빨간 구슬과 파란 구슬의 각각의 이동거리를 계산하여 더 많이 이동한 쪽을 이전 위치 한 칸 돌려준다.
주요 메서드
매개변수
r : 현재 x좌표
c : 현재 y좌표
dist : 움직인 거리
d : 방향(4방향)
private static Move move (int r, int c, int dist, int d){
int rr =r, cc= c;
if (graph[rr+dx[d]][cc+dy[d]] != '#')
{
rr = rr + dx[d];
cc = cc + dy[d];
dist ++;
}
return new Move(rr,cc,dist);
}
빨간 구슬과 파란 구슬이 같은 칸에 있을 경우
// 빨간 구슬과 파란 구슬이 같은 칸에 있을 경우
if (nRed.r == nBlue.r && nRed.c == nBlue.c) {
// 빨간 구슬이 더 많이 이동했을 경우
if(nRed.dist> nBlue.dist) {
// 이전 위치로
nRed.r -= dx[d];
nRed.c -= dy[d];
} else {
nBlue.r -= dx[d];
nBlue.c -= dy[d];
}
}
bfs 로직
while(!q.isEmpty()) {
int size = q.size();
while(size-- > 0) {
Turn now = q.poll();
// 4방으로 장난감을 기울여보자.
for (int d = 0; d < 4; d++) {
// 빨간 구슬 이동
nRed = move(now.Rr, now.Rc, 0, d);
// 파랑 구슬 이동
nBlue = move(now.Br, now.Bc, 0, d);
// 빨간 구슬과 파란 구슬이 동시에 구멍에 빠져도 실패
if(graph[nBlue.r][nBlue.c] == 'O') continue;
// 빨간 구슬만 구멍에 빠질 경우
if(graph[nRed.r][nRed.c] == 'O') {
return 1;
}
// 빨간 구슬과 파란 구슬이 같은 칸에 있을 경우
if (nRed.r == nBlue.r && nRed.c == nBlue.c) {
// 빨간 구슬이 더 많이 이동했을 경우
if(nRed.dist> nBlue.dist) {
// 이전 위치로
nRed.r -= dx[d];
nRed.c -= dy[d];
} else {
nBlue.r -= dx[d];
nBlue.c -= dy[d];
}
}
// 이미 시도해봤던 상태라면 pass
if(visit[nRed.r][nRed.c][nBlue.r][nBlue.c]) continue;
visit[nRed.r][nRed.c][nBlue.r][nBlue.c] = true;
// Queue에 추가
q.add(new Turn(nRed.r, nRed.c, nBlue.r, nBlue.c));
}
}
// 10번 이하로 성공할 수 없다면
if(++time > 10) return 0;
}
return 0;
}
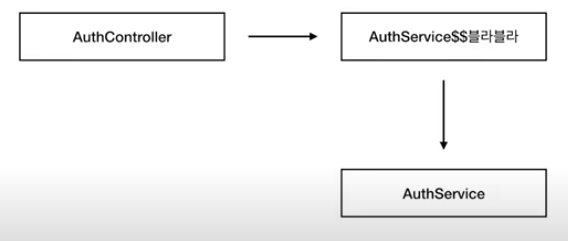
@Service
public class BugService {
private BugRepository bugRepository;
@Autowired
public BugService(BugRepository bugRepository){
this.bugRepository = bugRepository;
}
}
Field 변수를 이용한 방법
장점
간단하다.
단점
의존 관계가 눈에 잘 보이지 않아 추상적이고, 이로 인해 의존성 관계가 과도하게 복잡해질 수 있다.
SRP : 단일책임원칙에 반하는 안티패턴
단위 테스트시 의존성 주입이 용이하지 않음
@Service
public class BugService {
@Autowired
private BugRepository bugRepository;
}
setter를 이용한 방법
장점
의존성이 선택적으로 필요한 경우에 사용(set을 불러올때 사용하니깐!?)
생성자에 모든 의존성을 기술하면 과도하게 복잡해질 수 있는 것으로 선택적으로 나눠 주입 할 수 있게 부담을 덜어줌
생성자 주입과 setter 주입 방법을 적절하게 분배하여 사용을 권장
@Service
public class BugService {
private BugRepository bugRepository;
@Autowired
public void setBugRepository(BugRepository bugRepository) {
this.bugRepository = bugRepository;
}
}
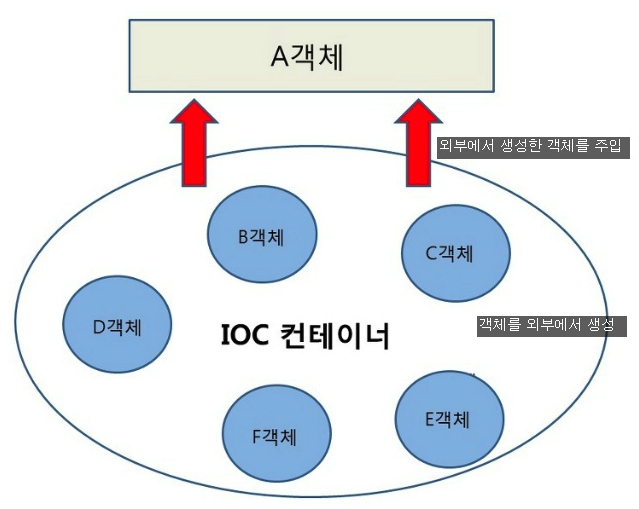
DI(Dependency Injection) 세 가지 방법
느슨한 결합
- 객체를 주입 받는다는 것은 외부에서 생성된 객체를 인터페이스를 통해서 넘겨받는 것이다. 이렇게 하면 결합도를 낮출수 있고, 런타임시에 의존관계가 결정되기 때문에 유연한 구조를 가진다.
- SOULD 원칙에서 O에 해당하는 Open Closed Principle을 지키기 위해서 디자인 패턴 중 전략 패턴을 사용하게 되는데, 생성자 주입을 사용하게 되면 전략 패턴을 사용하게 된다.
Fielid Injection 필드 주입
@Component
public class SampleController {
@Autowired
private SampleService sampleService;
}
Field Injection을 사용하면 안되는 이유
단일 책임(SRP)의 원칙 위반
의존성을 주입하기가 쉽다. @Autowired 선언 아래 개수 제한 없이 무한정 추가할 수 있으니 말이다.
여기서Constructor Injection을 사용하면 다른 Injection 타입에 비해 위기감을 느끼게 해준다.
Constructor의 parameter가 많아짐과 동시에 하나의 Class가 많은 책임을 떠안는다는 걸 알게된다.
이때 이러한 징조들이 Refactoring을 해야한다는 신호가 될 수 있다.
Setter Injection 세터 주입
@Component
public class SampleController {
private SampleService sampleService;
@Autowired
public void setSampleService(SampleService sampleService) {
this.sampleService = sampleService;
}
}
Construtor Injection 생성자 주입 (권장)
아래 처럼 Constructor에 @Autowired Annotation을 붙여 의존성을 주입받을 수 있다.
@Component
public class SampleService {
private SampleDAO sampleDAO;
@Autowired
public SampleService(SampleDAO sampleDAO) {
this.sampleDAO = sampleDAO;
}
}
@Component
public class SampleController {
private final SampleService sampleService = new SampleService(new SampleDAO());
...
}
Spring Framework Reference에서 권장하는 방법은 생성자를 통한 주입이다.
생성자를 사용하는 방법이 좋은 이유는필수적으로 사용해야하는 의존성 없이는 Instance를 만들지 못하도록 강제할 수 있기 때문이다.
Spring 4.3버전부터는 Class를 완벽하게DI Framework로부터 분리할 수 있다.
단일 생성자에 한해 @Autowired를 붙이지 않아도 된다. Spring 4.3부터는 클래스의 생성자가 하나이고 그 생성자로 주입받을 객체가 Bean으로 등록되어 있다면 @Autowired를 생략할 수 있다.
또한 앞서 살펴본Field Injection의 단점들을 장점으로 가져갈 수 있다.
null을 주입하지 않는 한 NullPointerException 은 발생하지 않는다.
의존관계 주입을 하지 않은 경우에는 Controller 객체를 생성할 수 없다. 즉, 의존관계에 대한 내용을 외부로 노출시킴으로써 컴파일 타임에 오류를 잡아낼 수 있다.
final 을 사용할 수 있다.
final로 선언된 레퍼런스타입 변수는 반드시 선언과 함께 초기화가 되어야 하므로 setter 주입시에는 의존관계 주입을 받을 필드에 final 을 선언할 수 없다.
final의 장점은 객체가 불변하도록 할 수 있는 점으로,누군가가 Controller 내부에서 Service 객체를 바꿔치기 할 수 없다는 점이다.
순환 의존성을 알 수 있다.
앞서 살펴 본Field Injection에서는 컴파일 단계에서 순환 의존성을 검출할 방법이 없지만,Construtor Injection에서는 컴파일 단계에서 순환 의존성을 잡아 낼 수 있다.
의존성을 주입하기가 번거로워 위기감을 느낄 수 있다.
Construtor Injection의 경우 생성자의 인자가 많아지면 코드가 길어지며개발자로 하여금 위기감을 느끼게 해준다.
이를 바탕으로 SRP 원칙을 생각하게 되고, Refactoring을 하게 된다.
이러한 장점들 때문에스프링 4.x Documents에서는Constructor Injection을 권장한다.
굳이Setter Injection을 사용하려면, 합리적인 default를 부여할 수 있고 선택적인(optional) 의존성을 사용할 때만 사용해야한다고 말한다. 그렇지 않으면 not-null 체크를 의존성을 사용하는 모든 코드에 구현해야한다.
결국더 좋은 디자인 패턴과 코드 품질을 위해서는Constructor Injection을 사용해야 한다.
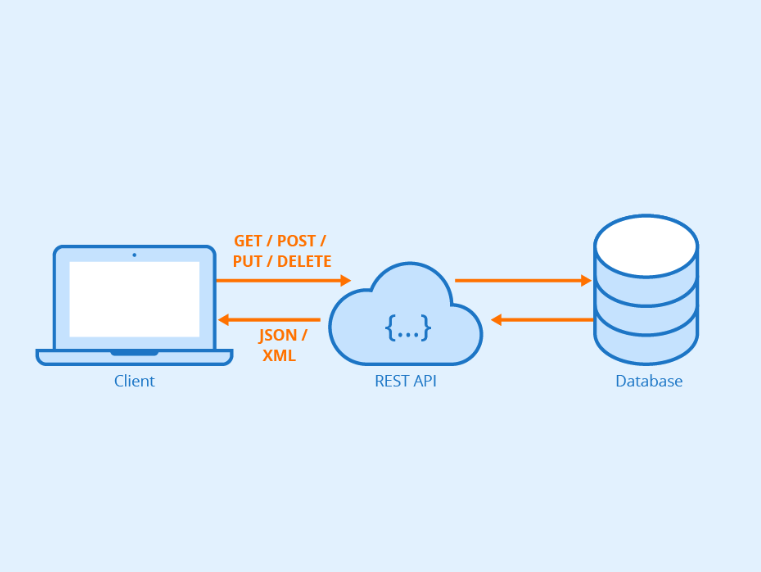
REST(Representational State Transfer)의 약자로 자원을 이름으로 구분하여 해당 자원의 상태를 주고받는 모든 것이라는 뜻이다.
다시 말하면 웹에 존재하는 모든 자원(이미지, 동영상, DB자원)에 고유한 URI를 부여해 활용 하는 것 즉 자원에 대한 주소를 지정하는 방법론을 REST라고 한다.
REST 란! - HTTP URI(Uniform Resource Identifier)을 통해 자원(Resource)를 명시한다. - HTTP Method(POST, GET, DELTE)를 통해 해당 자원(URI)에 대한 CRUD Operation을 적용 하는 것을 의미한다.
우리는 왜 RESTful APIs를 만드는 것일까?
RESTful APIs 개발하는 가장 큰 이유는Client Side를 정형화된 플랫폼이 아닌 모바일, PC, 어플리케이션 등 플랫폼에 제약을 두지 않는 것을 목표로 했기 때문 입니다.
즉, 2010년 이전만 해도 Server Side에서 데이터를 전달해주는 Client 프로그램의 대상은 PC 브라우저로 그 대상이 명확 했다. 그렇다 보니 그냥 JSP ASP PHP 등을 잉요한 웹페이지를 구성하고 작업을 진행하면 됐다.
하지만 스마트 기기들이 등장하면서 TV, 스마트 폰, 테블릿 등 Client 프로그램이 다양화 되고 그에 맞춰 Server를 일일이 만다는 것이 꽤 비효율적인 일이 되어 버렸다.
이런 과정에서 개발자들은 Client Side를 전혀 고려하지 않고 메시지 기반, XML, JSON과 같은Client에서 바로 객체로 치환 가능한 형태의 데이터 통신을 지향하게 되면서 Server와 Client의 역할을 분리하게 되었다.
이런 변화를 겪으면서 필요해진 것은HTTP 표준 규약을 지키면서 API를 만드는 것이다.
CRUD Operation 이란?
CRUD 기본적인 데이터 처리 기능인 Create(생성), Read(읽기), Update(갱신), Delete(삭제)를 묶어서 일컫는 말
Create : 데이터 생성(POST)
Read : 데이터 조회(GET)
Update : 데이터 수정(PUT)
Delete : 데이터 삭제(DELETE)
REST 구성요소
REST는 다음과 같은 3가지로 구성이 되어있다.
자원(Resource) : HTTP URI
자원에 대한 행위(Verb) : HTTP Method
자원에 대한 행위의 내용 (Representations) : HTTP Message Pay Load
1. 자원 (Resource) URL
모든 자원에 고유한 ID가 존재하고, 이 자원은 Server에 존재한다.
자원을 구별하는 ID는 /orders/order_id/1 와 같은 HTTP URI 이다.
2. 행위 (Verb) - Http Method
HTTP 프로토콜의 Method를 사용한다.
HTTP 프로토콜은 GET, POST, PUT, DELETE와 같은 메서드를 제공한다.
3. 표현 (Representaion of Resource)
Client가 자원의 상태 (정보)에 대한 조작을 요청하면 Server는 이에 적절한 응답 (Representation)을 보낸다
REST에서 하나의 자원은 JSON, XML, TEXT, RSS 등 여러 형태의 Representation으로 나타낼 수 있다.
현재는 JSON으로 주고 받는 것이 대부분이다.
REST의 특징
Server-Client(서버-클라이언트 구조)
Stateless(무상태)
Cacheable(캐시 처리 가능)
Layered System(계층화)
Uniform Interface(인터페이스 일관성)
1. Uniform Interface(일관된(=통합된) 인터페이스)
Uniform Interface란, Resource(URI)에 대한 요청을 통일되고, 한정적으로 수행하는 아키텍처 스타일을 의미합니다. 이것은 요청을 하는 Client가 플랫폼(Android, Ios, Jsp 등) 에 무관하며, 특정 언어나 기술에 종속받지 않는 특징을 의미합니다. 이러한 특징 덕분에 Rest API는 HTTP를 사용하는 모든 플랫폼에서 요청가능하며, Loosely Coupling(느슨한 결함) 형태를 갖게 되었습니다.
-> 어떤 장비에도 종속되지 않는다. 아이폰, 안드로이드, 웹..등
2. Stateless(무상태성)
서버는 각각의 요청을 별개의 것으로 인식하고 처리해야하며, 이전 요청이 다음 요청에 연관되어서는 안됩니다. 그래서 Rest API는 세션정보나 쿠키정보를 활용하여 작업을 위한 상태정보를 저장 및 관리하지 않습니다. 이러한 무상태성때문에 Rest API는 서비스의 자유도가 높으며, 서버에서 불필요한 정보를 관리하지 않으므로 구현이 단순합니다. 이러한 무상태성은 서버의 처리방식에 일관성을 부여하고, 서버의 부담을 줄이기 위함입니다.
-> 각각의 요청이 별개여야 한다.
3. Cacheable(캐시 가능)
Rest API는 결국 HTTP라는 기존의 웹표준을 그대로 사용하기 때문에, 웹의 기존 인프라를 그대로 활용할 수 있습니다. 그러므로 Rest API에서도 캐싱 기능을 적용할 수 있는데, HTTP 프로토콜 표준에서 사용하는 Last-Modified Tag 또는 E-Tag를 이용하여 캐싱을 구현할 수 있고, 이것은 대량의 요청을 효울척으로 처리할 수 있게 도와줍니다.
-> HTTP라는 기존의 웹 표준을 사용하기 때문에 캐시도 사용가능하다.
4. Client-Server Architecture (서버-클라이언트 구조)
Rest API에서 자원을 가지고 있는 쪽이 서버, 자원을 요청하는 쪽이 클라이언트에 해당합니다. 서버는 API를 제공하며, 클라이언트는 사용자 인증, Context(세션, 로그인 정보) 등을 직접 관리하는 등 역할을 확실히 구분시킴으로써 서로 간의 의존성을 줄입니다.
-> 서버-클라이언트의 역할이 확실히 구분된다. 요청, 응답 구조
5. Self-Descriptiveness(자체 표현)
Rest API는 요청 메세지만 보고도 이를 쉽게 이해할 수 있는 자체 표현 구조로 되어있습니다. 아래와 같은 JSON 형태의 Rest 메세지는 http://localhost:8080/board 로 게시글의 제목, 내용을 전달하고 있음을 손쉽게 이해할 수 있습니다. 또한 board라는 데이터를 추가(POST)하는 요청임을 파악할 수 있습니다.
->(POST) Rest API 요청 메시지 + body(JSON)을 보고 무슨 내용인지 파악이 가능하다.(=자체표현)
HTTP POST , http://localhost:8080/board
{
"board":{
"title":"제목",
"content":"내용"
}
}
6. Layered System(계층 구조)
Rest API의 서버는 다중 계층으로 구성될 수 있으며 보안, 로드 밸런싱, 암호화 등을 위한 계층을 추가하여 구조를 변경할 수 있습니다. 또한 Proxy, Gateway와 같은 네트워크 기반의 중간매체를 사용할 수 있게 해줍니다. 하지만 클라이언트는 서버와 직접 통신하는지, 중간 서버와 통신하는지 알 수 없습니다.
-> 결국 클라이언트<->서버간 통신인데 중간 과정을 클라이언트가 알 수 없다.
REST API 정의
REST API란 REST의 원리를 따르는 API를 의미한다. 즉 리소스(HTTP URI로 정의됨)를 어떻게 하겠다.(HTTP Method + payload)를 구조적으로 표햔하는 방법이다.
RESTful 이란 REST의 원리를 따르는 시스템을 의미합니다. 하지만 REST를 사용했다 하여 모두가 RESTful 한 것은 아닙니다.
REST API의 설계 규칙을 올바르게 지킨 시스템을 RESTful하다 말할 수 있으며 모든 CRUD 기능을 POST로 처리 하는 API 혹은 URI 규칙을 올바르게 지키지 않은 API는 RESTful 하지 못하다고 할 수 있다.
RESTful의 기준
RESTful 이란
HTTP와 URI 기반으로 자원에 접근할 수 있도록 제공하는 애플리케이션 개발 인터페이스이다. 기본적으로 개발자는 HTTP 메소드와 URI 만으로 인터넷에 자료를CRUD할 수 있다.
'REST API'를 제공하는 웹 서비스를 'RESTful' 하다고 할 수 있다.
RESTful은 REST를 REST 답게 쓰기 위한 방법으로, 누군가가 공식적으로 발표한 것은 아니다.
RESTful API 개발 원칙
a. 자원을 식별할 수 있어야 한다.
URL (Uniform Resource Locator) 만으로 내가 어떤 자원을 제어하려고 하는지 알 수 있어야 한다. 자원을 제어하기 위해서, 자원의 위치는 물론 자원의 종류까지 알 수 있어야 한다는 의미이다.
Server가 제공하는 정보는 JSON 이나 XML 형태로 HTTP body에 포함되어 전송 시킨다.
-> URL RESTFul + JSON / XML 형태로 HTTP body 포함 전송한다.
b. 행위는 명시적이어야 한다.
REST는 아키텍쳐 혹은 방법론과 비슷하다. 따라서 이런 방식을 사용해야 한다고 강제적이지 않다. 기존의 웹 서비스 처럼, GET을 이용해서 UPDATE와 DELETE를 해도 된다.
다만 REST 아키텍쳐에는 부합하지 않으므로 REST를 따른다고 할 수는 없다.
c. 자기 서술적이어야 한다.
데이터에 대한 메타정보만 가지고도 어떤 종류의 데이터인지, 데이터를 위해서 어떤 어플리케이션을 실행 해야 하는지를 알 수 있어야 한다.
즉, 데이터 처리를 위한 정보를 얻기 위해서, 데이터 원본을 읽어야 한다면 자기 서술적이지 못하다
d. HATEOS (Hypermedia as the Engine of Application State)
클라이언트 요청에 대해 응답을 할 때, 추가적인 정보를 제공하는 링크를 포함할 수 있어야 한다.
REST는 독립적으로 컴포넌트들을 손쉽게 연결하기 위한 목적으로도 사용된다. 따라서 서로 다른 컴포넌트들을 유연하게 연결하기 위해선, 느슨한 연결을 만들어줄 것이 필요하다.
이때 사용되는 것이 바로링크이다. 서버는 클라이언트 응용 애플리케이션에 하이퍼 링크를 제공한다.
클라이언트는 이 하이퍼 링크를 통해서 전체 네트워크와 연결되며 HATEOAS는 서버가 독립적으로 진화할 수 있도록 서버와 서버, 서버와 클라이언트를 분리 할 수 있게 한다.
REST의 단점들
REST는 point-to-point 통신모델을 기본으로 한다. 따라서 서버와 클라이언트가 연결을 맺고 상호작용해야하는 어플리케이션의 개발에는 적당하지 않다.
REST는 URI, HTTP 이용한 아키텍처링 방법에 대한 내용만을 담고 있다. 보안과 통신규약 정책 같은 것은 전혀다루지 않는다. 따라서 개발자는 통신과 정책에 대한 설계와 구현을 도맡아서 진행해야 한다.
HTTP에 상당히 의존적이다. REST는 설계 원리이기 때문에 HTTP와는 상관없이 다른 프로토콜에서도 구현할 수 있기는 하지만 자연스러운 개발이 힘들다. 다만 REST를 사용하는 이유가 대부분의 서비스가 웹으로 통합되는 상황이기에 큰 단점이 아니게 되었다.
CRUD 4가지 메소드만 제공한다. 대부분의 일들을 처리할 수 있지만, 4가지 메소드 만으로 처리하기엔 모호한 표현이 있다.
RESTful 하면 뭐가 좋지? self-descriptiveness : RESTful API는 그 자체만으로도 API의 목적(URI만 봐도 이게 뭐하는 URI인지 안다)이 무엇인지 쉽게 알 수 있다. 따라서 API를 RESTful 하게 만들어서 API의 목적이 무엇인지 명확하게 하기 위해 RESTful 함을 지향해야 한다.
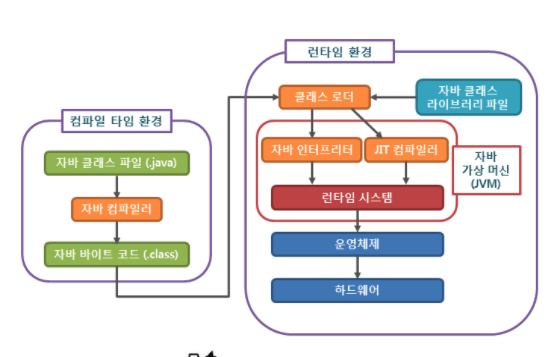
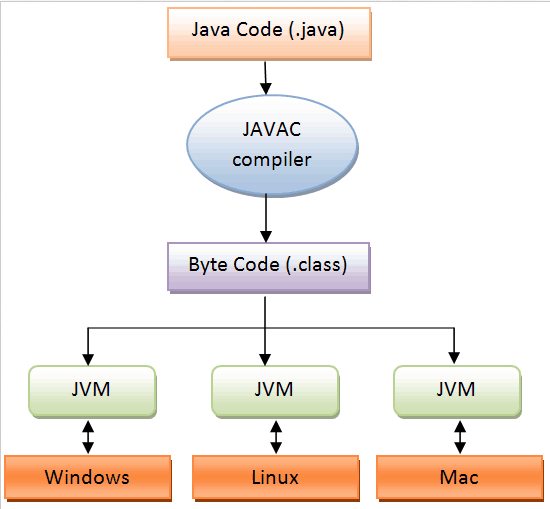
자바 컴파일러가 자바 소스파일을 컴파일한다. 이때 나오는 파일은 자바 바이트 코드(.class)파일로 아직 컴퓨터(=JVM자바 가상 머신)가 읽을 수 없는 코드이다. (바이트 코드의 각 명령어는 1바이트 크기의 Opcode와 추가 피연산자로 이뤄져있다.)
컴파일된 바이트 코드(.class)를 JVM의 클래스 로더(Class Loader)에게 전달된다.
클래스 로더 세부 동장
로드 : 클래스 파일을 가져와서 JVM의 메모리에 로드한다.
검증 : 자바 언어 명세 및 JVM 명세에 명시된 대로 구성되어 잇는지 검사
준비 : 클래스가 필요로 하는 메모리를 할당
분석 : 클래스의 상수 풀 내 모든 심볼릭 레퍼런스를 다이렉트 레퍼런스로 변경
초기화 : 클래스 변수들을 적절한 값으로 초기화
클래스 로더는 동적로딩(Dynamic Loding)을 통해 필요한 클래스들을 로딩 및 링크하여 런타임 데이터 영역(Runtime Data area), 즉 JVM의 메모리에 올립니다.
실행엔진(Exectution Engine)은 JVM메모리에 올라온 바이트 코드를 명령어 단위로 하나씩 가져와서 실행한다.
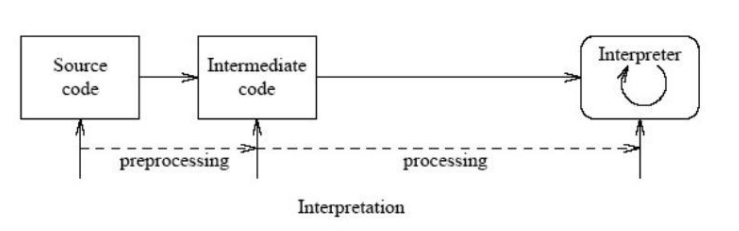
인터프리터 방식 : 바이트 코드 명령어를 하나씩 읽어서 해석하고 실행한다. 하나하나의 실행은 빠르나, 전체적인 실행 속도가 느리다.
JIT 컴파일러(Just-In-Time Compiler) 방식 : 인터프리터 단점을 보완하기 위해 도입된 방식으로 바이트 코드 전체를 컴파일하여 바이너리 코드로 변경하고 이후에는 해당 메서드를 더 이상 인터프리팅 하지 않고, 바이너리 코드로 직접 실행하는 방식
요약
순서
Input
Exe(실행)
Output
1
개발자가 작성한 (.java)
자바 컴파일러가 컴파일
바이트 코드(.class)
2
바이트 코드(.class)
JVM 클래스 로더의 동적로딩
런타임 데이터 영역(=JVM 메모리)에 올린다.
3
JVM 메모리에 올라온 바이트 코드 (.class)
- JVM내에서 인터프리터 or JIT 컴파일러 방식
런타임 시스템 -> 운영체제 ->하드웨어
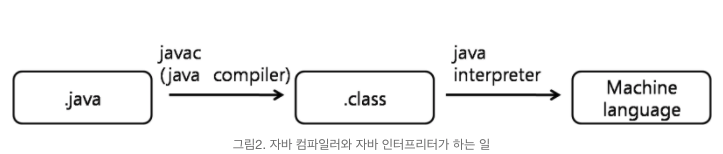
[자바 컴파일러] 1. helloworld.java 작성 2. javac명령어(java compiler)를 통해 helloworld.java 파일을 helloworld.class파일로 변환 (컴파일러가 수행) [자바 인터프리터] 3. 컴파일러에 의해 변환된 helloworld.class 내의 바이트 코드를 특정 환경의 기계(다른 OS)에서 실행될 수 있도록 변환한다. -> 예로 IBM PC에서 작성된 프로그램을 매킨토시에서도 실행할 수 있도록 변환하는 의미이다. 인터프리터가 하는 일자바는 기본적으로 컴파일과 인터프리트를 병행하는 것일까? - 인터프리팅은 플랫폼(OS)에 종속되지 않는다. 물론 컴파일러를 먼저 수행하고 인터프리팅을 하는 과정 때문에 컴파일 과정만 하는 필요한 프로그래밍 언어보다는 속도가 느리다. - 자바 바이트 코드는 컴퓨터와 프로그램 사이에 별도의 버퍼역할을 한다. 자바 인터프리터로 인행 바이러스나 악성 프로그램을 대응 하는 가드 같은 보안 계층에 의해 보호 될 수 있다. 이유는 자바와 자바 바이트 코드의 좋바으로 플랫폼에 독립적이고 안전한 환경을 제공하기 때문이다.
결론 컴파일이라는 과정은 결국 인간이 쓴 인간어(java)를 기계어(Machine Language)로 바꾸는 과정이라고 생각합니다. 자바의 컴파일의 특징은 Java Compiler을 거쳐 만들어진 바이트 코드인 (.class)파일을 interpreter를 통해 기계어로 변환하는 과정에서 interpreter를 사용하므로서 OS에 종속되지 않습니다. (보안에도 좋다)
컴파일러 vs 인터프리터
컴파일러(번역기)
인터프리터(실행기)
방식
- 고급 언어로 작성된 프로그램을 목적 프로그램으로 번역 후 링킹 작업을 통해 실행 프로그램을 생성한다. - 자바는 javac로 컴파일하고 java 실행 시 중간언어(클래스 파일)을 한줄씩 자바 인터프리터가 번역하기에 컴파일 언어 이면서 인터프리터 언어이다.
- 컴파일러는 전체 소스코드를 보고 명령어를 수집하고 재구성한다. 즉 인터프리터 처럼 중간 형태로 변환 시킨 후 실행하지 않고 고레벨 언어를 바로 기계어로 변환한다.
- 고급 언어로 작성된 프로그램을 한줄한줄씩 번역에서 OS에서 인식하는 기계어로 번역하는 역할
- 바이트 코드(.class)를 인터프리터가 한 줄 씩 해석하면서 기계어로 번역한다.
개발 편의성
코드를 수정하고 실행하려면 컴파일러 다시 실행
코드를 수정하고 즉시 실행 가능
실행 속도
빠르다,
느리다.
보안
코드가 유출되지 않는다.
유출될 수 있다.
파일 용량
프로그램의 실행 파일 전체를 전송해야 하므로, 용량이 크다.
프로그램의 코드만 전송하면 실행이 되므로, 용량이 작다.
프로그래밍 언어
C, C++처럼 비교적 저수준에 가까운 언어
Python, Ruby처럼 비교적 고수준에 가까운 언어
흐름도
String, StringBuffer, StringBuilder의 차이 및 장단점
연산이 많지 않을때는 위의 나열된 어떤 클래스를 사용하더라도 이슈가 발생할 가능성이 거의 없다. 하지만 연산횟수가 많아지거나, 멀티쓰레드, Race condition 등의 상황이 자주 발생한다면 각 클래스이 특징을 이해하고 상황에 맞는 적절한 클래스를 사용해야한다.
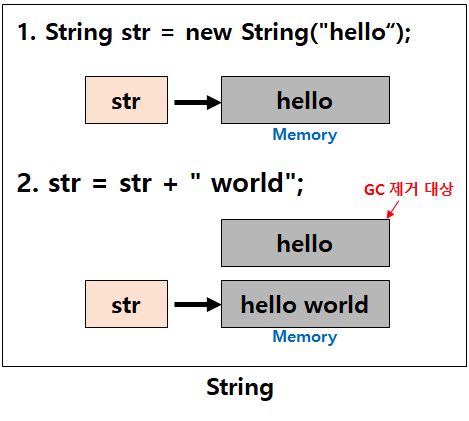
- str이 가르키는 곳에 저장된 "hello"에 "world" 문자열을 더해 "hello world"로 변경한 것으로 착각할 수 있다.
- 하지만 기존 "hello" 값이 들어가있던 String 클래스의 참조변수 str이 "hello world"라는 값을 가지고 있는 새로운 메모리영역을 가리키게 변경었다.
- 처음 선언했던 "hello"로 값이 할당되어 있던 메모리 영역은 Garage로 남아있다가 GC(gabage colltion)에 의해 사라지게된다.
- String 클래스는 불변하기 때문에 문자열을 수정하는 시점에 새로운 String 인스턴스가 생성된 것이다.
즉 hello + wolrd가 된게 아니라 hello 삭제 -> hello wolrd 생성 개념이다. 이유는 불면 속성 때문이다.
단점은 문자열 추가, 수정, 삭제가 빈번하게 발생하는 알고리즘에 String 클래스를 사용하면 힙 메모리(Heap)에 많은 가비지가 생성되어 힙메모리가 부족할 수 있다.
불변 객체(immutable) 불변 객체는 완전히 생성된 후에도 내부 상태가 일정하게 유지 되는 개체입니다. 즉 객체가 변수에 할당되면 참조를 업데이트 하거나 내부 상태를 어떤 방법으로도 변경할 수 없습니다.
왜 String이 불변 객체 일까?(성능, 동기화, 캐싱, 보안) 1. 성능 - 자바에서 문자열은 정말 많이 사용된다. 그렇게 때문에 자바에서는 상수 풀이라는 것을 만들었다. 상수 풀이 무엇인가?
public class Test {
public static void main(String[] args) {
String s1 = "Hello World";
String s2 = "Hello World";
System.out.println(s1 == s2); // true
}
}
위의 코드 실행 과정을 분석해보면 문자열 s1에 해당하는 것을 상수 풀에서 검색을 한다. 없다면 상수 풀에 등록하고 해당하는 레퍼런스 값을 반환한다. s2 문자열도 마찬가지로 상수 풀에서 해당 문자열이 있는지 검색한다. s1을 이미 상수 풀에 등록했기 때문에 같은 레퍼런스로 반환한다.문자열 리터럴을 캐싱하고 재사용하면 문자열 풀의 다른 문자열 변수가 동일한 개체를 참고하기 때문에 힙 공간을 절약할 수 있다. 하지만 조회, 삭제, 수정이 자주 일어나는 환경에선 매우 좋지 못하다.
만약 String mutable(변화가능)하다면 String pool로 생성하여 공유가 불가능하다.
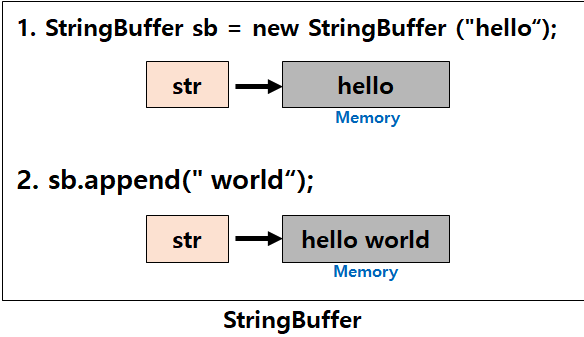
StringBuffer/StringBuilder 가변(mutable)
StringBuffer sb = new StringBuffer("hello");
sb.append(" world");
StringBuffer/StringBuilder
문자열의 추가, 수정, 삭제가 빈번하게 발생 할 때 사용하면 좋다. 따라서 .apped(), .delete() 등의 함수를 통해 동일 객체내에서 문자열을 변경하는 것이 가능하다.
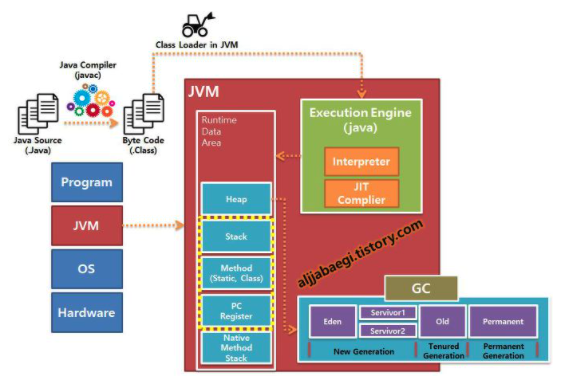
JVM의 구조 1) Garbage Collecotor 2) Execution Engine 3) Class Loader 4) Runtime Data Area
(1) Class Loader
JVM 내로 클래스 파일을 로드하고, 링크를 통해 배치하는 작업을 수행하는 모듈입니다. 런타임 시에 동적으로 클래스를 로드합니다.
(2) Execution Engine
- 클래스 로더를 통해 JVM 내의 Runtime Data Area에 배치된 바이트 코트들을 명령어 단위로 읽어서 실행한다.
- 최초 JVM이 나왔을 당시에는 인터프리터 방식이었기 때문에 속도가 느리다는 단점이 있었지만 JIT 컴파일러 방식을 통해 이 점을 보완하였습니다.
- JIT는 바이트 코드를 어셈블러 같은 네이티브 코드로 바꿈으로써 실행이 빠르지만 역시 변환하는 비용이 발생한다.
- 같은 이유로 JVM은 모든 코드를 JIT 컴파일러 방식으로 실행하지 않고, 인터프리터 방식을 사용하다가 일정한 기준이 넘어가면 JIT 컴파일러 방식으로 실행한다.
(3) Garbage Collector
Garbage Collector(GC)는 힙 메모리 영역에 생성된 객체들 중에서 참조되지 않은 객체들을 탐색 후 제거하는 역할을 한다. 이때, GC가 역할을 하는 시간은 언제인지 정확히 알 수 없다.
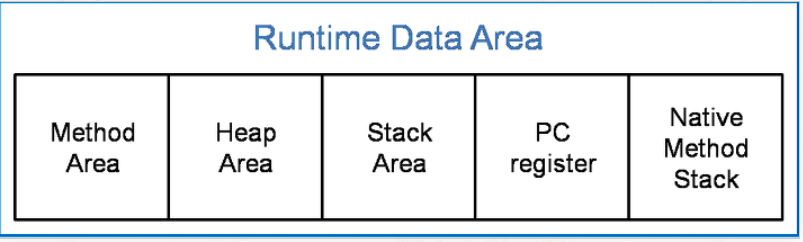
(4) Runtime Data Area
JVM 메모리 영역으로 자바 애플리케이션을 실행 할 때 사용되는 데이터들을 적재하는 영역입니다. 이 영역은 크게 Method Area, Heap Area, Stack Area, PC Register, Native Method Stack 으로 나눌 수 있다.
Runtime Data Area 영역
설명
(1) Method Area : 모든 쓰레드가 공유하는 메모리 영역이다. 메소드 영역은 클래스, 인터페이스, 메소드, 필드, static 변수 등의 바이트 코드를 보관한다. (2) Heap Area : 모든 쓰레드가 공유하며, new 키워드로 생성된 객체와 배열이 생성되는 영역이다. 또한, 메소드 영역에 로드된 클래스만 생성이 가능하고 GC가 참조되지 않은 메모리를 확인하고 제거하는 영역이다. (3) Stack area : 메소드 호출 시마다 각각의 스택 프레임(그 메서드만을 위한 공간)이 생성 그 메서드 안에서 사용되는 값을 저장하고, 호출된 연신 시 임시로 저장하며 메서드 수행이 끝나면 프레임별로 삭제(후입선출) (4)PC Register : 쓰레드가 시작될 때 생성되며, 생성될 때마다 생성되는 공간으로 쓰레드마다 하나씩 존재합니다. 쓰레드가 어떤 부분을 무슨 명령으로 실행해야할 지에 대한 기록을 하는 부분으로 현재 수행중인 JVM 명령의 주소를 갖는다. (5) Native method stack 자바 외 언어로 작성된 네이티브 코드를 위한 메모리 영역이다.
인터페이스(Interface)와 추상 클래스(abstract class)
추상 클래스(abstract class)
클래스를 설계도라 하면, 추상 클래스는 미완성 설계도에 비유할 수 있다.
추상 메서드
선언부만 작성하고 구현부는 작성하지 않은 채 남겨 둔 것이며 추상 메서드는 상속받는 클래스에 따라 달라질 수 있다.
- 이를 상속할 각 객체들의 공통점을 찾아 추상화시켜 놓은 것으로, - 상속 관계를 타고 올라갔을 때 같은 부모 클래스를 상속하며 부모 클래스가 가진 기능들을 구현해야할 경우 사용한다.
- 상속 관계를 올라갔을 때 다른 조상 클래스를 상속하더라도, 같은 기능이 필요할 경우 사용한다.
적절한 케이스
- 관련성이 높은 클래스 간에 코드를 공유하고 싶은 경우 - 추상 클래스를 상속 받을 클래스들이 공통으로 가지는 메소드와 필드가 많거나 public이외의 접근자(protected, private) 선언이 필요한 경우 - non-static, non-final 필드 선언이 필요한 경우
- 서로 관련성이 없는 클래스들이 인터페이스를 구현하게 되는 경우 - 특정 데이터 타입의 행동을 명시하고 싶은데, 그 행동이 구현되는지 신경쓰지 않는 경우 - 다중상속을 허용하고 싶은 경우
차이점!!!
1. 사용의도 차이점 - 추상클래스는 IS -A "~이다". 인터페이스는 HAS -S "~을 할 수 있는" 자바의 특성상 한개의 클래스만 상속이 가능하여 해당 클라스의 구분을 추상 클래스 상속을 통해 해결하고, 할 수 있는 기능들을인터페이스로 구현합니다.
2. 공통된 기능 사용 여부 만약 모든 클래스가 인터페이스를 기본 틀을 구성한다면, 공통으로 필요한 기능들도 모든 클래스에서 오버라이딩 하여 재정의 해야하는 번거로움이 있습니다. 공통된 기능이 필요하다면 추상클래스를 이용해서 일반 메서드를 작성하여 자식 클래스에서 사용할 수 있도록 하면된다. 만약 각각 다른 추상클래스를 상속하는데 공통된 기능이 필요하하다면, 해당 기능을 인터페이스로 작성해서 구현한다. ex) 추상클래스 : 홍길동은 생명체를 상속받는다. 참새는 생명체를 상속받는다. 생명체는 숨쉬기는 기능이있다. (공통) 인터페이스 : 홍길동은 talkable 인터페이스를 다중 상속한다. 참새는 flyable을 상속받는다. 각각 공통된 기능이 아니므로 interface를 implements한다.
Call by Value와 Call by reference in Java
말 그대로 '값에 의한 호출' 이냐, '참조에 의한 호출' 이냐 라고 할 수 있다.
- Call by value는 메서드 호출 시에 사용되는 인자의 메모리에 저장되어 있는 값(value)을 복사하여 보낸다. 주소 값을 보낸 게 아니어서 메서드 밖에선 값이 안 변한다. - Call by reference는 메서드 호출 시에 사용되는 인자가, 값이 아닌 주소(Address)를 넘겨줌으로써, 주소를 참조(Referece) 하여 데이터를 변경할 수 있습니다.
//callByValue
Class CallByValue{
public static void swap(int x, int y) {
int temp = x;
x = y;
y = temp;
}
public static void main(String[] args) {
int a = 10;
int b = 20;
System.out.println("swap() 호출 전 : a = " + a + ", b = " + b);
swap(a, b);
System.out.println("swap() 호출 후 : a = " + a + ", b = " + b);
}
}
결과 :
호출 전 : a=10 b= 20
호출 후 : a=10 b= 20
//=================================================================================
//callByReference
Class CallByReference{
int value;
CallByReference(int value) {
this.value = value;
}
public static void swap(CallByReference x, CallByReference y) {
int temp = x.value;
x.value = y.value;
y.value = temp;
}
public static void main(String[] args) {
CallByReference a = new CallByReference(10);
CallByReference b = new CallByReference(20);
System.out.println("swap() 호출 전 : a = " + a.value + ", b = " + b.value);
swap(a, b);
System.out.println("swap() 호출 전 : a = " + a.value + ", b = " + b.value);
}
}
결과 :
호출 전 : a=10 b= 20
호출 후 : a=20 b= 10
그렇다면 Java는 call by value 일까? call by reference 일까?
사실 자바는 Call by value이냐, Call by reference이냐 로 의견이 분분합니다. 메모리에 저장 된 주소를 보내는 것도 물리적 관점에서 보면 값으로 볼 수 있기 때문인데요, 이 문제에 대해서도 한번 생각해 보신다면 좋을 것 같습니다. 결론은 메모리에 저장된 주소(값)을 보내는 것이므로 자바는 Call by value 이다. 참고 : http://wonwoo.ml/index.php/post/1679
결론, Java는 항상 call by value이다.
- 자바는 객체의 주소를 가져오는 방법이 없다. 만약 call by reference를 지원한다면 주소를 가져오는 방법을 지원해야 한다. 맞네..C처럼 레퍼런스를 써서 가져오든, 포인터를 써서 가져오던지 해야하는데 그게 없다.
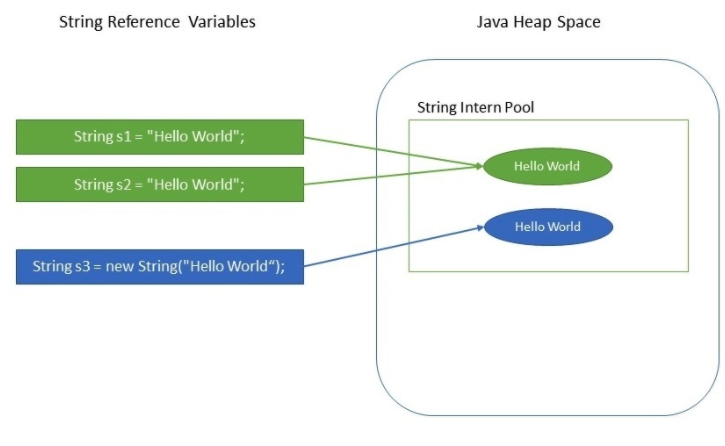
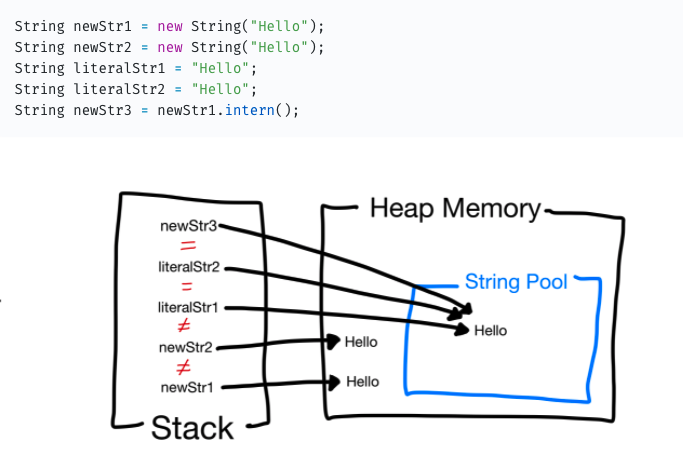
👀 String Pool이란? Java Heap Memory 내에 문자열 리터럴을 저장한 공간.(HashMap으로 구현) 한번 생성된 문자열 리터럴은 변경될 수 없다.문자열 리터럴은 클래스가 메모리에 로드될 때 자동적으로 미리 생성된다.
리터럴로 문자열을 생성하면(내부적으로 String.intern() 호출) String Pool에 같은 값이 있는지 찾는다.같은 값이 있으면 그 참조값이 반환된다.같은 값이 없으면 String Pool에 문자열이 등록된 후 해당 참조값이 반환된다.
String 객체 생성
설명
위의 두가지 방식은 String 객체를 생성한다는 사실은 같지만, JVM이 관리하는 메모리 구조상에서 명백히 다르다. 아래의 그림은 두가지 방법으로 String 객체를 생성했을 때, JVM 메모리상에 어떻게 존재하는지에 대한 이해를 돕는 그림이다.
Java Garbage Collector 의동작원리
JVM에서 GC의 스케줄링을 담당하여 Java 개발자에게 메모리 관리의 부담을 덜어준다.
GC는 background에서 데몬 쓰레드로 돌며 더이상 사용되지 않는 객체들을 메모리에서 제거하여 효율적인 메모리 사용을 돕는다
객체는 힙 영역 저장되고 스택 영역에 이를 가리키는 주소값이 저장되는데 참조되지 않는(자신을 가리키는 포인터가 없는) 객체를 메모리에서 제거한다.
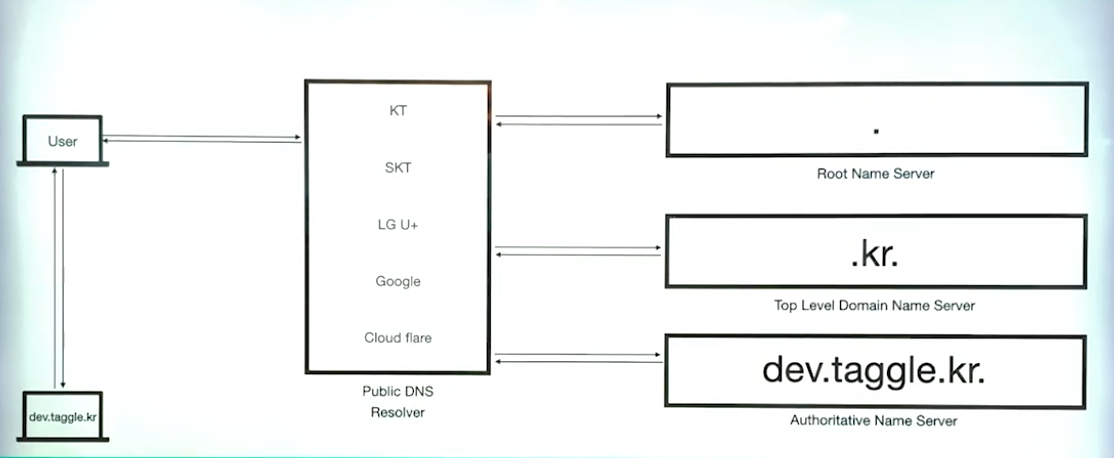
DNS의 작동원리
DNS 흐름도
설명
1. LocalDNS에 질의 웹 브라우저에 ww.naver.com을 입력하면 먼저 Local DNS에게 "ww.naver.com"이라는 hostname에 대한 IP 주소를 질의 하여 Local DNS에 없으면 다른 DNS name 서버 정보를 받음 (Root DNS 정보 전달 받음)
2. Root DNS에 질의
3. Root DNS 서버로 부터 "com 도메인"을 관리하는 TLD(Top-Level-Domain) 이름 서버 정보 전달 받음
4. TLD에 질의
5. TLD에서 관리하는 DNS 정보 전달
6. naver.com 도메인을 관리하는 DNS 서버에 호스트네임에 대한 IP 주소 질의
7. from 도메인관리 DNS 서버 to Local DNS naver.com 도메인을 관리하는 DNS 서버으로 부터 Local DNS 서버에게 응 naver.com에 대한 IP 주소는 222.122.195.6 응답
8. Local DNS는 naver.com에 대한 IP 주소를 캐싱하고 IP 주소 정보 전달
1. DNS Query (from Web Browser to Local DNS) : "제가 원하는 웹 사이트의 IP 주소를 알고 계신가요?" Local DNS 서버에게 전달
2. DNS Query (from Local DNS to Root DNS) : "제가 원하는 웹 사이트의 IP 주소를 알고 계신가요?" Root DNS서버에게 전달
3. DNS Response (from Root DNS to Local DNS) : "저는 모르지만 , Com 도메인을 관리하는 네임서버의 이름과 IP 주소를 알려드릴 테니 거기에 물어보세요"
4. DNS Query (from Local DNS to com NS) : “ 안녕하세요. www. naver. com의 IP 주소를 알고 계신가요?"
5. DNS Response (from com NS to Local DNS) : "저는 모르지만 , Com 도메인을 관리하는 네임서버의 이름과 IP 주소를 알려드릴 테니 거기에 물어보세요"
6. DNS Query (from Local DNS to naver. com NS) : “ 안녕하세요. www. Naver .com의 IP 주소를 알고 계신가요?"
7. DNS Response (from naver .com NS to Local DNS) : "저는 모르지만 해당 웹은 www. g.naver. com이라는 이름으로 통해요. g.naver .com 도메인을 관리하는 네임서버의 이름과 IP 주소를 알려드릴테니 거기에 물어보세요"
8. DNS Query (from Local DNS to g.naver. com NS) : “ 안녕하세요. www. g.naver. com의 IP 주소를 알고 계신가요?"
9. DNS Response (from g.naver .com NS to Local DNS) : " 네 www. g.naver .com의 IP 주소는 222.222.222.22와 333.333.333.33입니다"
10. DNS Response (from Local DNS to Web Browser) : "네 www. naver .com의 IP 주소는 222.222.222.22와 333.333.333.33입니다"
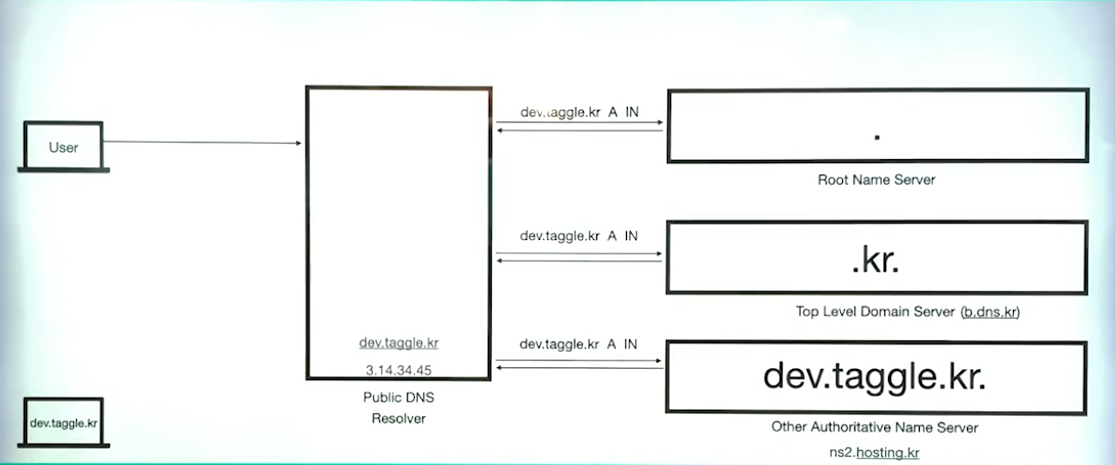
우아한 테크코드 DNS 설명
DNS탄생
설명
*DNS는 결국 IP주소를 얻어오는 과정이라고 볼 수 있다.
[가정 : idea] 1) User가 dnstest.kr이라는 주소를 알고 있고 자신의 host(sudo vi ~etc/hosts)에 해당 아이피주소를 입력해놨다. 2) 그렇다면 hosts파일을 통해서 IP주소를 얻어와 해당 주소로 3.34.244.232로 접속 가능하다. but 개인이 모든 아이피 값을 hosts에 입력하여 관리할 수 가없다.
*DNS 서버가 그래서 생겼다.
개인User가 hosts값을 모를 때 DNS 서버에 요청하여 IP값을 받아온다.
public DNS서버는 보통 통신사이다. if(통신사가 IP를 알고있다) - 바로 내려준다. 트리형으로 알아간다. else if (통신사가 IP알지 못한다.) -
권한이 없을 때(통신사가 IP알지 못할 때) - Root domain부터 순서대로 질의를 해서 알아간다. (트리형) - 왜 분산해서 트리형으로 조회하나? 서버과부하 방지하기위해
트리형으로 질의를 통해 알아가는 과정
쿠키 / 세션 / 캐시 비교
특징
원리
장점
쿠키
사용자의 브라우저에 저장되고, 통신할 때 HTTP 헤더에 포함되는 텍스트 데이터 파일 이름, 값 만료기간(지정 가능), 경로 정보가 있고 키와 값으로 구성되어 있다 해당 사용자의 컴퓨터를 사용한다면 누구나 쿠키에 입력된 값을 쉽게 확인 가능 -> 보안성이 낮다!
(1) 최초 통신에서는 쿠키값이 없으므로, 일단 클라이언트는 Request 를 한다. (2) 서버에서 클라이언트가 보낸 Request Header에 쿠키가 없음을 판별. 통신 상태(UserID, Password, 조작상태, 방문횟수 등)를 저장한 쿠키를 Response한다. (3) 클라이언트의 브라우저가 받은 쿠키를 생성/보존한다 (4) 두번째 연결부턴, HTTP Header에 쿠키를 실어서 서버에 Request 한다
- 클라이언트는 총 300개의 쿠키를 저장할 수 있음 - 하나의 도메인 당 20개의 쿠키를 가질 수 있음 -> 20개가 넘으면 가장 적게 사용되는 것부터 삭제됨 - 하나의 쿠키는 4KB (4096byte) 저장 가능
자동 로그인 유지, 위시 리스트 저장, 팝업 보지 않기
세션
서버'에 저장되는 쿠키. 클라이언트와 서버의 통신 상태. 주로 중요한 데이터를 저장 시 사용 브라우저를 종료할 때까지 유지 됨 사용자 로컬이 아닌 서버에 직접 저장되므로, 세션 내의 데이터를 탈취하는 것은 어려움 -> 보안성이 비교적 높음
(1) 클라이언트가 서버에 접속 시, 세션 ID를 발급한다. (2) 서버에서는 클라이언트로 발급해준 세션 ID를 쿠키를 이용해서 저장 (3) 클라이언트는 다시 페이지에 접속할 때, 쿠키에 저장된 세션 ID를 서버에 전달 (4) 서버는 Request Header에 쿠키 정보(세션 ID)로 클라이언트를 판별
로그인 정보 유지
캐시
리소스 파일들의 임시 저장소. 같은 웹 페이지에 접속할 때 사용자의 PC에서 로드하므로 서버를 거치지 않아도 된다. 이전에 사용되었던 데이터는 다시 사용될 가능성이 높다 -> 그래서 다시 사용될 확률이 있는 데이터들을 빠르게 접근 가능한 저장소에 저장한다. => 페이지 로딩 속도를 개선함 이미지, 비디오 오디오, CSS/JS 등...
(1) 캐시 히트(Cache Hit) CPU가 참조하려는 메모리가 캐시에 존재하고 있는 경우
(2) 캐시 미스(Cache Miss) <-> 캐시 히트와 반대로, 메모리에 캐시가 존재하지 않는 경우
방식
내용
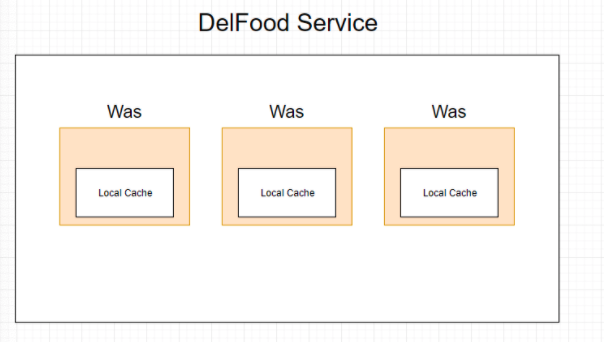
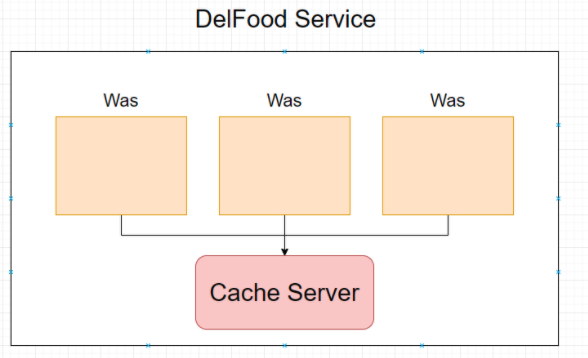
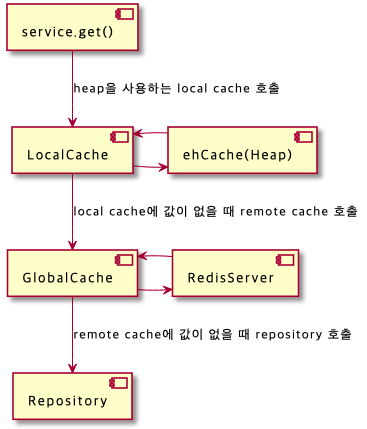
Local 캐시
- 서버마다 캐시를 따로 저장한다. - 로컬 서버의 리소스를 사용한다. - 서버 내에서 작동하기 때문에 빠르다. - 다른 서버의 캐시를 참조하기 어렵다.
Global 캐시
- 여러 서버에서 캐시 서버를 참조합니다. - 네트워크 트래픽을 사용해야 해서 로컬 캐시보다는 느립니다. - 서버간 데이터 공유가 쉽습니다. - Redis 서버를 사용
LocalCache & GlobalCache
ORM이란?
ORM(Object Relational Mapping) 즉, 객체-관계 매핑의 줄임말이다. 객체-관계 매핑을 풀어서 설명하자면 OOP에서 쓰이는 객체와 RDB(Relational DataBase)에서 쓰이는 데이터인 테이블 자동으로 매핑(연결) 하는 것을 의미한다. 하지만 기존부터 호환가능성을 두고 만들어 진 것이 아니기 때문에 불일치가 발생한다. 이를 ORM을 통해 객체 간의 관계를 바탕으로 SQL문을 자동으로 생성하여 불일치를 해결한다. 즉, 객체 관계 매핑, 객체와 RDB를 별개로 설계하고 ORM이 매핑 해주는 역할이며, ORM은 SQL문이 아닌 RDB에 데이터 그 자체와 매핑하기 때문에 SQL을 직접 잘성할 필요가 없다. 이로인해 어떤 RDB를 사용하던 상관 없다.
MyBatis 마이바티스는 데이터베이스 레코드에 원시타입과 Map 인터페이스 그리고 자바 POJO를 설정하여 매핑하기 위해 XML과 어노테이션을 사용할 수 있다 즉, MyBatis는 자바에서 SQL Mapper를 지원해주는 FrameWork이다. 즉, SQL 작성을 직접 하여 객체와 매핑시켜준다.
SQL Mapper SQL문을 이용하여 RDB에 접근, 데이터를 오브젝트(객체)화 시켜준다. 개발자가 작성한 SQL문으로 해당되는 ROW를 읽어 온 후 결과 값을 오브젝화 시켜 사용가능하게 만들어준다. 즉, RDB에 따라 SQL문법이 다르기 때문에 특정 RDB(작성한 SQL)에 종속적이다.
JPA의 장/단점
장점
RDB에 상관없이 사용가능 -> 재사용성 유지보수 용이
CRUD 기본적인 제공과 페이징 처리 등 상당 부분이 구현되어 있음
테이블 생성, 변경 엔티티 관리가 편하다.
쿼리에 집중할 필요가 없다.
단점
어렵다.
단방향, 양방향, 임베디드 관계 등 이해해야할 내용이 많으며, 연관관계 이해 없이 잘못 코딩 했을 시 성능상의 문제와 동작이 원하는 대로 되지 않는다.
ex) Board 엔티티에 List형태로 Reply 엔티티가 있을 시, 단방향 연관관계인 경우 하나의 Reply가 변경되어도 모두 삭제되고 전부 Insert되는 경우
ex) 하나의 Board 조회 시 Reply를 Join이 아닌 여러개의 select 문으로 하나하나 읽어오는 문제(N+1)
MyBatis의 장/단점
장점
JPA비해 직관적이며 쉽다.
SQL 쿼리를 그대로 사용하기에 Join, 튜닝 등을 좀 더 수월하게 작성 가능하다.
SQL의 세부적인 내용 변경 시 좀 더 간편하다.
동적 쿼리 사용 시 JPA보다 간편하게 구현 가능하다.
단점
데이터 베이스 설정 변경 시 수정할 부분이 너무 많다.
Mapper 작성부터 인터페이스 설계까지 JPA보다 많은 설계와 로직이 필요하다.
특정 DB에 종속적이다.
ORM 프레임워크
- JPA/Hibernate
JPA(Java Persitence API)는 자바의 ORM 기술 표준으로 인터페이스의 모음이다. 이러한 JPA 표준 명세를 구현한 구현체가 바로 Hibernate이다.
사용 예제
프레임 워크
예제
iBatis
Java
Hibernate
JPA Interface : 인터페이스 ↓ 상속 Hibernate, EcipseLink, DataNucleus 등 : 구현체
JPA
ex) 기존쿼리 : SELECT * FROM MEMBER; 이를 ORM을 사용하면 Member테이블과 매핑된 객체가 member라고 할 때, member.findAll()이라는 메서드 호출로 데이터 조회가 가능하다. 만약 Mybatis 였다면 신규 컬럼이 추가 되면 DTO(Vo, Domain), DAO 개발 수정 작업이 매무 반복되어 일어난다. (쿼리 수정, 모델 수정 등...)
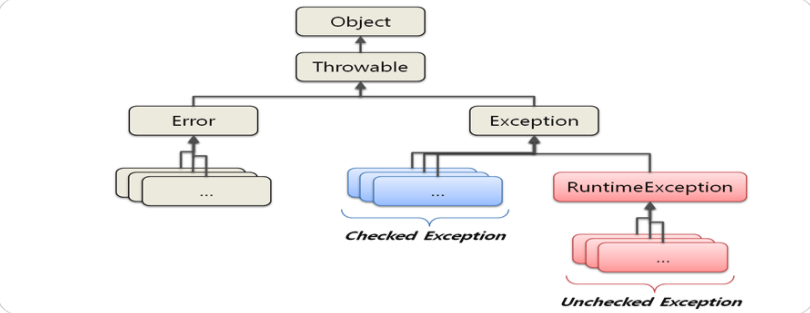
Exception은 Checked Exception과 unchecked Exception으로 구분할 수 있는데, 간단하게 RuntimeException을 상속하지 않는 클래스는 Checked Exception, 반대로 상속한 클래스는 unchecked Exception 으로 분류할 수 있다.
가장 중요한 부분은 처리여부이다. RuntimeException을 상속한 클래스를 조금 특별하게 취급한다. 명시적으로 예외처리를 하지 않아도 된다.
Spring에서 어떤 exception에서 롤백처리를 하나?
unchecked Exception의 경우 롤백처리를 하며 스프링의 @transactional 옵션에 rollback가 있는데 디폴트 값이 runtimeException, error이다. 즉 디폴트 값이 runtimeException이므로 롤백된다.
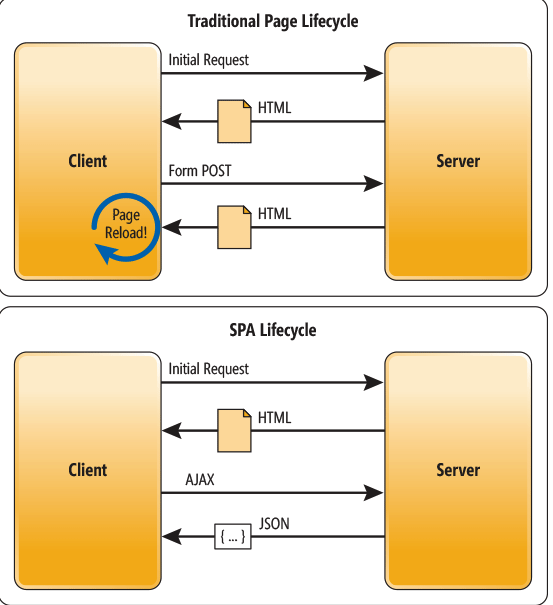
기존 웹 서비스는 요청시마다 서버로부터 리소스들과 데이터를 해석하고 화면에 렌더링하는 방식이다. SPA 형태는 브라우저에 최초에 한번 페이지 전체가 로드하고, 이후부터는 특정 부분만 Ajax를 통해 데이터를 바인딩하는 방식이다.
전통적인 페이지 vs 단일 페이지 어플리케이션 비교
자바스크립트의 발전
초기의 SPA개념 : Backbone.js, Angular.js 라이브러리
지금은 템플릿 개념을 지나 컴포넌트 개념 : React.js, Vue.js
SPA 구현을 쉽게 말하면 jsp파일 없이 index.html파일 하나에 js, css등 리소스 파일들과 모듈들을 로드해서 페이지 이동 없이 특정영역만 새로 모듈을 호출하고 데이터를 바인딩하는 개념이다. 물론 이와 같이 개발하기 위해서는 ES6, Node.js, npm 그리고 webpack 같은 번들러 등 개념을 한번 정도는 잡고 접근해야 할게 많다.
단일 페이지 응용 프로그램 및 사용자 경험
사용자 측면에서 일정한 전체 페이지 새로 고침 혹은 웹사이트에서 정보를 얻기 위해 앞뒤로 왔다갔다 하는 것은 과도한 네트워크 트래픽을 유도하고 편이성 마저 떨어집니다. HTML 버전의 데이터는 모든 여는 태그와 닫는 태그로 인해 일반 JSON 객체와 비교할 때 훨씬 더 크기가 더 크며, 비슷한 페이지를 계속로드하는 경우에는 많은 HTML이 중복됩니다. 또한 두 번째 큰 장점 인 적은 페이지 전체 재로드로 인한 사용자 경험 향상과 더 적은 대역폭이 필요하기 때문에 전반적인 성능 향상이 있습니다.
- HTTP가 등장한 때는 1990년인데, 이 당시 HTTP가 정식 사양서는 아니었습니다. 이 당시 등장한 HTTP는 1.0 이전이라는 의미에서 HTTP/0.9로 불리고 있습니다.
HTTP/1.0
- HTTP가 정식 사양으로 공개된 것은 1996년 5월이었습니다. 이 때 HTTP/1.0으로 RFC1945가 발행되었습니다. 초기의 사양이지만 현재에도 아직 많은 서버상에서 가동되고 있습니다.
HTTP/1.1
- 1997년 1월에 공개된 HTTP/1.1 버전이 현재 가장 많이 사용되는 버전입니다.
웹 문서 전송 프로토콜로서 등장한 HTTP는 거의 버전 업이 되지 않았습니다. 현재 차세대 HTTP/2.0이 책정되어 있지만 널리 사용되기까지는 아직 시간이 걸릴 것 입니다. HTTP가 등장할 당시 텍스트를 전송할 수단이었지만 프로토콜 자체가 워낙 심플해서 여러 가지 응용 방법을 고려해 기능을 계속 추가하였습니다.
네트워크의 기본은 TCP/IP
HTTP 를 이해하기 위해선 TCP/IP 프로토콜에 대해 어느 정도 알고 있어야 한다. 인터넷을 포함한 일반적으로 사용하고 있는 네트워크는 TCP/IP 라는 프로토콜에서 움직이고 있습니다. HTTP는 그 중 하나입니다.
컴퓨터와 네트워크 기기가 상호간에 통신하기 위해서는 서로 같은 방법으로 통신하지 않으면 안됩니다. 따라서 규칙이 필요한데 그것을 프로토콜이라고 부릅니다.
프로토콜에는 여러가지가 있고 그 중 인터넷과 관련된 프로토콜을 모은 것을 TCP/IP라고 부릅니다. TCP와 IP 프로토콜을 가르켜 TCP/IP라고 부르기도 하지만, IP 프로토콜을 사용한 통신에서 사용되고 있는 프로토콜을 총칭해서 TCP/IP라는 이름이 사용되고 있습니다.
계층으로 관리하는 TCP/IP
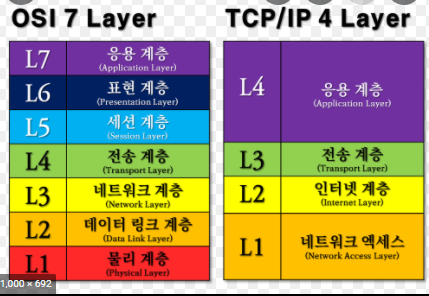
TCP/IP 4 Layer
설명
TCP/IP가 계층화된 것은 메리트가 있습니다. 예를들면, 인터넷이 하나의 프로토콜 되어 있다면 어디선가 사양이 변경된다면 전체를 바꿔야하지만, 계층화되어 있으면 사양이 변경되었을 때 전체를 바꾸지 않아도 되고 부분만 변경되면 된다.
애플리케이션(응용) 계층
응용 계층은 유저에게 제공되는 애플리케이션에서 사용하는 통신의 움직임을 결정하고 있습니다. ex) FTP, DNS 등도 애플리케이션의 한 가지입니다. HTTP도 이 계층에 포함됩니다.
전송 계층
트랜스포트(전송) 계층은 애플리케이션 계층에 네트워크로 접속되어 있는 2대의 컴퓨터 사이의 데이터 흐름을 제공합니다. 트랜스포트 계층에서는 서로 다른 성질을 가진 TCP와 UDP 두 가지 프로토콜이 있습니다.
인터넷(네트워크) 계층
네트워크 계층은 네트워크 상에서 패킷의 이동을 다룹니다. 패킷이란 전송하는 데이터의 최소 단위입니다. 이 계층에서는 어떠한 경로(이른바 절차)을 거쳐 상대의 컴퓨터까지 패킷을 보낼지를 결정합니다. 인터넷의 경우라면 상대 컴퓨터에 도달하는 동안에 여러 대의 컴퓨터랑 네트워크 기기를 거쳐서 상대방에게 배송 됩니다. 그러한 여러가지 선택지 중 하나의 길을 결정하는 것이 네트워크 계층의 역할이다.
네트워크(링크, 데이터 링크) 엑세스
네트워크에 접속하는 하드웨어적인 면을 다룹니다. 하드웨어적 측면은 모두 링크 계층의 역할입니다.
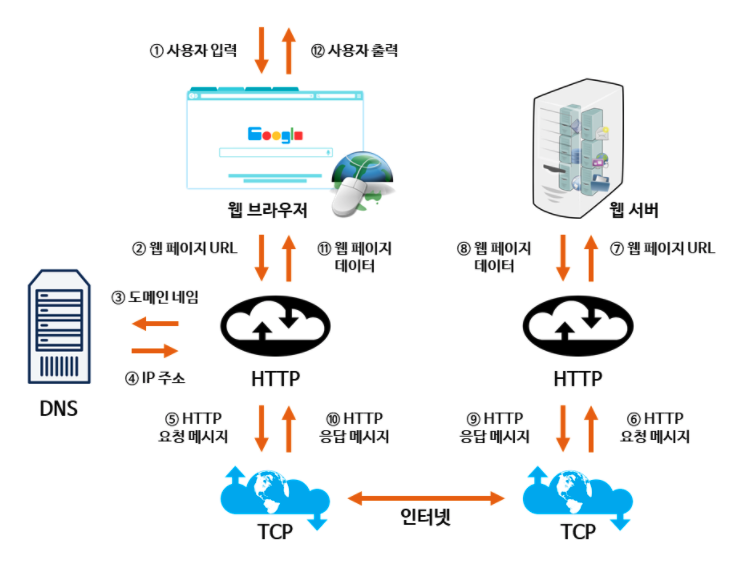
TCP/IP 통신의 흐름
설명
송신하는 측은 애플리케션 계층에서부터 top-down하고 수신하는측은 bottom-up한다.
1) 송신측 클라이언트의 애플리케이션 계층(HTTP)에서 어느 웹 페이지를 보고 싶다라는 HTTP 리퀘스트를 지시 2) 트랜스포트 계층(TCP)에서는 애플리케이션 계층에서 받은 데이터 (HTTP 메시지)를 통신하기 쉽게 조각내어 안내포트와 포트번호를 붙여 네트워크 계층에 전달 3) 네트워크 계층(IP)에서는 수신지 MAC 주소를 추가해서 링크 계층에 전달
HTTP와 관계가 깊은 프로토콜은 IP/TCP/DNS
배송을 담당하는 IP
IP(Internet Protocol)는 계층으로 말하자면 네트워크 계층에 해당된다. 'IP'와 'IP주소'를 혼동하는사람이 있는데 'IP'는 프로토콜의 명칭이다. IP의 역할은 개개의 패킷을 상대방에게 전달하는 것이다. 상대방에게 전달하기까지 여러 가지 요소가 필요하다. 그 중에서도 IP주소와 MAC주소라는 요소가 중요하다.
IP주소와 MAC주소는? IP주소는 각 노드에 부여된 주소를 가르킨다. MAC주소는 각 네트워크 카드에 할당된 고유의 주소이다. IP주소와 MAC주소는 결부된다. IP주소는 변경가능하지만, MAC주소는 기본적으로 변경 불가다.
통신은 ARP를 이용하여 MAC주소에서 한다.
ip통신은 mac주소에 의존해서 통신을한다. ARP는 주소를 해결하기 위한 프로토콜이며 수신지의 IP주소를 바탕으로 MAC주소를 조사할 수 있다.
그 누구도 인터넷 전체를 파악하고 있지는 않다.
ARP 예시
설명
목적지 까지 라우터를 통해 찾아가는 송신측(ARP)
위 그림과 같이 목적지까지 중계를 하는 도중에 컴퓨터와 라우터 등의 네트워크 기기는 목적지에 도착하기 전까지 대략적인 목적지만을 알고 있다. 이 시스템을 라우팅이라고 부르는데 택배 배송과 흡사합니다. 화물을 보내는 사람은 택배 집배소 등에 화물을 가지고 가면 택배를 보낼 수 있는 것만 알고 있으며, 집배소는 화물을 보내는 곳을 보고 어느 지역의 집배소에 보내면 되는지만 알고 있습니다.
신뢰성을 담당하는 TCP
TCP 계층은 트랜스포트 계층에 해당한다. 신뢰성 있는 바이트 스트림 서비스를 제공한다.
바이트 스트림
용량이 큰 데이터를 보내기 쉽게 TCp 세그먼트라고 불리는 단위 패킷으로 작게 분해하여 관리하는 것을 말한다.
신뢰성 있는 서비스
상대방에게 보내는 서비스를 의미한다. 상대에게 확실하게 데이터를 보내기 위해서 TCP는 "쓰리웨이 핸드쉐이킹(three way handshaking)이라는 방법을 사용하고 있다.
쓰리웨이 핸드쉐이킹(three way handshaking) 송신측에서는 최초 SYN 플래그로 상대에게 접속함과 동시에 패킷을 보내고, 수신측에서는 SYN/ACK 플래그로 송신측에 접속함과 동시에 패킷을 수신한 사실을 전달한다. 마지막으로 송신측이 'ACK' 플래그를 보내 패킷 교환이 완료됨을 전한다. 만약 중간에 끊어지면 tcp는 그와 동시에 같은 수순으로 패킷을 재전송한다.
이름 해결을 담당하는 DNS
DNS(Dmain Name System)는 HTTP와 같이 응용 계층 시스템에서 도메인 이름과 IP주소 이름 확인을 제공합니다. 컴퓨터는 IP주소와는 별도로 호스트 이름과 도메인 이름을 붙일 수 있습니다. 컴퓨터는 IP주소와는 별도로 호스트 이름과 도메인 이름을 붙일 수 있습니다. DNS는 도메인명에서 IP주소를 조사하거나 반대로 IP주소로부터 도메인명을 조사하는 서비스를 제공하고 있습니다.


















{kind=link}