우리는 .persist를 해당 entity를 DB에 저장한다고 이해했다. 그렇지않고 우리는 entity를 DB에 저장하는 것이 아닌 영속성 컨텍스트에 저장하는 것이다.
영속성 컨텍스트는 논리적인 개념이다.
눈에 보이지 않는다.
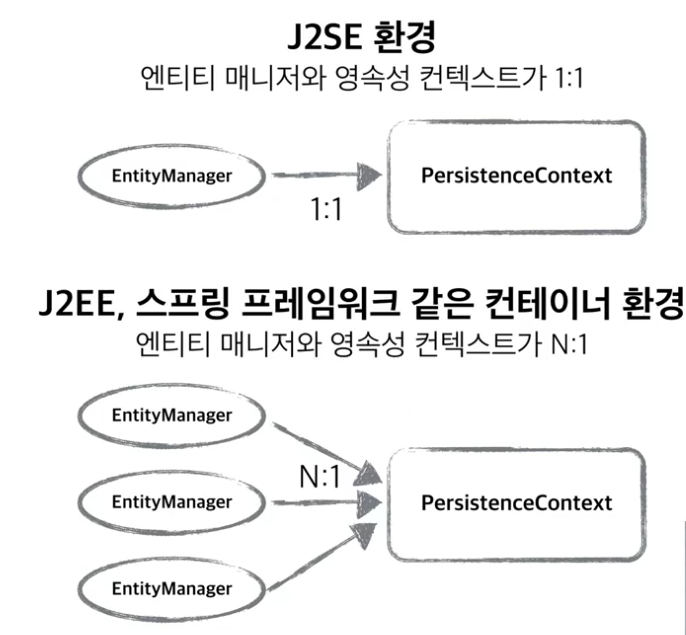
엔티티 매니저를 통해서 영속성 컨텍스트에 접근
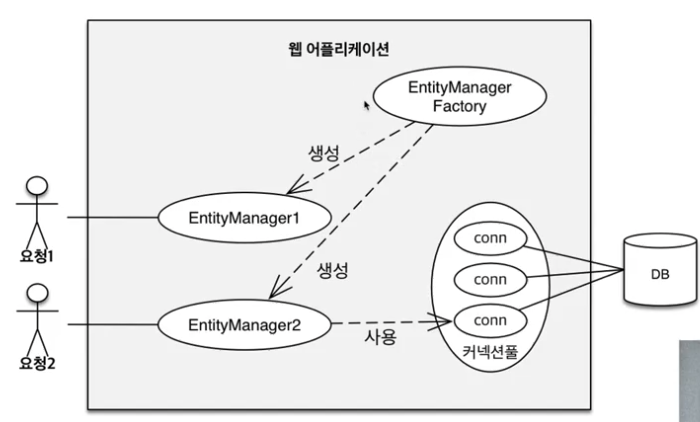
영속성 컨텍스트 생성 과정
EntityManasger를 생성하면 위 그림 처럼 영속성 컨텍스트가 생성됩니다.
엔티티의 생성주기
비영속(new/transient)
영속성 컨텍스트와 전혀 관계가 없는 새로운 상태
영속(managed)
영속성 컨텍스트에 관리되는 상태
준영속(detached)
영속성 컨텍스트에 저장되었다가 분리된 상태
삭제(removed)
삭제된 상태
비영속 상태(JPA랑 전혀 관계 없는 상태)
영속
DB에는 언제 저장하는가?
em.persist(member);
위의 상태에서는 DB에 저장한 것이 아닌 영속성 컨텍스트에 저장한 것이다. 그렇다면 언제 DB에 저장하는 것 인가?
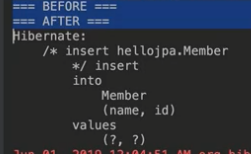
확인 코드
System.out.print("=== before ===");
em.persist(member);
System.out.print("=== after ===");
결과 : before와 after사이에 insert문이 날라가지 않는다.
이유
tx.commit;
트랜잭션 커밋 상태에서 결국 query가 날라가게 된다.
준영속, 삭제
회원 엔티티를 영속성 컨텍스트에서 분리, 준영속 상태
em.detach(member);
객체를 삭제한 상태
em.remove(member);
영속성 컨텍스트의 이점
바로 db에 저장하지 않고 중간과정을 거친다. 그래서 얻는 것은 다음과 같다.
1차 캐시
동일성 보장
트랜잭션을 지원하는 쓰기 지연
변경 감지
지연 로딩
엔티티 조회, 1차 캐시
1차 캐시로 저장하고 db에 저장한다.
어느 시점에? 트랜잭션
데이터베이스에서 조회
단, 한 트랜잭션안에서만 동작하기 때문에 큰 이점은 없다. 즉, 트랜잭션이 끝나면 휘발성으로 날라간다. 우리가 아는 캐싱을 적용하려면 2차캐싱을 적용해야한다.
영속 엔티티의 동일성 보장
1차 캐시로 반복 가능한 읽기(Repeatable read) 등급의 트랜잭션 격리 수준을 데이터베이스가 아닌 애플리케이션 차원에서 제공
엔티티 등록 트랜잭션을 지원하는 쓰기 지연
1차 캐시에 저장과 동시에 INSERT SQL 생성하여 쓰기 지연 SQL 저장소에 저장한다.
그리고 transactio.commit();을 만나면 flush가 되면서 db에 날라가고 commit이 된다.
jpa batch 라는 것으로 size를 관리한다.
약간 bulk insert 같은 느낌으로 버퍼를 모으는 느낌
★엔티티 수정 변경 감지(Drity Checking)★
EntityManager em = emf.createENtityManager();
EntityTransaction tr = em.getTransaction();
tr.begin(); //트랜잭션 시작
//영속 엔티티 조회
Member memberA = em.find(Member.class, "memberA");
//영속 엔티티 데이터 수정
MemberA.setUserName("hi");
MemberA.setAge(10);
//em.update(member) 이런 코드가 있어야 하지 않을까?
tr.commit(); //트랜잭션 커밋
위의 코드를 보면 memberA라는 객체에 setName, setAge를 해주고 update 쿼리를 해주지 않았는데도 자동으로 update가 된다. 왜그럴까? 뭔가 set을 해주고 persist를 해줘야 반영이 될 것 같은데 말이다.
1차 캐시안에는 @Id, Entity, 스냅샷이라는 것이 있다. 스냅샷은 최초로 영속성 컨텍스트에 들어온 값을 임시 저장하는 것이다. 그러고 Entity(새로 들어온 값) 스냅샷과 변경이 감지되면 update 쿼리를 쓰기 지연 SQL 저장소에 저장해버리고 DB에 반영한다.
플러시
영속성 컨텍스트의 변경내용을 데이터베이스에 반영
플러시 발생
변경 감지
수정된 엔티티 쓰기 지연 SQL 저장소에 등록
쓰기 지연 SQL 저장소의 쿼리를 데이터베이스에 전송
등록, 수정, 삭제 쿼리
영속성 컨텍스트를 플러시 하는 방법
em.flush() - 직접 호출 트랜잭션 커밋 전에 강제 느낌 (거의 사용x)
트랜잭션 커밋 - 플러시 자동 호출
JPQL 쿼리 실행 - 플러시 자동 호출
em.persist(memberA);
em.persist(memberB);
em.persist(memberC);
// 중간에 JPQL 실행
query = em.createQuery("select m from Member m", member.class);
List<Member> members = query.getResultList();
em.persist의 memberA,B,C는 아직 데이터베이스에 Insert 전이다.
따라서 select 문에서 조회가 안될 것 같지만, JPQL은 flush가 자동으로 된다. 그래서 조회가 된다.
flush 여부 설정 가능
FlushModeType.AUTO... or COMMIT
준영속 상태
영속 -> 준영속
영속 상태의 엔티티가 영속성 컨텍스트에서 분리(detached)
영속성 컨텍스트가 제공하는 기능을 사용 못함
거의 비영속 상태에 가깝다.
영속성 컨텍스트가 관리하지 않으므로 1차 캐시, 쓰기 지연, 변경 감지, 지연 로딩을 포함한 영속성 컨텍스트가 제공하는 어떤한 기능도 동작하지 않는다.
식별자 값을 가지고 있다.
비영속 상태는 식별자 값이 없을 수도 있지만 준영속 상태는 이미 한 번 영속상태였으므로 반드시 식별자 값을 가지고 있다
지연 로딩을 할 수 없다.
//1 : 떼어내기
em.detach(member);
tx.commit();//commit을 해도 em은 반영되지 않는다.
//2 1차 캐시를 조회함 그래서 같은 내용 또 조회해도 select 쿼리가 또 나감
em.clear();
//3. em.close() : 종료
2014년에 발표된 자바의 최신 버전인 Java SE 8 버전에서는 많은 사항이 변경되거나 새롭게 추가되었습니다.
Java SE 8에서 변경되거나 새롭게 추가된 사항 중에서 주목할 만한 특징은 다음과 같습니다.
람다 표현식(Lambda Expression)
람다 표현식(lambda expression)이란 간단히 말해 메소드를 하나의 식으로 표현한 것입니다.
즉, 식별자 없이 실행할 수 있는 함수 표현식을 의미하며, 따라서 익명 함수(anonymous function)라고도 부릅니다.
메소드를 이렇게 람다 표현식으로 표현하면 클래스를 만들고 객체를 생성하지 않아도 메소드를 사용할 수 있습니다.
또한, 람다 표현식은 메소드의 매개변수로 전달될 수도 있고, 메소드의 결괏값으로 반환될 수도 있습니다.
이러한 람다 표현식은 기존의 불필요한 코드를 줄여주고, 작성된 코드의 가독성을 높이는 데 그 목적이 있습니다.
Java SE 8 버전부터는 람다 표현식을 사용하여 자바에서도 함수형 프로그래밍을 할 수 있게 되었습니다.
다음 예제는 전통적인 방식의 스레드 생성과 람다 표현식을 사용한 스레드 생성을 비교하는 예제입니다.
new Thread(new Runnable() {
public void run() {
System.out.println("전통적인 방식의 일회용 스레드 생성");
}
}).start();
//람다식 사용
new Thread(()->{
System.out.println("람다 표현식을 사용한 일회용 스레드 생성");
}).start();
스트림 API(Stream API)
자바에서는 많은 양의 데이터를 저장하기 위해서 배열이나 컬렉션을 사용합니다.
또한, 이렇게 저장된 데이터에 접근하기 위해서는 반복문(for문)이나 반복자(iterator)를 사용하여 매번 코드를 작성해야 했습니다.
하지만 이렇게 작성된 코드는 길이가 너무 길고 가독성도 떨어지며, 코드의 재사용이 거의 불가능합니다.
또한, 데이터베이스의 쿼리와 같이 정형화된 처리 패턴을 가지지 못했기에 데이터마다 다른 방법으로 접근해야만 했습니다.
이러한 문제점을 극복하기 위해서 Java SE 8 버전부터 도입된 방법이 바로 스트림(stream) API입니다.
스트림 API는 데이터를 추상화하여 다루므로, 다양한 방식으로 저장된 데이터를 읽고 쓰기 위한 공통된 방법을 제공합니다.
따라서 스트림 API를 이용하면 배열이나 컬렉션뿐만 아니라 파일에 저장된 데이터도 모두 같은 방법으로 다룰 수 있습니다.
String[] arr = new String[]{"넷", "둘", "셋", "하나"};
// 배열에서 스트림 생성
Stream<String> stream1 = Arrays.stream(arr);
stream1.forEach(e -> System.out.print(e + " "));
System.out.println();
// 배열의 특정 부분만을 이용한 스트림 생성
Stream<String> stream2 = Arrays.stream(arr, 1, 3);
stream2.forEach(e -> System.out.print(e + " "));
java.time 패키지
JDK 1.0에서는 Date 클래스를 사용하여 날짜에 관한 처리를 수행했습니다.
하지만 Date 클래스는 현재 대부분의 메소드가 사용을 권장하지 않고(deprecated) 있습니다.
JDK 1.1부터 새롭게 제공된 Calendar 클래스는 날짜와 시간에 대한 정보를 얻을 수는 있지만, 다음과 같은 문제점을 가지고 있습니다.
브라우저 렌더링 과정을 알아보기전에 브라우저가 무엇인지 먼저 알아보자. 우선 브라우저는 우리가 흔히 인터넷에 접속할 때 사용하는 Chrome, Safari, Firefox, Internet Explorer 등을 말한다.
MDN에서는 브라우저에 대해 웹에서 페이지를 찾아서 보여주고, 사용자가 하이퍼링크를 통해 다른 페이지로 이동할 수 있도록 하는 프로그램이라고 설명하고 있다. 여기서 중요하다고 생각하는 부분은 찾아서 보여준다는 것이다.
브라우저는 유저가 선택한 자원을 서버로 부터 받아와서 유저에게 보여준다. 이 자원은 페이지 외에도 이미지, 비디오 등의 컨텐츠들도 포함된다. 받아온 자원들을 렌더링 과정을 통해 유저에게 보여주게 된다.
브라우저 렌더링 동작 과정
렌더링의 기본적인 동작 과정은 다음과 같다.
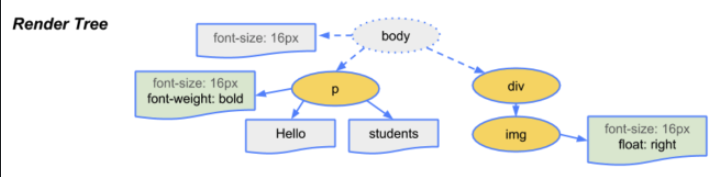
HTML 파일과 CSS 파일을 파싱해서 각각 Tree를 만든다. (Parsing)
두 Tree를 결합하여 Rendering Tree를 만든다. (Style)
Rendering Tree에서 각 노드의 위치와 크기를 계산한다. (Layout)
계산된 값을 이용해 각 노드를 화면상의 실제 픽셀로 변환하고, 레이어를 만든다. (Paint)
레이어를 합성하여 실제 화면에 나타낸다. (Composite)
각 단계를 좀 더 자세하게 알아보자.
Parsing
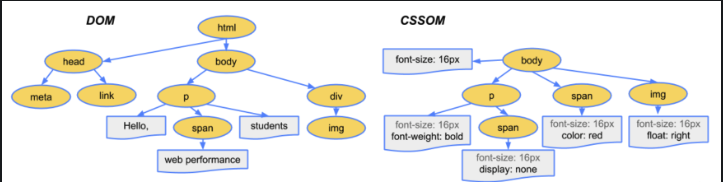
브라우저가 페이지를 렌더링하려면 가장 먼저 받아온 HTML 파일을 해석해야한다. Parsing 단계는 HTML 파일을 해석하여 DOM(Document Object Model) Tree를 구성하는 단계이다. 파싱 중 HTML에 CSS가 포함되어 있다면 CSSOM(CSS Object Model) Tree 구성 작업도 함께 진행한다.
-> 서버에서 받아온 HTML, CSS 파일을 분석하여 DOM Tree와 CSSOM Tree를 구성한다.
만약 파싱 도중에 자바스크립트 코드를 만나면 ?
자바스크립트는 렌더링 엔진이 아닌 자바스크립트 엔진이 처리한다. HTML 파서는 script 태그를 만나면 자바스크립트 코드를 실행하기 위해 DOM 생성 프로세스를 중지하고 자바스크립트 엔진으로 제어 권한을 넘긴다. 제어 권한을 넘겨 받은 자바스크립트 엔진은 script 태그 내의 자바스크립트 코드 또는 script 태그의 src 어트리뷰트에 정의된 자바스크립트 파일을 로드하고 파싱하여 실행한다. 자바스크립트의 실행이 완료되면 다시 HTML 파서로 제어 권한을 넘겨서 브라우저가 중지했던 시점부터 DOM 생성을 재개한다.
이처럼 브라우저는동기(Synchronous)적으로 HTML, CSS, Javascript을 처리한다. 이것은 script 태그의 위치에 따라 블로킹이 발생하여 DOM의 생성이 지연될 수 있다는 것을 의미한다. 따라서 script 태그의 위치는 중요한 의미를 갖는다. body 요소의 가장 아래에 자바스크립트를 위치시키는 것은 좋은 아이디어이다. 그 이유는 아래와 같다.
HTML 요소들이 스크립트 로딩 지연으로 인해 렌더링에 지장 받는 일이 발생하지 않아 페이지 로딩 시간이 단축된다.
DOM이 완성되지 않은 상태에서 자바스크립트가 DOM을 조작한다면 에러가 발생한다.
Style
Style 단계에서는 Parsing 단계에서 생성된 DOM Tree와 CSSOM Tree를 매칭시켜서 Render Tree를 구성한다. Render Tree는 실제로 화면에 그려질 Tree이다. 예를 들면 Render Tree를 구성할때visibility: hidden은 요소가 공간을 차지하고, 보이지만 않기 때문에 Render Tree에 포함이 되지만,display: none의 경우 Render Tree에서 제외된다.
-> DOM Tree + CSSOM Tree = Render Tree로 구성한다.
Layout
Layout 단계에서는 Render Tree를 화면에 어떻게 배치해야 할 것인지 노드의 정확한 위치와 크기를 계산한다. 루트부터 노드를 순회하면서 노드의 정확한 크기와 위치를 계산하고 Render Tree에 반영한다. 만약 크기 값을 %로 지정하였다면, Layout 단계에서 % 값을 계산해서 픽셀 단위로 변환한다.
Paint
계산된 값을 이용해 각 노드를 화면상의 실제 픽셀로 변환하고, 레이어를 만든다.Paint 단계에서는 Layout 단계에서 계산된 값을 이용해 Render Tree의 각 노드를 화면상의 실제 픽셀로 변환한다. 이때 픽셀로 변환된 결과는 하나의 레이어가 아니라 여러 개의 레이어로 관리된다. 당연한 말이지만 스타일이 복잡할수록 Paint 시간도 늘어난다. 예를 들어, 단색 배경의 경우 시간과 작업이 적게 필요하지만, 그림자 효과는 시간과 작업이 더 많이 필요하다.
Composite
Composite 단계에서는 Paint 단계에서 생성된 레이어를 합성하여 실제 화면에 나타낸다. 우리는 화면에서 웹 페이지를 볼 수 있다.
정리
주소창에 구글 입력 .
구글 서버로 찾아간다.
*DNS가 연결해줄 곳을 찾음
서버에서 HTML 파일을 클라이언트로 보냄.
HTML 파일 파싱 및 DOM Tree 생성
link 태그를 만나 css 파싱 및 CSSOM 트리 생성
DOM , CSSOM 합쳐 Render Tree 생성 (8. JavaScript를 만나면? HTML파서는 JS 코드를 실행하기 위해 파싱 중단
소프트웨어 디자인 패턴에서 싱글턴 패턴을 따르는 클래스는, 생성자가 여러 차례 호출되더라도 실제로 생성되는 객체는 하나이고 최초 생성 이후에 호출된 생성자는 최초의 생성자가 생성한 객체를 리턴한다.
싱글턴 패턴을 사용하는 이유
만약 우리가 만들었던 DI 컨테이너인 요청을 할 때마다 새로운 객체를 생성한다. 요청이 엄청나게 많은 트래픽 사이트에서는 계속 객체를 생성하게 되면 메모리 낭비가 심하기 때문이다.
스프링 컨테이너
스프링 컨테이너는 싱글턴 패턴을 적용하지 않아도 객체 인스턴스를 싱글톤으로 관리한다. 이러한 기능 덕분에 싱글톤 패턴의 모든 단점을 해결하고 객체를 싱글톤으로 유지할 수 있다
Spring에서 싱글톤을 사용하는 이유
애플리케이션컨텍스트에 의해 등록된 빈은 기본적으로 싱글톤으로 관리된다. 즉, 스프링에여러 번 빈을 요청하더라도 매번 동일한 객체를 돌려준다는 것이다. 애플리케이션 컨텍스트가 싱글톤으로 빈을 관리하는 이유는 대규모 트래픽을 처리할 수 있도록 하기 위함이다.
스프링은 최초에 설계될 때 부터 대규모의 엔터프라이즈 환경에서 요청을 처리할 수 있도록 고안되었다. 그리고 그에 따라 계층적으로 처리 구조(Controller, Service, Repository 등) 가 나뉘어지게 되었다.
그런데 매번 클라이언트에서 요청이 올 때마다 각 로직을 처리하는 빈을 새로 만들어서 사용한다고 생각해보자. 요청 1번에 5개의 객체가 만들어진다고 하고, 1초에 500번 요청이 온다고 하면 초당 2500개의 새로운 객체가 생성된다. 아무리 GC의 성능이 좋아졌다 하더라도 부하가 걸리면 감당이 힘들 것이다.
그래서 이러한 문제를 해결하고자빈을 싱글톤 스코프로 관리하여 1개의 요청이 왔을 때 여러 쓰레드가 빈을 공유해 처리하도록 하였다.
Spring에서 관리하는 싱글톤의 장점
Java로 기본적인 싱글톤 패턴을 구현하고자 하면 다음과 같은 단점들이 발생한다.
private 생성자를 갖고 있어 상속이 불가능하다.
싱글톤으로 생성되면 객체테스트가 어렵기 때문에, 테스트를 위한 객체를 새로만들어야한다.
서버 환경에서는 싱글톤이 1개만 생성됨을 보장하지 못한다.
전역 상태를 만들 수 있기 때문에 바람직하지 못하다.
기본적으로 싱글톤이 멀티쓰레드 환경에서 서비스 형태의 객체로 사용되기 위해서는 내부에 상태정보를 갖지 않는 무상태(Stateless) 방식으로 만들어져야 한다. 만약 여러 쓰레드들이 동시에 상태를 접근하여 수정한다면 상당히 위험하기 때문이다.
직접 싱글톤을 구현한다면 상당히 많은 단점들이 있겠지만, Spring 프레임워크에서 직접 싱글톤으로 객체를 관리해주므로, 우리는 더욱 객체지향적인 개발을 할 수 있게 된 것이다.
싱글턴 방식의 주의점 ✨
싱글톤 패턴이든, 스프링에서 객체 인스턴스를 하나만 생성해서 공유하는 상황에서 객체 인스턴스를 공유하기 때문에 객체 상태를 유지(stateful)하게 설계하면 안된다. 1. price는 공유되는 필드이기 때문에 특정 클라이언트가 값을 변경한다. 2. 실무에서 이런 경우를 종종 보는데, 이로인해 정말 해결하기 어려운 큰 문제들이 터진다.(몇년에 한번씩 꼭 만난다.)
stateless(무상태)방식으로 만들어라.
읽기전용 값이라면 초기화시점에서 iv에 저장해두고 공유하는 것은 문제가 없지만, 다중 사용자의 요청을 한꺼번에 처리하는 쓰레드들이 동시에 iv를 건드리는 것은 위험하다. 따라서 stateless방식으로 만들어져야한다.
파라미터, 로컬변수, 리턴값 등을 이용해, 각각의 값을 iv처럼 공유되는 영역이 아닌, 독립적인 영역에 저장하자.
싱글톤 레지스트리
그래서스프링은직접 싱글톤 형태의 오브젝트를 만들고 관리하는 기능을 제공하는데, 그것이 바로싱글톤 레지스트리(Singleton Registry)이다. 스프링 컨테이너는 싱글톤을 생성하고, 관리하고 공급하는 컨테이너이기도 하다. 싱글톤 레지스트리의 장점은 다음과 같다.
static 메소드나 private 생성자 등을 사용하지 않아 객체지향적 개발을 할 수 있다.
테스트를 하기 편리하다.
이러한 스프링에장점을 활용하여 초기에 설정하면 사용중에는 변하지않는읽기전용 인스턴스 변수인경우에는 서버의성능향상을 위해 bean으로 등록하고 사용하자.
한 테이블에 있는 모든 로우는 같은 길이의 칼럼을 가지고 있으며 이 칼럼의 구조와 데이터의 관계가테이블 스키마(Schema)로 사전 정의된다.분류, 정렬, 탐색 속도가 빠르다. SQL은 고도로 정교한 검색 쿼리를 제공하며 상상하는 거의 모든 방식으로 데이터를 다룰 수 있게 해 준다. 또한 트랜잭션(Transaction) 지원이 매우 강력하여 신경만 제대로 써주면 데이터가 안 들어가는 경우는 있어도 잘못 들어가는 경우는 없다. 그 어떤 상황에서도데이터 무결성을 '보장'하는 것이 RDBMS의 특징이다.
다만부하분산이 잘 되지 않는다.읽기 작업은 분산이 되지만 쓰기 작업을 분산하려면 고도의 기술력에 더해 전략까지 필요하다.
위에서 DBMS는 사용자와 데이터베이스 사이에서 사용자의 요구에 따라 정보를 생성해주고 데이터베이스를 관리해 주는 소프트웨어라고 설명을 했습니다. 또한 기존의 RDBMS에서의 저장 방식은 SQL에 의해 저장되고 있으며 정해진 스키마에 따라 데이터를저장하여야 합니다. RDBMS에는 DBMS앞에 R이 붙어 있습니다. 이 R은(Relational)의 약자로 RDBMS는 관계형 데이터베이스 관리 시스템을 의미합니다. 이름과 같이 RDBMS는 RDB를 관리하는 시스템이며 RDB는 관계형 데이터 모델을 기초로 두고 모든 데이터를 2차원 테이블 형태로 표현하는 데이터베이스입니다.
관계형 데이터베이스(RDMBS)는 아래와와 같이 구성된 테이블이 다른 테이블들과 관계를 맺고 모여있는 집합체로 이해할 수 있습니다.
관계형 데이터베이스(RDMBS)에서는 이러한 관계를 나타내기 위해외래 키(foreign key)라는 것을 사용합니다.
이러한 테이블간의 관계에서 외래 키를 이용한 테이블 간 Join이 가능하다는 게 RDBMS의 가장 큰 특징입니다.
만약 성능향상을 원한다면 : Scale-Up을 해야함.
장점
범용적이며 고성능
데이터의 일관성을 보증할 수 있음
한 번에 이뤄져야 하는 작업의 경우 데이터 불일치 상황 방지 (데이터 무결성 보장) → 데이터베이스 설계 시 이미 불필요한 중복이 삭제됨
정규화를 전제로 하고 있기 때문에 업데이트 시 비용이 적음(동일 컬럼은 동일 장소에 존재)
복잡한 형태의 쿼리도 가능(Join 등)
단점
대량의 데이터 입력 처리 어려움
테이블의 인덱스 생성이나 스키마 변경 어려움
어떤 상황에 사용할까?
대부분의 경우에 관계형 데이터베이스를 사용하는 것이 안정적이다.
관계를 맺고 있는 데이터가 자주 변경(수정)되는 어플리케이션일 경우
변경될 여지가 없고, 명확한 스키마가 사용자와 데이터에게 중요한 경우
NoSQL
NoSQL이란(Not Only SQL)의 약자로 말 그대도 위에서 설명한 RDB 형태의 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 의미하고 있습니다. 또한 NoSQL에서는 RDBMS와는 달리 테이블 간 관계를 정의하지 않습니다. 데이터 테이블은 그냥 하나의 테이블이며 테이블 간의 관계를 정의하지 않아 일반적으로 테이블 간 Join도 불가능합니다.
NoSQL은 점점 빅데이터의 등장으로 인해 데이터와 트래픽이 기하급수적으로 증가함에 따라 RDBMS에 단점인 성능을 향상시키기 위해서는 장비가 좋아야 하는 Scale-Up의 특징이 비용을 기하급수적으로 증가시키기 때문에 데이터 일관성은 포기하되 비용을 고려하여 여러 대의 데이터에 분산하여 저장하는 Scale-Out을 목표로 등장하였습니다.
성능향상을 원한다면 분산 저장 방식 : Scale-Out을 해야함.
NoSQL을 하면 가장 유명한 Document 기반의 MongoDB를 많이 떠올리지만 MongoDB는 NoSQL한 종류로 NoSQL은 하기와 같이 다양한 형태의 저장 기술을 지원하고 있습니다.
이 다양한 형태의 저장기술은 RDBMS 스키마에 맞추어 데이터를 관리해야 된다는 한계를 극복하고 수평적 확장성(Scale-out)을 쉽게 할 수 있다는 장점을 가지고 있습니다.
NoSQL이라고 해서 RDBMS 제품군(MS-SQL, Oracle, Sybase, MySQL) 등과 같이 공통된 형태의 데이터 저장 방식(테이블)과 접근 방식(SQL)을 갖는 제품군이 아니라 RDBMS와 다른 형태의 데이터 저장 구조를 총칭하며, 제품에 따라 각기 그 특성이 매우 달라서 NoSQL을 하나의 제품군으로 정의할 수는 없다.
RDBMS의 복잡도와 용량 한계를 극복하기 위한 목적으로 등장한 만큼, 페타바이트급의 대용량 데이터를 저장할 수 있다. 기본적으로 NoSQL의join연산은 대부분 불가능하다. 즉, 데이터 모델 자체가 독립적으로 설계되어 있어 데이터를 여러 서버에 분산시키는 것이 용이하다. 분산형 구조를 통해 데이터를 여러 대의 서버에분산해 저장하고, 분산 시에 데이터를상호 복제해 특정 서버에 장애가 발생했을 때에도 데이터 유실이나 서비스 중지가 없는 형태이다. ID 필드는 공통이지만, 데이터를 저장하는컬럼은 각기 다른 이름과 다른 데이터 타입을 가질 수 있다.
NoSQL 특징
1. Key-Value Database
Key-Value Database는 데이터가 Key와 Value의 쌍으로 저장된다. Key는 Value에 접근하기 위한 용도로 사용되며, 값은 어떠한 형태의 데이터라도 담을 수 있다. 심지어는 이미지나 비디오도 가능하다. 또한 간단한 API를 제공하는 만큼 질의의 속도가 굉장히 빠른 편이다.
대표적인 NoSQL Key-Value Model로는Redis, Riak, Amazon Dynamo DB 등이 있다.
2. Document Database
Documnet Database 데이터는 Key와Document의 형태로 저장된다. Key-Value 모델과 다른 점이라면 Value가 계층적인 형태인 도큐먼트로 저장된다는 것이다. 객체지향에서의 객체와 유사하며, 이들은 하나의 단위로 취급되어 저장된다. 다시 말해 하나의 객체를 여러 개의 테이블에 나눠 저장할 필요가 없어진다는 뜻이다.
주요한 특징으로는 객체-관계 매핑이 필요하지 않다. 객체를 Document의 형태로 바로 저장 가능하기 때문이다. 또한 검색에 최적화되어 있는데, 이는 Ket-Value 모델의 특징과 동일하다. 단점이라면 사용이 번거롭고 쿼리가 SQL과는 다르다는 점이다. 도큐먼트 모델에서는 질의의 결과가 JSON이나 xml 형태로 출력되기 때문에 그 사용 방법이 RDBMS에서의 질의 결과를 사용하는 방법과 다르다.
대표적인 NoSQL Document Model로는 MongoDB, CouthDB 등이 있다.
3. Wide Column Database
Column-family Model 기반의 Database이며이전의 모델들이 Key-Value 값을 이용해 필드를 결정했다면, 특이하게도 이 모델은 키에서 필드를 결정한다. 키는 Row(키 값)와 Column-family, Column-name을 가진다. 연관된 데이터들은 같은 Column-family 안에 속해 있으며, 각자의 Column-name을 가진다. 관계형 모델로 설명하자면 어트리뷰트가 계층적인 구조를 가지고 있는 셈이다. 이렇게 저장된 데이터는 하나의 커다란 테이블로 표현이 가능하며, 질의는 Row, Column-family, Column-name을 통해 수행된다.
대표적인 NoSQLColumn-family Model로는HBase,Hypertable 등이 있다.
4. Graph Database
Graph Model Model에서는 데이터를 Node와 Edge, Property와 함께 그래프 구조를 사용하여 데이터를 표현하고 저장하는 Database입니다.개체와 관계를 그래프 형태로 표현한 것이므로 관계형 모델이라고 할 수 있으며, 데이터 간의 관계가 탐색의 키일 경우에 적합하다. 페이스북이나 트위터 같은 소셜 네트워크에서(내 친구의 친구를 찾는 질의 등) 적합하고, 연관된 데이터를 추천해주는 추천 엔진이나 패턴 인식 등의 데이터베이스로도 적합하다.
대표적인 NoSQL Graph Model로는 Neo4J가 있다.
RDBMS와 NoSQL의 장단점
RDBMS
장점
RDBMS는 위에서 설명을 하였듯이 정해진 스키마에 따라 데이터를 저장하여야 하므로 명확한 데이터 구조를 보장하고 있습니다.
또한 관계는 각 데이터를 중복없이 한 번만 저장할 수 있습니다.
단점
테이블간테이블 간 관계를 맺고 있어 시스템이 커질 경우 JOIN문이 많은 복잡한 쿼리가 만들어질 수 있습니다.
성능 향상을 위해서는 서버의 성능을 향상 시켜야하는 Scale-up만을 지원합니다. 이로 인해 비용이 기하급수적으로 늘어날 수 있습니다.
스키마로 인해 데이터가 유연하지 못합니다. 나중에 스키마가 변경 될 경우 번거롭고 어렵습니다.
NoSQL
장점
NoSQL에서는 스키마가 없기 때문에 유연하며 자유로운 데이터 구조를 가질 수 있습니다. 언제든 저장된 데이터를 조정하고 새로운 필드를 추가할 수 있습니다.
데이터 분산이 용이하며 성능 향상을 위한 Saclue-up 뿐만이 아닌 Scale-out 또한 가능합니다.
빠른쿼리
수평적 확장
데이터 분산에 용이
단점
데이터 중복이 발생할 수 있으며 중복된 데이터가 변경 될 경우 수정을 모든 컬렉션에서 수행을 해야 합니다.
스키마가 존재하지 않기에 명확한 데이터 구조를 보장하지 않으며 데이터 구조 결정가 어려울 수 있습니다.
RDBMS, NoSQL 언제 사용해야 될까요?
RDBMS는 데이터 구조가 명확하며 변경 될 여지가 없으며 명확한 스키마가 중요한 경우 사용하는 것이 좋습니다. 또한 중복된 데이터가 없어(데이터 무결성) 변경이 용이하기 때문에 관계를 맺고 있는 데이터가 자주 변경이 이루어지는 시스템에 적합합니다.
NoSQL은 정확한 데이터 구조를 알 수 없고 데이터가 변경/확장이 될 수 있는 경우에 사용하는 것이 좋습니다. 또한 단점에서도 명확하듯이 데이터 중복이 발생할 수 있으며 중복된 데이터가 변경될 시에는 모든 컬렉션에서 수정을 해야 합니다. 이러한 특징들을 기반으로 Update가 많이 이루어지지 않는 시스템이 좋으며 또한 Scale-out이 가능하다는 장점을 활용해 막대한 데이터를 저장해야 해서 Database를 Scale-Out를 해야 되는 시스템에 적합합니다.
데이터에 대한 캐시가 필요한 경우
배열 형식의 데이터를 고속으로 처리할 필요가 있는 경우
막대한 양의 데이터를 다뤄야 하는 경우
읽기 처리를 자주하지만, 데이터를 자주 변경하지 않는 경우
라인이 NoSQL 선택한 이유는?
RDBMS
일반 RDBMS 방식을 채택한 SQL 방식은 구조를 한 번 고정시키면, 데이터와 구조의 안정성은 보장된다. 일정한 형식을 유지해, 보기에도 편하고 훨씬 직관적이다. 하지만 데이터가 쌓일수록 데이터베이스 관리 시스템 자체가 커지는 구조를 갖고 있다. 이 때문에 시간이 지나면 훨씬 고성능의 데이터베이스 시스템을 필요로 하게 되고, 점점 관리가 어려워진다.
NoSQL NoSQL은 대량의 데이터를 무한대로 추가하여 저장할 수 있으며, 가변성이 있는 데이터의 저장도 용이하다. 결과적으로 유지 보수에 적은 비용이 발생한다. 그러나 구조가 정해지지 않았기에 분별되지 못한 여러 데이터가 떠다니는 문제가 발생할 수도 있고, 알아보기 어려운 형태를 가진 데이터를 다뤄야 하는 것이 단점이 될 수 있겠다.
금융 업계처럼 보수적이거나 저장해야 하는 데이터들이 고정적인 경우 RDBMS를 사용하는 것이 더 좋다. 반대로 웹이나 다량의 데이터를 한꺼번에 처리해야하는 메신저는 NoSQL 방식이 더 유리하다고 볼 수 있다.
라인 개발팀은 최대한 빠른 서비스 오픈, 글로벌 서비스에 적합한 규모 확장성과 비용 효율성을 달성하기 위해 NoSQL을 도입했다고 밝혔다. 메시지 서비스 특성상 대규모 서비스는 각자 자사 기술에 최적화된 아키텍처를 채용하는 것이 맞고, 규모 확장에 따른 위험을 줄일 수 있기 때문이다. 메시지 서비스 사업은 범용성을 위해서라도 RDBMS를 채택하는 경우가 많은데, 라인은 NoSQL을 선택하면서 비용 절감 효과를 누렸다.
그렇다면, 국내 최대 메신저 서비스, 카카오톡은 어떨까? 카카오톡은 RDBMS 방식으로 수천대에 이르는 오라클 MySQL을 이용하고 있으며 DELL, HP사의 서버도 같이 이용하고 있다.
그러나 사용자가 점점 많아지면서 카카오톡 내부에서 제공하는 서비스 사용량도 점점 증가한다는 문제가 발생하고 있다. 이러한 이유로 지금의 아키텍처로 서비스를 계속하는 데 무리가 있는 것이 아닌가라는 지적도 나오고 있다.
누적되는 데이터가 많아질수록 데이터베이스 관리에 비용이 많이 소요되고, 데이터베이스 연결 오류가 발생할 위험도 높아진다. 카카오톡 내부에서도 NoSQL 도입을 검토해보는 의견이 나오고 있지만, 쉽지 않은 것으로 알려져있다. 작업 수행이 완료된 쿼리가 삭제되어야 하는데, 쿼리들이 한 쪽에 쌓여 트래픽에 문제를 주는 상황이 발생할 수 있기 때문이다. 라인이 택한 NoSQL 방식의 데이터베이스 관리 시스템이 앞으로도 다양한 장점을 보여줄 수 있을지 기대가 되는 바이다.
DATABASE Cache Server
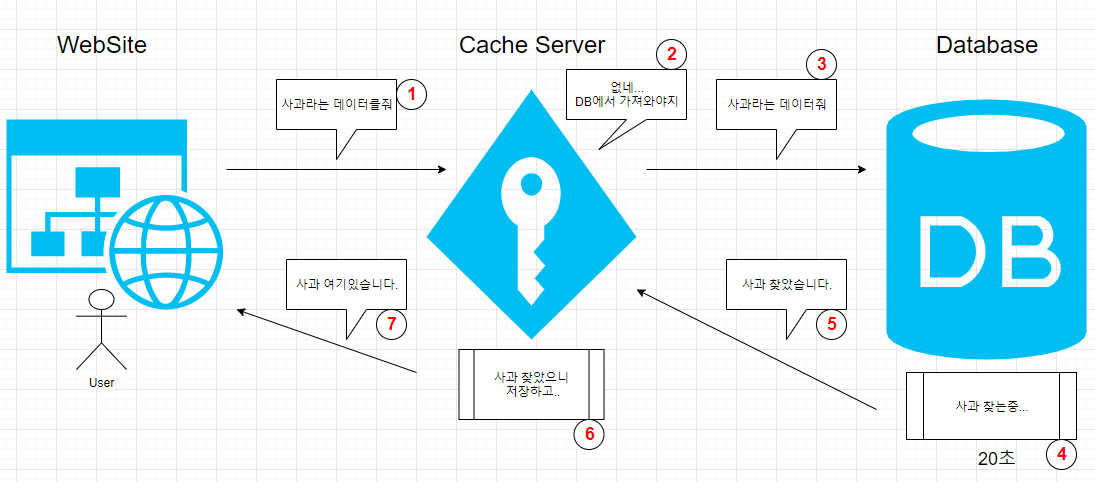
데이터베이스 데이터 캐싱 DB를 튜닝하고 다원화하고 좀 더 효율적으로 인덱스를 걸 수도 있겠지만 가장 근본적인 문제인 RDBMS로의 쿼리 전송을 줄이는 방법도 있을 수 있는데 데이터 캐싱을 통해 어느 정도 쿼리 전송을 줄일 수 있겠다. 데이터베이스에서의 데이터 캐싱이란 처음 쿼리를 전송할 때는 데이터베이스에서 직접 가져오지만 두 번째 쿼리부터는 캐시에 저장된 데이터를 가져와 데이터베이스까지 직접 쿼리를 전송하지 않아도 된다.
주로 데이터베이스에서 캐시용으로 NoSQL 류의 Redis나 Memcached를 사용한다. 두 DB 모두 디스크 기반이었던 기존의 RDBMS 들과 달리 메모리 기반이며 성능을 목적으로 개발되었기 때문에 캐시 서버로 주로 사용된다. (메모리 캐시라는 공통점 이외에는 다른 점이 더 많은 Redis와 Memcached이다.) 가장 기본적이고 단순한 Key-Value 형태로 메모리에 저장하고 또한 내부적으로도 성능에 목적을 둔 기능들이 많기 때문에 데이터 캐시 서버로 사용하기 매우 좋다.
메모리 캐시는 잘못 사용하면 성능이 더 안 좋아질 수도 있다고 한다. 보통 캐시에 들어갈 데이터는 자주 사용하는 데이터 위주로 저장해야 하고, 읽기는 많지만 쓰기는 적은 데이터 그리고 데이터의 양이 많지 않은 데이터를 캐싱 하는 것이 적합하다고 한다. 또한 캐시에도 데이터가 쌓이면 언젠가는 RDBMS와 다를 게 없어지므로 적절한 데이터 캐시 만료 기간을 설정해야 한다.
[데이터 캐싱이 적용된 시스템에서 CRUD]
캐시 서버가 사용되는 데이터베이스 시스템 구성도는 시스템 상황, 용도, 설계자의 캐싱 전력에 따라 달라질 수 있고 매우 다양하게 구성될 수 있으나 나는 가장 기본적인 개념을 설명하기 위해 DB 서버와 캐싱 서버 하나만 둔다. (캐싱 전략에도 방법론이 있고 공부할게 많다.)
- Read
캐시 서버에 데이터가 없는경우
캐시서버에 데이터가 있는경우
- Create : Database에 데이터를 생성한다.
- Update : Datebase에 데이터를 수정하고 캐시서버에도 데이터가 있다면 마찬가지로 수정한다.
- Delete : Database에 데이터를 삭제하고 캐시서버에도 데이터가 있다면 마찬가지로 삭제한다.
물론 캐싱이 만능은 아닐 것이다. 비용도 비용이지만, 제대로 사용하지 못하면, 최신으로 업데이트되지 않은 “틀린” 데이터를 클라이언트에게 제공할 수도 있고 비용이 최적화되지 않을 수도 있다. 가장 중요한 건 기존의 시스템에 정확히 어떤 부분에서 성능이 저하되는지를 주안점으로 두고 그에 대한 대처를 가장 효율적으로 하는 것이 좋지 않을까 싶다.
Spring 캐시 사용하기
Spring은 cache 관련 된 기능을 지원한다.
기존 cache 처리 memoryDB
Redis
Memcached
application 레벨 사용
EnCache
Spring cache
spring cache는 cache 기능의 추상화를 지원하는데, EnCache, COuchbase, Redis 등의 추가적인 캐시 저장소 연동하여 bean으로 설정 할 수 있도록 도와준다. 만일 추가적인 캐시 저장소와 연결하지 않는다면, CourrentHashMap 기반의 Map 저장소가 자동으로 추가된다. 캐시를 쓰긴 써야하는데, EnCache까지는 쓸 필요는 없고 간단하게 몇몇 토큰 정도만 캐시처리가 필요한 경우 사용하기 좋다.(=로컬캐시)
로컬 캐시 저장소이니 주의해야할 점은 application 간의 공유가 불가능하단 것이다. spring cache 를 사용하는 web application instance가 10대인 경우, 10대가 각각 캐시 저장소를 구성한다. 만일 10대 instance가 공유해야 하는 캐시 저장소인 경우, 외부의 redis, Memcahced를 이용하는게 맞다.
Simple Spring Memcached(SSM)
스프링에서 Memcache를 사용하려면 simple-spring-memcached(SSM) 라이브러리를 자주 이용합니다. SSM 어노테이션으로 메서드에 선언하면 쉽게 관련 데이터가 캐시에서 관리됩니다. 스프링에서도 버전 3.1부터는 캐시 서비스 추상화 기능이 지원되어 비즈니스 로직 변경 없이 쉽게 다양한 캐시 구현체(ex. Ehcache, Redis)로 교체가 가능하게 되었습니다. 스프링에서 제공하는 캐시 기능은 다른 포스팅에서 더 자세히 다루도록 하겠습니다.
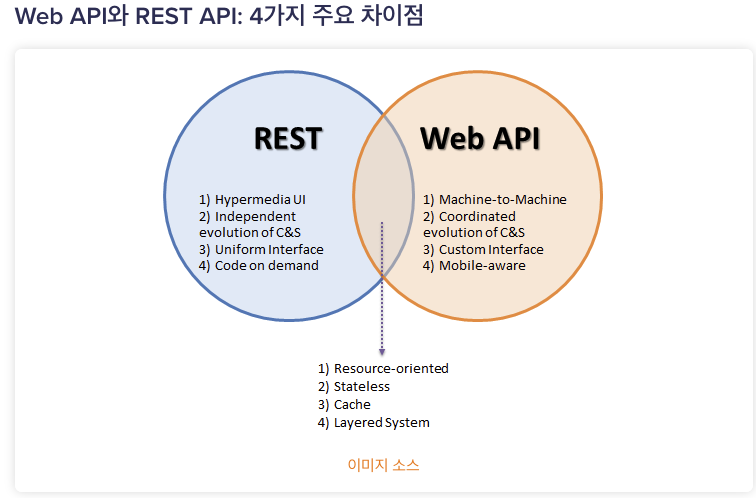
REST의 uniform interface를 지원하는 것은 쉽지 않기 때문에, 많은 서비스가 REST에서 바라는 것을 모두 지원하지 않고 API를 만들게 된다. REST API의 모든 스타일을 구현하지 못할 경우에는 Web API 혹은 Http API라고 부른다.
Web API 디자인 가이드
- URI는 정보의 자원을 표현해야 한다.
- 자원에 대한 행위는 HTTP Method(GET, POST, PUT, DELETE)로 표현한다.
웹 API의 이점
Web API는 분산 시스템에서 서비스를 제공하는 조직에 도움이 됩니다.다음은 웹 API의 몇 가지 이점입니다.
비즈니스:Web API는 오픈 소스이므로 일관된 비즈니스 데이터를 유지하기 위해 논리 중앙 집중화에 대한 복잡성을 줄입니다.저대역폭 데이터(JSON/XML)는 구문 분석이 쉽고 가벼우며 이상적인 데이터 교환 형식이므로 모든 언어와 통합할 수 있습니다.또한 Web API는 ASP.NET 프레임워크의 필수적인 부분이므로 유지 관리 및 이해가 매우 간단합니다.
기술:Web API의 주요 기술 이점 중 하나는 복잡한 구성이 필요하지 않다는 것입니다. 경량 아키텍처이기 때문에 대역폭이 제한된 장치(스마트폰)에 이상적입니다.OData(공개 데이터), 라우팅, 모델 바인딩 및 MVC와 유사한 유효성 검사를 지원합니다.
Web API와 REST API의 4가지 주요 차이점
1) 웹 API 대 REST API: 프로토콜
Web API는 서비스가 웹을 통해 다양한 클라이언트에 도달할 수 있도록 하는 HTTP/s 프로토콜 및 URL 요청/응답 헤더에 대한 프로토콜을 지원합니다.반면 REST API의 모든 통신은 HTTP 프로토콜을 통해서만 지원됩니다.
2) 웹 API 대 REST API: 형식
API는 동일한 작업을 수행하지만 Web API는 모든 통신 스타일에 유연성을 제공합니다.REST API는 통신을 위해REST, SOAP 및 XML-RPC를 사용할 수 있습니다.
3) 웹 API 대 REST API: 디자인
Web API는 경량 아키텍처이므로 스마트폰과 같은 장치에 제한된 가제트용으로 설계되었습니다.이와 대조적으로 REST API는 시스템을 통해 데이터를 송수신하여 복잡한 아키텍처를 만듭니다.
4) 웹 API 대 REST API: 지원
Web API는 IIS(인터넷 정보 서비스)또는 XML 및 JSON 요청을 지원하는 자체에서만 호스팅될 수 있습니다 .대조적으로 REST API는 표준화된 XML 요청을 지원하는 IIS에서만 호스팅될 수 있습니다.