목차
Simple Spring Memcached(SSM)
스프링에서 Memcache를 사용하려면 SSM 라이브러리를 자주 이용한다. SSM 어노테이션으로 메서드에 선언하면 쉽게 관련 데이터가 캐시에 관리된다. 스프링에서도 3.1버전부터는 캐시 서비스 추상화 기능이 지원되어 비즈니스 로직 변경 없이 쉽게 다양한 캐시 구현체(ex. Ehcache, Redis)로 교체가 가능하게 되었다.
Simple Spring Memcached(SSM) 설정 및 사용법
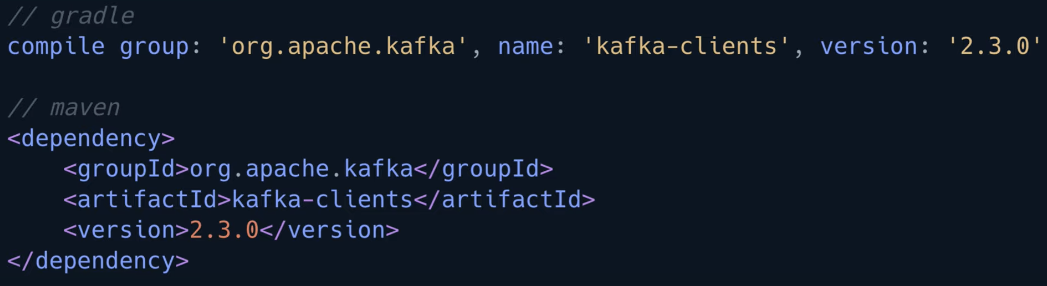
Maven dependency 추가
- spymemcached
- 단순 비동기, 단일 쓰레드 memcached 자바 라이브러리
- xmemcached (주로 사용됨)
- 고성능 멀티 쓰레드 memcached 자바 라이브러리
스프링 설정 파일
추가 설명
스프링 빈 설정에 Memcached 관련 설정이 포함된다. Memcached의 서버 정보와 캐시 설정은 ConsistentHashing 방식으로 지정되어 있다.
아래의 코드는 재직중인 회사에서 추가한 스프링 설정 파일 내용이다.
<property name="cacheClientFactory">
<bean class="com.google.code.ssm.providers.xmemcached.MemcacheClientFactoryImpl" />
</property>SSM Cache 대표 어노테이션
- Read
- @ReadThroughAssignCache
- @ReadThroughSingleCache
- @ReadThroughMultiCache
- Update
- @UpdateAssignCache
- @UpdateSingleCache
- @UpdateMultiCache
- Invalidate
- @InvalidateAssignCache
- @InvalidateSingleCache
- @InvalidateMultiCache
- Counter
- @ReadCounterFromCache
- @IncrementCounterInCache
- @DecrementCounterInCache
|
Cache Action
|
Description
|
|
ReadThrough
|
Cache에 저장된 key가 없는 경우 Cache에 저장한다
|
|
Update
|
Cache에 저장된 key의 값을 업데이트한다
|
|
Invalidate
|
Cache에 저장된 key를 삭제한다
|
|
Cache Type
|
Description
|
|
AssignCache
|
캐시 키는 assignedKey 속성으로 지정한 값이고 메서드 인자가 없는 경우에 사용된다
ex. List<Person> getAllUsers()와 같은 메서드에 사용된다
|
|
SingleCache
|
캐시 키는 SSM 어노테이션으로 선언된 메서드 인자로 생성되며 인자가 하나인 경우에 사용된다.
- 인자가 List 타입인 경우에는 캐시 키로 생성해서 사용할 수 없다
ex. Person getUser(int int)
|
|
MultiCache
|
캐시 키는 SSM 어노테이션으로 선언된 메서드 여러 인자로 생성된다. 인자중에 한개가 List 타입 형이여야하며 반환결과도 List 타입이여야 한다. 반환된 결과 List의 각 요소는 지정된 캐시 키로 저장된다.
ex. List<Person> getUserFromData(List workInfo)
|
- 기타 어노테이션 및 속성
- @CacheName(“QuoteApp”) : 관련 캐시를 하나로 묶을 수 있는 개념이고 클래스외에도 메서드에도 선언할 수 있다
- @CacheKeyMethod : 캐시의 key 값으로 이용할 메서드를 선언한다
- 캐시 key는 @CacheKeyMethod로 선언된 메서드가 사용된다
- @CacheKeyMethod가 지정되지 않은 경우에는 Object.toString() 메서드가 사용된다
- @ParameterValueKeyProvider : 메서드 인자에 적용되며 @CacheKeyMethod로 선언된 메서드나 toString()을 이용해서 key 값을 구한다
- @ParameterDataUpdateContent : 메서드 인자에 어노테이션이 적용되며 새로 저장할 값을 지정한다
- @ReturnDataUpdateContent : 반환 값을 캐시에 저장한다
- 속성
- namespace : 동일한 키 값의 이름이 있을 경우를 방지하기 위해서 사용된다
- expiration : key값이 만료되는 시간 (초 단위)이다
- assignedKey : 캐시 저장시 사용되는 키 값이다
Read Cache 예시
@ReadThroughAssignCache
@ReadThroughAssignCache 어노테이션은 인자가 없는 메서드에 적용할 수 있습니다. 캐시 영역에서 네임스페이스 'area' 이름으로 key:value(all:List<Product>)가 저장돕니다.....
@ReadThroughAssignCache(namespace = "area", assignedKey="all")
public List<Product> findAllProducts() {
slowly(); // 고의로 지연시킴
List<Product> productList = new ArrayList<>();
return storage.values().stream().collect(Collectors.toList());
}실무에서 사용
@ReadThroughSingleCache(namespace = "intraCs", expiration = 60 * 60)
@CacheConnectingKey("PartnerQnaCategoryCacheService.getPartnerQnaCategoryTreeList")
public List<PartnerQnaCategoryTree> getPartnerQnaCategoryTreeList(@ParameterValueKeyProvider String serviceCode){
...
}Unit Test
@Test
public void testReadThroughAssignCache() {
this.executeWithMemcachedFlush(productService, () -> {
productService.addProduct(new Product("microsoft", 100));
productService.addProduct(new Product("sony", 100));
productService.findAllProducts(); //#1 - caching
productService.findAllProducts(); //#2 - cache에서 가져옴
});
}@ReadThroughSingleCache
@ReadThroughSingleCache 어노테이션은 인자가 하나인 경우에만 사용한다. 인자에 @ParameterValueKeyProvider 어노테이션을 선언하면 @CacheKeyMethod로 지정된 메서드는 캐시 키를 생성하는데 사용되고 없는 경우에는 toString() 메서드가 사용됩니다.
@ReadThroughSingleCache(namespace = "area")
public Product findProduct(@ParameterValueKeyProvider String name) {
slowly(); // 고의로 지연시킴
return storage.get(name);
}
@CacheKeyMethod
public String getName() {
return name;
}실무
@ReadThroughSingleCache(namespace = "intraCs", expiration = 60 * 60)
@CacheConnectingKey("PartnerQnaCategoryCacheService.getPartnerQnaCategoryRootPathMap")
public Map<Long, List<PartnerQnaCategory>> getPartnerQnaCategoryRootPathMap(@ParameterValueKeyProvider String serviceCode){
...
}Unit Test
@Test
public void testReadThroughSingleCache() {
this.executeWithMemcachedFlush(productService, () -> {
productService.addProduct(new Product("microsoft", 100));
productService.addProduct(new Product("sony", 100));
productService.findProduct("microsoft”); //#1 - caching
productService.findProduct(("microsoft”); //#2 - cache에서 가져옴
});
}}@ReadThroughMultiCache
MultiCache는 메서드 인자 중에 List 타입인 인자가 있어야 합니다. 그리고 캐시되는 key:value 인자의 요소와 반환 결과 요소가 각각 key:value로 캐시에 저장된다.
@ReadThroughMultiCache(namespace = "area")
public List<Integer> getIncrementValue(@ParameterValueKeyProvider List<Integer> nums, int incrementValue) {
slowly(); // 고의로 지연시킴
return nums.stream().map(x -> x + incrementValue).collect(Collectors.toList());
}실무
@ReadThroughMultiCache(namespace = "intraCs", expiration = 60 * 60)
public List<OpenMarketDealInfo> getOpenMarketDealInfo(@ParameterValueKeyProvider List<String> mainDealSrlList) {
...
}Unit Test
@Test
public void testReadThroughMultiCache() {
this.executeWithMemcachedFlush(productService, () -> {
List<Integer> nums = new ArrayList<Integer>(Arrays.asList(2, 3, 4, 5));
productService.getIncrementValue(nums, 4); //#1 - caching 함
productService.getIncrementValue(nums, 1); //#2 - caching된 값을 가져옴
});
}Update Cache
Update로 시작하는 어노테이션은 캐시에 저장된 값을 강제적으로 덮어쓰는 어노테이션이다. Update에 대한 여러 어노테이션에 대해서 알아보자.
@UpdateAssignCache
AssignCache 어노테이션은 assignedKey로 지정된 값을 키로 사용한다.
@ReturnDataUpdateContent
@UpdateAssignCache(namespace = "area", assignedKey = "all")
public List<Product> resetPriceForAllProducts() {
slowly(); // 고의로 지연시킴
return storage.values().stream()
.map(product -> {
product.setPrice(0);
return product;
}).collect(Collectors.toList());
}
참고
https://advenoh.tistory.com/27#recentComments
'Back-end > cache' 카테고리의 다른 글
| Redis vs Memcached (0) | 2022.04.06 |
|---|---|
| [Server] Cache(캐시) (0) | 2021.12.10 |