새로운 1차원 배열을 arr이라 할 때, arr[left], arr[left+1], …, arr[right]만 남기고 나머지는 지웁니다.
문제 풀이 1. 말이 어렵지만 위의 시뮬레이션처럼 구현하게 되어있음. 해당 시뮬레이션의 각 좌표는 max(r,c)+1 임 2. 평탄화 했을 시 각 행렬은 i/n, i%n으로 나타낼 수 있음.
소스코드
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
vector<int> solution(int n, long long left, long long right) {
vector<int> answer;
for(long long i = left ; i<=right ; i++){
answer.push_back(max(i/n,i%n)+1);
}
return answer;
}
문제설명 1차 캐시
캐시 교체 알고리즘은 LRU(Least Recently Used)를 사용한다. cache hit일 경우 실행시간은 1이다. cache miss일 경우 실행시간은 5이다.
LRU(Least Recently Used) 알고리즘
cache size
naver.com(아이디/비번)
daum.com(아이디/비번)
tmon.com(아이디/비번)
kakao.com(아이디/비번)
line.com(아이디/비번)
시도) 네이버 로그인
캐시 메모리에 있을 경우
cache size
daum.com(아이디/비번)
tmon.com(아이디/비번)
kakao.com(아이디/비번)
line.com(아이디/비번)
naver.com(아이디/비번)
시도) aaa.com 시도
캐시 메모리에 없을 경우
cache size
daum.com(아이디/비번)
tmon.com(아이디/비번)
kakao.com(아이디/비번)
line.com(아이디/비번)
aaa.com(아이디/비번)
캐시 교체 알고리즘은 LRU(Least Recently Used)를 사용한다.cache hit일 경우 실행시간은 1이다.cache miss일 경우 실행시간은 5이다.1. 만약 cachSize가 0이면 전체 시티*5 2. 소문자로 모두 변경 3. 해당 값을 찾으면 해당 값을 지워주고 새로 추가해주며 answer++ 해준다. 4-1. 해당 값을 못찾았는데 cache가 여유있다. 그냥 pushBack, answer+5 4-2. 해당 값을 못찾았는데 cache가 없다. 맨 처음 값 삭제 후 pushBack, answer+5
소스코드
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
int solution(int cacheSize, vector<string> cities) {
int answer = 0;
if(cacheSize == 0){
answer = cities.size()*5;
return answer;
}
vector<string> cache;
for(int i =0; i<cities.size();i++){
string check = cities[i];
transform(check.begin(),check.end(),check.begin(),::tolower); //소문자 변환
auto it = find(cache.begin(), cache.end(), check);
//찾으면 it(이터레이터가 끝까지 안가면 해당 값을 찾은 것)
if(it != cache.end()){
cache.erase(it);
cache.push_back(check);
answer++;
}else{
//캐시에 빈자리 있음
if(cache.size() < cacheSize){
cache.push_back(check); //마지막에 넣어준다.
//캐시에 빈자리 없음
}else{
cache.erase(cache.begin()+0); // 젤 처음 지우고
cache.push_back(check); //마지막에 넣어준다.
}
answer+=5;
}
}
return answer;
}
1부터 n까지 번호가 붙어있는 n명의 사람이 영어 끝말잇기를 하고 있습니다. 영어 끝말잇기는 다음과 같은 규칙으로 진행됩니다. 그냥 끝말잇기임. 사람의 수 n과 사람들이 순서대로 말한 단어 words 가 매개변수로 주어질 때, 가장 먼저 탈락하는 사람의 번호와 그 사람이 자신의 몇 번째 차례에 탈락하는지를 구해서 return 하도록 solution 함수를 완성해주세요.
문제풀이 1. 맵 형식으로 구현 2. 처음부터 틀린 경우는 없으므로 tank부터 맵에 넣고 시작 3. 맵에 단어가 이미 있거나 뒷 단어의 맨앞 글자와 현재단어의 맨뒷 단어 비교 4. 리턴 방식 :
1. Why ? Global 이 아닌 LocalCache 사용했는가? 금칙어(욕설)데이터는 600여건이며 자주 변하지 않고(업데이트가 빈번하지 않음) 빈번하게 조회될 여지가 있다. 따라서 LocalCache를 사용하였다.
2. 캐시의 지속 시간 고려 LocalCache의 로컬 메모리는 크지 않다. 따라서 1시간으로 설정하였다.
//Service단 메서드에 적용
@Cacheable(value = LocalCacheConfig.CACHE_1_HOUR)
public List<String> getForbiddenWords(){
세부로직...
}
//Config 설정
Configuration cacheConfig = new Configuration();
cacheConfig.setName("__csservice");
CacheConfiguration config1hour = new CacheConfiguration();
config1hour.setName(CACHE_1_HOUR);
config1hour.setMemoryStoreEvictionPolicy("LRU"); //저장방법
config1hour.setMaxEntriesLocalHeap(1000); //최대 메모리크기
config1hour.setTimeToIdleSeconds(0);
config1hour.setTimeToLiveSeconds(60 * 60); //60초 * 60 = 1시간
cacheConfig.addCache(config1hour);
return CacheManager.newInstance(cacheConfig);
}
3. 캐시의 저장여부 확인 첫 번째 방법으론 Service단에서 log.info를 찍어보았다. 하지만 확실하지 않았다. cache관련된 함수를 호출하긴 하지만 이게 저장을 하는지 여부를 파악하기 힘들었다. 따라서 Thread를 주고 한 번더 호출한 후 로그를 비교했다. 더 확실하게 하기 위해서 Service단에 현재시간을 구하는 메서드를 만들고 @EnableCaching, @Cacheable, @CacheEvict 세가지를 테스트 해보았다.
4. 효과 캐싱처리가 없었다면 DB에 부하가 지속적으로 발생하곘지만, 캐싱처리를 함으로써 DB부하를 낮춤. 대부분 config처리가 xml로 처리하지만 class로 처리하는 방식을 택한 회사의 방침대로 진행. 또한 config는 해당 api에서만 사용하는 것이 아니라 범용성있게 사용가능하므로 변수명을 설정할 때 범용성있게 작성해야한다.
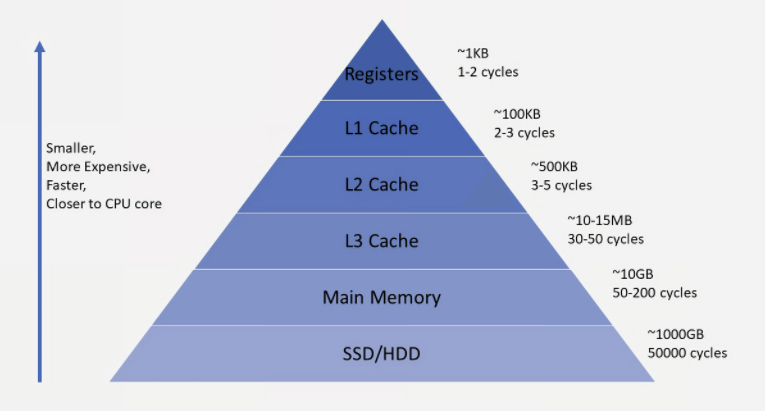
Chche Chche란 자주 사용하는 데이터나 값을 미리 복사해 놓는 임시장소를 가리킨다. 아래와 같은 저장공간 계층 구조에서 확인할 수 있듯이, 캐시는 저장 공간이 작고 비용이 비싼 대신 빠른 성능을 제공한다.
Chche를 고려하는 경우
접근 시간에 비해 원래 데이터를 접근하는 시간이 오래 걸리는 경우(서버의 균일한 API 데이터)
반복적으로 동일한 결과를 돌려주는 경우(이미지나 썸네일 등)
Chche에 데이터를 미리 복사해 놓으면 계산이나 접근 시간 없이 더 빠른 속도로 데이터에 접근 가능하다. 지속적으로 DBMS 혹은 서버에 요청하는 것이 아니라 Memory에 데이터를 저장하였다가 불러다 쓰는 것을 의미한다. DBMS의 부하를 줄이고 성능을 높이기 위해 캐시(Cache)를 사용한다. 원하는 데이터가 캐시에 존재할 경우 해당 데이터를 반환하며, 이러한 상황을 Cache hit라고한다. 반대로 캐시에 원하는 데이터가 없을 시 Cache Miss라고 한다.
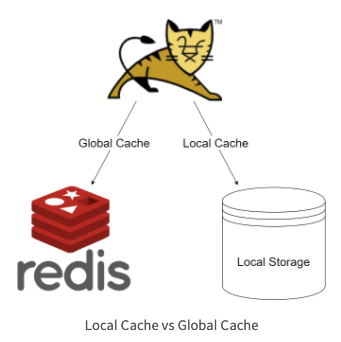
Local Cache vs Global Cache.
프링의 PSA 덕분에, 우리는 서비스 환경에 따라 어떤 Cache 전략이던 CacheManager를 구현하고 있기만 하다면 유연하게 우리 코드에 적용할 수 있습니다.
그럼 어떠한 Cache 기술을 적용할지 고려해보아야 되겠죠? Cache 관리 전략을 선택할 때 가장 먼저 고려해야 할 요소는, 캐시 데이터를 저장할 스토리지를 서버가 자체적으로 소유하고 있을지, 외부 서버에 캐시 저장소를 따로 둘 지에 대한 부분입니다. 캐시 저장소를 서버에 두는 방식을 Local Cache, 외부 캐시 저장소를 두는 방식을 Global Cache라고 합니다.
Local Cache
데이터 조회 오버헤드가 없다.
캐시 데이터를 서버 메모리상에 두는 것의 가장 큰 장점은, 무엇보다도 속도가 빠르다는 점입니다. 캐시를 외부 저장소에 저장하면 네트워크 통신을 통해 캐시 저장소에 접근하고, 데이터를 가져오는 과정 등의 오버헤드가 없기 때문에 Local Cache의 데이터 읽기 속도는 현저히 빠릅니다.
서버 간 데이터 일관성이 깨질 수 있다.
Local Cache는 단일 서버 인스턴스에 캐시 데이터를 저장하기 때문에, 서버의 인스턴스가 여러 개일 경우 서버 간 캐시 데이터가 일치하지 않아 신뢰성을 떨어뜨릴 수 있습니다.
금칙어 조회같은 경우 CS에서 특정부분에만 국한되어 사용되며 데이터의 추가, 변경, 삭제가 빈번하지 않다. 따라서 로컬캐시로 관리하는것이 좋다고 판단하여 사용하였다. 또한 금칙어 몇개가 전체 비즈니스에 영향을 크게 주지않는다. 무슨말이냐면 글로벌 캐싱으로 얻는 이점인 서버간 데이터 일관성에 예를들면 금칙어 몇개가 빠르게 동기화되어 일관성이 유지 안된다고하여 전체 비즈니스에 영향을 미치지 않는다 따라서 로컬 캐싱을 사용하였다. 무슨 금전이 오고 가는것도 아니니
Global Cache
네트워크 I/O 비용 발생
Global Cache는 외부 캐시 저장소에 접근하여 데이터를 가져오기 때문에, 이 과정에서 네트워크 I/O가 비용이 발생합니다. 하지만 서버 인스턴스가 추가될 때에도 동일한 비용만을 요구하기 때문에, 서버가 고도화될수록 더 높은 효율을 발휘합니다.
데이터 일관성을 유지할 수 있다.
Global Cache는 모든 서버의 인스턴스가 동일한 캐시 저장소에 접근하기 때문에, 데이터의 일관성을 보장할 수 있습니다. 데이터의일관성이깨지기쉬운분산서버환경에적합한구조입니다.
Local Cache vs GlobalCache, 어떤 기준으로 선택해야 할까?
Local Cache와 Global Cache의 특성을 고려했을 때, 어떤 기술을 선택해야 할지에 대한 기준은 "데이터의 일관성이 깨져도 비즈니스에 영향을 주지 않는가?"라고생각합니다.
이를테면, 사용자 정보가 변경되어 프로필에 반영되어야 하는 상황을 가정할 때, 서버 간 동기화가 맞지 않아서 프로필에 반영되는데 시간이 조금 걸린다 하더라도, 전체적인 서비스 운영에 큰 타격을 주지는 않습니다. 금전이 오고가는 문제도 아니고, 프로필의 정보가 조금 늦게 반영된다고 해서 큰 문제가 발생하지 않으니까요. 이러한 경우에는 서버간 동기화 없이서버 자체적으로 로컬 캐싱을 하는 것도 괜찮은 선택지라고 생각합니다.
하지만,상품 데이터를 캐싱한다고 했을 때는 상황이 달라집니다. 사용자가 가격을 변경했는데, 그것이 반영되지 않으면 서비스 신뢰를 심각하게 손상하고, 운이 나쁘면 법적 문제로 이어지기도 합니다. 따라서, 이러한 경우에는 동기화가 속도보다 더 중요하며, 그렇기에 동기화가 확실하게 보장되는 Global Cache를 사용하는 것이 좋습니다.
진행 중인 프로젝트에서는게시글과 댓글에 캐싱을 적용하였고, 둘 다 데이터의 일관성이 중요하다고 판단되어Global Cache인 Redis를 적용하였습니다. 추후 성능 테스트를 진행하면서, Local Cache를 적용해 성능을 향상할 수 있는 지점을 발견하면, CompositeCacheManager를 사용해 2차 캐시를 구성해보고, 관련한 내용을 새로 포스팅하도록 하겠습니다.
Local-Memory 캐시란?
스프링에서 제공하는 기본 Cache (SSM) spring 3.1버전부터 Spring Application에 캐시를 쉽게 추가할 수 있도록 기능을 제공한다. 유사 트랜잭션을 지원하고, 사용하고 있는 코드(메서드)에 영향을 최소하하면서 일관된 방법으로 캐시를 사용 할 수 있게 된다. Spring에서 캐시 추상화는 메소드를 통해 기능을 지원하는데, 메소드가 실행되는 시점에 파라미터에 대한 캐시 존재 여부를 판단하여 없으면 캐시를 등록하고, 캐시가 있으면 메소드를 실행시키지 않고 캐시 데이터를 Return 해주게 된다. Spring 캐시 추상화를 지원하기 때문에 개발자는 캐시 로직을 작성하지 않아도 된다. 하지만 캐시를 저장하는 저장소는 직접 설정을 해줘야 한다. Spring에서는 CacheManager라는 Interface를 제공하여 캐시를 구현하도록 되어있다.
CacheManager 캐시 저장소 Spring 에서는 CacheManager 라는 Interface를 제공하여 캐시를 구현하도록 하고 있다. 별다른 의존성을 추가하지 않을 시, Local-Memory에 저장이 가능한 ConcurrentMap 기반인 ConcurrentMapCacheManager가 Bean으로 자동 등록된다.
캐시 사용하기
캐시 설정 등록 @EnableCaching or @Configuration 등록
캐시 저장 @Cachealbe을 통해 캐시할 메서드를 지정한다. 키를 따로 설정하지 않으면 전체 파라미터가 키가 된다.
@Cacheable
value, cacheNames : 캐시이름
key : 같은 캐시명을 사용 할 때, 구분되는 구분 값(KeyGenerator와 함께 쓸 수 없음), 별도 지정이 없을 시 파라미터로 key를 지정.
keyGenerator: 특정 로직에 의해 cache key를 만들고자 하는 경우 사용. 4.0이후 버전부터 SimpleKeyGenerator를 사용. Custom Key Generrator를 사용하고 싶으면, KeyGenerrator 인터페이스를 별도로 구현
cacheManager : 사용할 CacheManager를 지정(EHCacheManger, RadisCacheManager등)
cacheResolver: Cache 키에 대한 결과값을 돌려주는 Resolver (Interceptor역할).
CacheResolver를 구현하여 Custom하게 처리 할 수도 있음
unless: 캐싱이 이루어지지 않는 조건을 설정. 연산 조건이 true 이면 경우에는 캐싱되지 않음. ex) id가 null아 아닌 경우에만 캐싱 (unless = "#id == null")
sync: 캐시 구현체가 Thread safe 하지 않는 경우, 자체적으로 캐시에 동기화를 거는 속성. default는 false
condition: SpEL 표현식을 통해 특정 조건에 부합하는 경우에만 캐시 사용. and, or 표현식등을 통해 복수 조건 사용가능. 연산 조건이 true인 경우에만 캐싱
Global 캐시 적용 과정
1. bulid, gradle or maven 등록
//gradle 등록 예시
implementation 'org.springframework.boot:spring-boot-starter-data-redis'
@RequiredArgsConstructor
/** @EnableCaching :해당 애플리케이션에서 캐싱을 이용하겠다는 명시를 처리해줘야 한다.
해당 어노테이션을 적용하게 되면 @Cacheable 라는 어노테이션이 적용된 메서드가 실행될 때 마다
AOP의 원리인 후처리 빈에 의해 해당 메소드에 프록시가 적용되어 캐시를 적용하는 부가기능이 추가되어 작동하게 된다.
*/
@EnableCaching
@Configuration
public class CacheConfig {
/** 이전에 Redis를 이용한 세션 스토리지 등록시 사용했던 Lettuce 기반의 Redis client를
Bean으로 등록하여사용하고 있다.
*/
private final RedisConnectionFactory redisConnectionFactory;
/**
CacheProperties : 캐싱이 적용되는 대상마다 캐시의 만료기간을 쉽게 변경할 수 있도록
yml(또는 properties) 파일에서 종류별로 만료 기간을 Map에 바인딩한다.
*/
private final CacheProperties cacheProperties;
private ObjectMapper objectMapper() {
ObjectMapper mapper = new ObjectMapper();
mapper.disable(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS);
mapper.registerModule(new JavaTimeModule());
mapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL, JsonTypeInfo.As.PROPERTY);
return mapper;
}
/**
RedisCacheConfiguration : redisCacheManager에 여러가지 옵션을 부여할 수 있는 오브젝트이다.
여기서는 캐시의 Key/Value를 직렬화-역직렬화 하는 Pair를 설정했다.
*/
private RedisCacheConfiguration redisCacheDefaultConfiguration() {
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration
.defaultCacheConfig()
.serializeKeysWith(RedisSerializationContext.SerializationPair
.fromSerializer(new StringRedisSerializer()))
.serializeValuesWith(RedisSerializationContext.SerializationPair
.fromSerializer(new GenericJackson2JsonRedisSerializer(objectMapper())));
return redisCacheConfiguration;
}
/**
CacheProperties에서 바인딩해서 가져온 캐시명과 TTL 값으로 RedisCacheConfiguration을 만들고
Map에 넣어 반환한다.
Map을 사용하는 이유는 캐시의 만료기간이 다른 여러개의 캐시매니저를 만들게 됨으로써 발생하는
성능저하를 방지하기 위해 하나의 캐시매니저에 Map을 이용하여 캐시 이름별 만료기간을 다르게 사용하기 위함이다.
*/
private Map<String, RedisCacheConfiguration> redisCacheConfigurationMap() {
Map<String, RedisCacheConfiguration> cacheConfigurations = new HashMap<>();
for (Entry<String, Long> cacheNameAndTimeout : cacheProperties.getTtl().entrySet()) {
cacheConfigurations
.put(cacheNameAndTimeout.getKey(), redisCacheDefaultConfiguration().entryTtl(
Duration.ofSeconds(cacheNameAndTimeout.getValue())));
}
return cacheConfigurations;
}
/**
캐시 매니저를 등록한다. 스프링에서 기본적으로 지원하는 캐시 저장소는 JDK의 ConcuurentHashMap이며
그 외 캐시 저장소를 사용하기 위해서는 캐시 매니저를 Bean으로 등록해서 사용해야 한다.
withInitialCacheConfigurations에 캐시의 종류별로 만료기간을 설정한 redisCacheConfigurationMap을
*/
@Bean
public CacheManager redisCacheManager() {
RedisCacheManager redisCacheManager = RedisCacheManager.RedisCacheManagerBuilder
.fromConnectionFactory(redisConnectionFactory)
.cacheDefaults(redisCacheDefaultConfiguration())
.withInitialCacheConfigurations(redisCacheConfigurationMap()).build();
return redisCacheManager;
}
}
3. @Cacheable 등록
//JPA 호출
@Cacheable(value = "product", key = "#id")
public ProductInfoResponse getProductInfo(Long id) {
return productRepository.findById(id).orElseThrow(() -> new ProductNotFoundException())
.toProductInfoResponse();
}
@Cacheable 동작 원리
@Cacheable은 AOP 기반으로 동작하며...어쩌구
쉽게 말해서 @Cacheable이 등록된 메서드는 DB에서 쿼리문을 날려 데이터를 가져오는 것이 아닌, 캐시 메모리에서 데이터를 반환하는 것이다.
캐시의 value값은 필수이며 key는 선택적이다.
만약 파라미터가 존재하지 않을 경우 key값은 0으로 처리된다. 왠만하면 key값을 명시적으로 사용하는 것을 권장한다.
호스트 내에는 1~65535번까지 6만개가 넘는 문이 존재한다. 그 문의 상태를 외부에선 알 수 없다.
하지만 잘 알려진(well-known)포트가 존재한다.
21번 포트 : FTP(RFC 114)
22번 포트 : SSH(RFC 4253)
23번 포트 : Telnet(RFC15, RFC854)
*RFC(Request For Comments) 인터넷 표준을 다루는 문서
웹 관련 기본 포트는 80과 443이다.
80 포트 : HTTP : http://tomcat.apache.org -> http://tomcat.apache.org:80과 같다.
443 포트 : HTTPS https://tomcat.apache.org -> https://tomcat.apache.org:443과 같다.
포트와 프로토콜
사용 포트
HTTP
- OSI7계층 중 Layer7(Application)이다.
HTTPS
HTTP+SSL(보안) - SSL은 OSI7계층 중 Layer5(session)이다.
AJP(Apache JServ Protocal)
- Application 서버로부터 오는 요청을 로드 밸런싱 해주는 바이너리 프로토콜이다.
ShutDown
mod_jk
- AJP 프로토콜을 사용하여 톰캣과 연동하기 위해 만들어진 모듈 - mod_jk는 톰캣의 일부로 배포되지만, 아파치 웹서버에 설치하여아한다.
동작방식 1. 아파치 웹서버의 httpd.conf에 톰캣 연동을 위한 설정을 추가하고, 톰캣에서 처리할 요청을 지정한다. 2. 사용자의 브라우저는 아파치 웹서버(포트80)에 접속을 요청한다. 3. 아파치 웹서버는 사용자의 요청이 톰캣에서 처리하도록 지정된 요청인지 확인 후, 톰캣에서 처리해야 하는 경우 아파치 웹서버는 톰캣의 AJP포트(보통 8009포트)에 접속해 요청을 전달한다. 4. 톰캣은 아파치 웹서버로부터 요청을 받아 처리한 후, 처리 결과를 아파치 웹서버에 되돌려 준다. 5. 아파치 웹서버는 톰캣으로부터 받은 처리 결과를 사용자에게 전송한다.
Apache와 Tomcat을 연동해야 하는 이유 Tomcat은 WAS 서버이지만 Web 서버의 기능도 갖추고 있는 WAS 서버이다. 정적인 페이지는 Apache가 처리하고, 동적인 페이지는 Tomcat이 처리함으로서 부하를 분산시킨다. 하지만 요새는 Tomcat 내의 Web 서버가 아파치에 절대 뒤쳐지지 않는다. 하지만 아파치에서만 사용할 수 있는 기능이 있다. 그래서 결론은 연동한다.
Artifact Maven등에서 빌드 결과로 나오는 개발 산출물을 주로 Artifact라고 합니다. 또한 Java외에 기타 다른 다양한 '산출물'을 Artifact라고 부르며, Delivery 및 Deploy를 위해 최종적으로 관리되는 산출물이라고 생각하면 된다. Artifact를 모아서 저장하는 공간을 Library 또는 Artifactory라고 한다.
Maven-war-plugin
Maven-war-plugin pom.xml의 dependency에 선언된 각종 라이브러리들과 Java class 파일 웹 어플리케이션의 각종 리소스들을 모아서 하나의 Web Application Archive 압축 파일로 만들어 줍니다.
war:war war 형태의 압축 파일로 빌드하는 명령입니다. 압출 파일은 WAS에 의해 압축이 풀리고 파일이 많은 경우에는 압축 해제 시간이 오래 걸릴 수 있습니다.
war:exploded war 압축 형태를 해체한 디렉토리 형태 구조로 빌드하는 명령입니다. 압축 및 해제 과정이 불필요하고 별도의 디렉토리에 원본 소스를 복사하여 만듭니다. 원본 소스를 건드리지 않고 배포를 원하는 경우에 적합합니다.
war:inplace target 디렉토리 뿐만 아니라 다른 디렉토리에 library와 class 파일들이 생성되도록 하는 명령입니다. 기본적으로 src/main/webapp이 지정되어 있습니다.
각각의 구조
SNAPSHOT이란?
SNAPSHOT 아직 릴리즈 되지 않은 버전을 뜻한다. 실제(릴리즈)버전과 스냅 샷 버전의 차이점은 스냅 샷에 업데이트가 있을 수 있다는 것이다. 즉, 1.0-SNAPSHOT 오늘 다운로드하면 어제 나 내일 다운로드하는 것과 다른 파일이 제공될 수 있다.
ex) foo-1.0.jar는 maven이 로컬 저장소에서 라이브러리를 찾으면 현재 빌드에 이 라이브러리를 사용합니다.(만약 안정적이지 않다면 setting.xml 또는 pom.xml)을 검색하여 종속성을 검색합니다. (안정적이지 않다 = foo-1.0.SNAPSHOT.jar와 같은 것을 의미한다.)