.IDENTITY)방식의 경우 Batch Insert를 지원하지 않습니다.
Hibernate disables insert batching at the JDBC level transparently if you use an identity identifier generator.
공식 문서에도 언급이 있듯이@GeneratedValue(strategy = GenerationType.IDENTITY)경우 Batch Insert를 지원하지 않습니다. 정확히 어떤 이유 때문인지에 대해서는 언급이 없고, 관련 내용을 잘 설명한StackOverflow를 첨부합니다.
제가 이해한 바로는 하이버네이트는Transactional Write Behind방식(마지막까지 영속성 컨텍스트에서 데이터를 가지고 있어 플러시를 연기하는 방식)을 사용하기 때문에GenerationType.IDENTITY방식의 경우 JDBC Batch Insert를 비활성화함.GenerationType.IDENTITY방식이란auto_increment으로 PK 값을 자동으로 증분 해서 생성하는 것으로 매우 효율적으로 관리할 수 있다.(heavyweight transactional course-grain locks 보다 효율적). 하지만 Insert를 실행하기 전까지는 ID에 할당된 값을 알 수 없기 때문에Transactional Write Behind을 할 수 없고 결과적으로 Batch Insert를 진행할 수 없다.
Mysql에서는 대부분GenerationType.IDENTITY으로 사용하기 때문에 해당 문제는 치명적입니다. 우선GenerationType.IDENTITY으로 지정하고 다시 테스트 코드를 돌려 보겠습니다.
@Entity
@Table(name = "payment_back")
class PaymentBackJpa(
@Column(name = "amount", nullable = false)
var amount: BigDecimal,
@Column(name = "order_id", nullable = false, updatable = false)
val orderId: Long
){
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) // GenerationType.IDENTITY 지정
var id: Long? = null
}
internal class BulkInsertJobConfigurationTest(
private val paymentBackJpaRepository: PaymentBackJpaRepository
) {
@Test
internal fun `jpa 기반 bulk insert`() {
(1..100).map {
PaymentBackJpa(
amount = it.toBigDecimal(),
orderId = it.toLong()
)
.apply {
// this.id = it.toLong() // ID를 자동 증가로 변경 했기 때문에 코드 주석
}
}.also {
paymentBackJpaRepository.saveAll(it)
}
}
}
Query insert into payment_back (amount, order_id) values (1, 1)
Query insert into payment_back (amount, order_id) values (2, 2)
Query insert into payment_back (amount, order_id) values (3, 3)
Query insert into payment_back (amount, order_id) values (4, 4)
Query insert into payment_back (amount, order_id) values (5, 5)
Query insert into payment_back (amount, order_id) values (6, 6)
Query insert into payment_back (amount, order_id) values (7, 7)
Query insert into payment_back (amount, order_id) values (8, 8)
Query insert into payment_back (amount, order_id) values (9, 9)
Query insert into payment_back (amount, order_id) values (10, 10)
Query insert into payment_back (amount, order_id) values (11, 11)
Query insert into payment_back (amount, order_id) values (12, 12)
...
GenerationType.IDENTITY의 경우에는 Batch Insert가 진행되지 않습니다.그래서 다른 대안을 찾아야 했습니다. 이 부분부터는 다음 포스팅에서 이어가겠습니다.