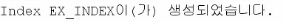@ComponentScan 애노테이션은 spring 3.1부터 도입됐으며 설정된 시작 지점부터 컴포넌트 클래스를 scanning하여 빈으로 등록해주는 역할을 한다.
컴포넌트 클래스는 다음 애노테이션이 붙은 클래스를 의미한다.
@Component
@Repository
@Service
@Controller
@Configuration
@ComponentScan의 가장 중요한 두 가지 속성은component를 scan할 시작 지점을 설정하는 속성과scan한 component 중 빈으로 등록하지 않을 클래스를 제외하는 필터 속성이다.
component-scan은 기본적으로 @Component 어노테이션을 빈 등록 대상으로 포함한다. 그렇다면 @Controller 나 @Service는 어떻게 인식하는 걸까? 그 이유는 @Controller나 @Service가 @Component를 포함하고 있기 때문이다.
component-scan 사용방법
component-scan 을 사용하는 방법은 xml 파일에 설정하는 방법, 과자바파일안에서 설정하는 방법이 있다.
위와 같이 설정하면, base pacakage 하위의 @Controller, @Service @Repository, @Component 클래스가 모두 빈으로 등록되므로, 특정한 객체만 빈으로 등록하여 사용하고 싶다면 include-filter나exclude-filter를 통해 설정할 수 있다.
use-default="false"는 기본 어노테이션 @Controller, @Component등을 스캔하지 않는다는 것이다. 기본 어노테이션을 스캔하지 않는다고 설정하고,include-filter를 통해서 위와 같이 특정 어노테이션만 스캔할 수 있다.
2. 자바 파일안에서 설정
@Configuration@ComponentScan(basePackages = "com.rcod.lifelog")
public class ApplicationConfig {
}
@Configuration은 이 클래스가 xml을 대체하는 설정 파일임을 알려준다. 해당 클래스를 설정 파일로 설정하고@ComponentScan을 통하여 basePackages를 설정해준다.
위와 같이component-scan을 사용하는 두 가지 방법이 있다. 만약 component-scan을 사용하지 않으면, 빈으로 설정할 클래스들을 우리가 직접 xml 파일에 일일이 등록해 주어야 한다.
<beanid="mssqlDAO"class="com.test.spr.MssqlDAO"></bean><!-- MemberList 객체에 대한 정보 전달 및 의존성 주입 --><beanid="member"class="com.test.spr.MemberList"><!-- 속성의 이름을 지정하여 주입 --><propertyname="dao"><refbean="mssqlDAO"/></property></bean>
MssqlDAO와MemberList를 빈으로 등록하고, MemberList에 Mssql을 주입한 것이다. 위와 같이 코드가 매우 길어지고, 일일이 추가하기에 복잡해진다.
component-scan 동작 과정
ConfigurationClassParser 가 Configuration 클래스를 파싱한다. @Configuration 어노테이션 클래스를 파싱하는 것이다. ⬇ ComponentScan 설정을 파싱한다. base-package 에 설정한 패키지를 기준으로 ComponentScanAnnotationParser가 스캔하기 위한 설정을 파싱한다. ⬇ base-package 설정을 바탕으로 모든 클래스를 로딩한다. ⬇ ClassLoader가 로딩한 클래스들을 BeanDefinition으로 정의한다. 생성할 빈의 대한 정의를 하는 것이다. ⬇ 생성할 빈에 대한 정의를 토대로 빈을 생성한다.
Spring boot에서의 @ConponentScan
이전 Xml Config 방식에서 ComponentScan을 사용하는 방법은 다음과 같았다.
applicationContext를 구성할때 이렇게 명시적으로 내가 읽어들여야하는 component들이 있는 package를 넣어줬다.
하지만 Springboot에서는 Xml Config보다는 Java Config를 사용하고 @기반의 설정을 많이 한다. 아니 이 Component Scan을 하지도 않는데 알아서 잘 된다. 어떻게 된 일일까? 바로 Springboot의 핵심! @SpringBootApplication 에 답이 있다. Springboot Main Class에 있는 @SpringBootApplication를 ctrl을 누르고 눌러서 들어가보자.
들어가보면 이런식으로 구성이 되어있다. 복잡해 보이지만 쉽게 설명을 하자면 내가 아무런 ComponentScan 관련 설정을 하지 않았다면 바로 이@SpringBootApplication 가 정의된 곳이 base package가 되는 것이다. 그래서 처음 프로젝트 구조를 만들때 이 Springboot Main Class의 package가 매우 중요하다.
그리고 아래에 나와있는 @AliasFor 부분에 나온basePackages와 basePackagesClasses도 중요하다.Springboot Main Class의 위치에 구애받지 않고 내가마음대로 ComponentScan을 할 곳을 정의할때 사용된다.
스프링 배치의 모든 잡은 실패하거나 중지될 때 다시 실행할 수 있었다. 스프링 배치는 기본적으로 이렇게 동작하므로 우리는 다시 실행하면 안되는 잡이 있을시 재시작을 방지해야한다.
preventRestart()
preventRestart() 메서드를 호출하여 잡이 실패하거나 어떤 이유로 중지된 경우에도 다시 실행할 수 없다.
/**
* 잡 실행
* @return
*/@Bean
public Job transactionJob() {
return this.jobBuilderFactory.get("transactionJob")
.preventRestart() /* 잡은 기본적으로 재시작이 가능하도록 구성되어있다. 잡의 재시작 방지 */.start(...)
.next(...)
.build();
}
잡의 재시작 횟수 제한
startLimit(n) : 재시작 횟수를 n번으로 제한한다.
@Bean
public Step importTransactionFileStep() {
return this.stepBuilderFactory.get("importTransactionFileStep")
.startLimit(2) /* 잡의 재시작 횟수 제한 */
.<Transaction, Transaction>chunk(100)
.reader(...)
.writer(...)
.listener(...) /* 스텝 빌드하기 전 실행할 리스너 등록 */.build();
}
완료된 스텝 재실행하기
allowStartIfComplete(true)
스텝이 잘 완료됐더라도, 다시 실행할 수 있어야 할때 사용한다.주의할 점은, 잡의 ExitStatus 가 COMPLETE 라면 모든 스텝에allowStartIfComplete(true) 를 적용하더라도 이와 관계없이 잡 인스턴스는 다시 실행할 수 없다.
잡이 재실행될때 무조건 실행되어야할 스텝이 존재할 경우 설정한다.
@Bean
public Step importTransactionFileStep() {
return this.stepBuilderFactory.get("importTransactionFileStep")
.<Transaction, Transaction>chunk(100)
.reader(...)
.writer(...)
.allowStartIfComplete(true) /* 잡이 재시작될시, 스텝이 다시 실행될 수 있도록 재시작 허용 */.listener(...) /* 스텝 빌드하기 전 실행할 리스너 등록 */.build();
}
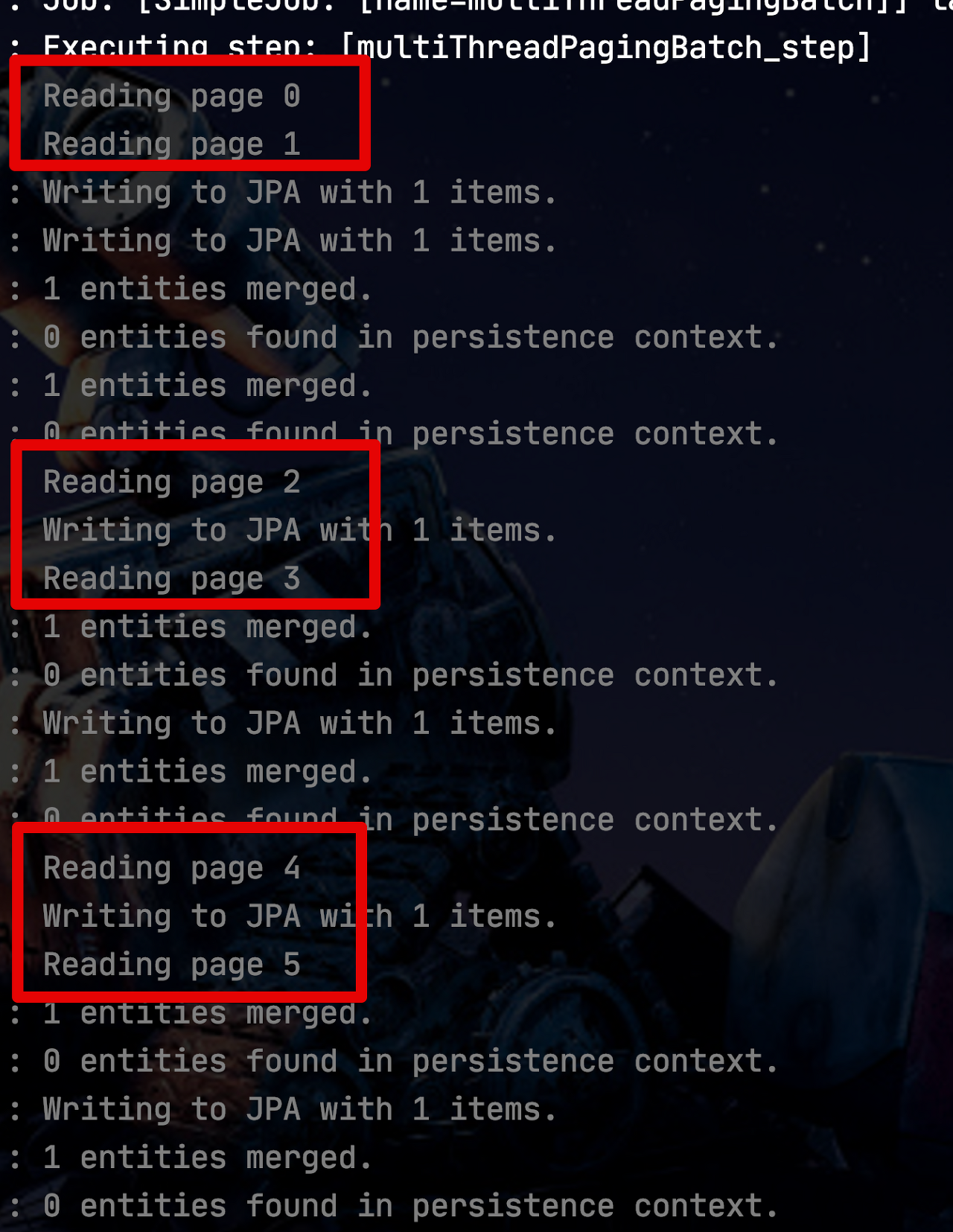
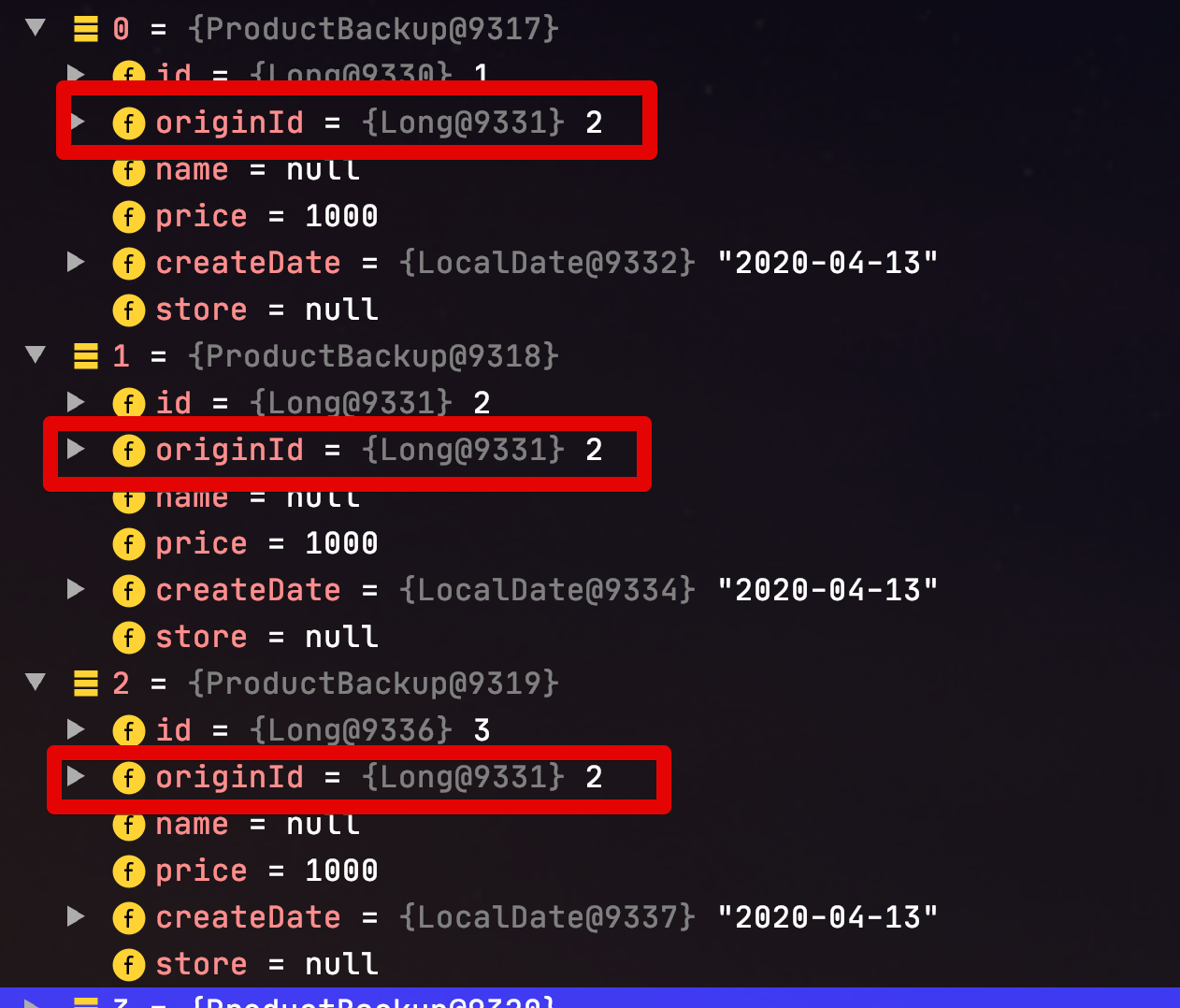
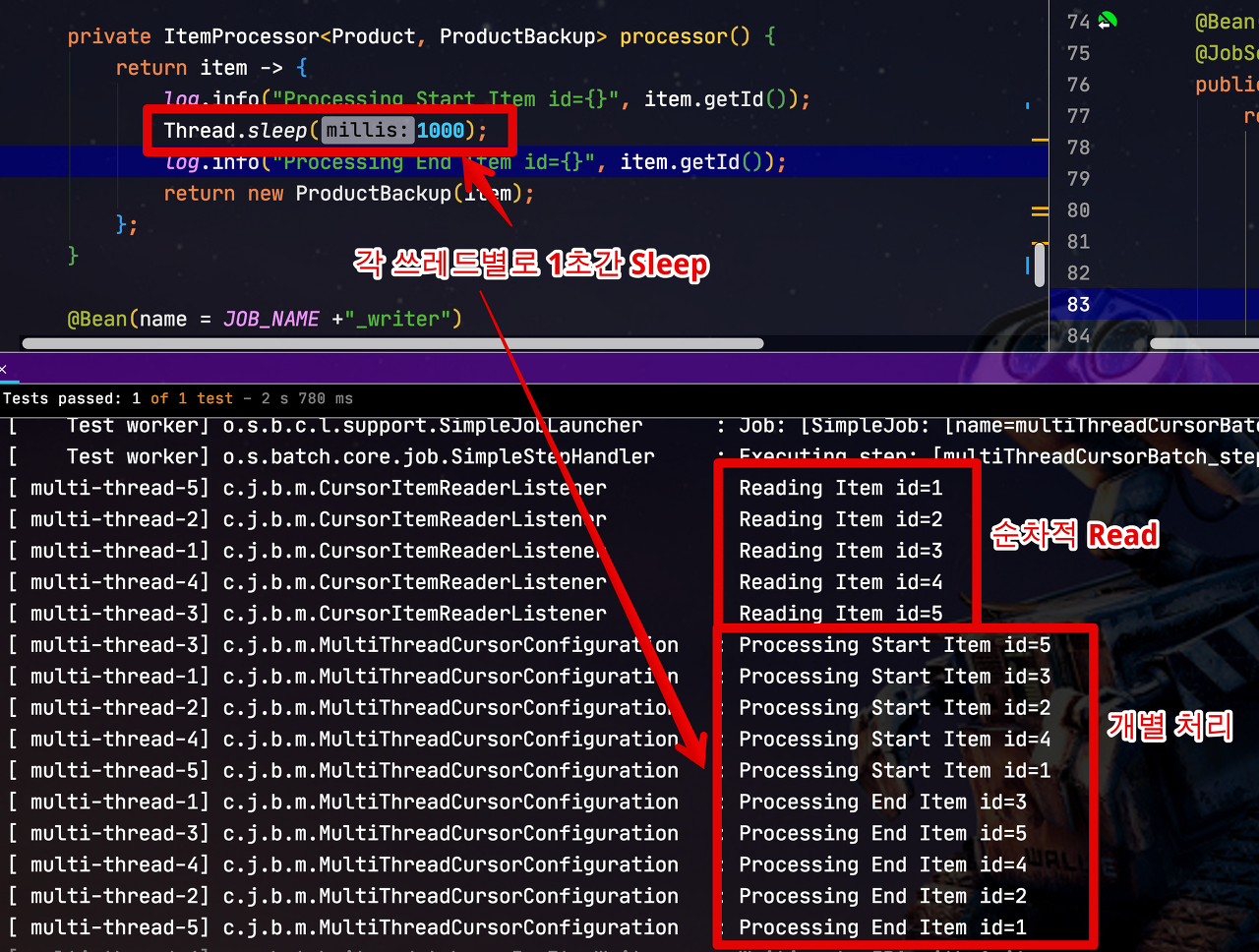
일반적으로 Spring Batch는 단일 쓰레드에서 실행됩니다. 즉, 모든 것이 순차적으로 실행되는 것을 의미하는데요. Spring Batch에서는 이를 병렬로 실행할 수 있는 방법을 여러가지 지원합니다. 이번 시간에는 그 중 하나인 멀티스레드로 Step을 실행하는 방법에 대해서 알아보겠습니다.
Spring Batch의 멀티쓰레드 Step은 Spring의TaskExecutor를 이용하여각 쓰레드가 Chunk 단위로 실행되게하는 방식입니다.
여기서 어떤TaskExecutor를 선택하냐에 따라 모든 Chunk 단위별로 쓰레드가 계속 새로 생성될 수도 있으며 (SimpleAsyncTaskExecutor) 혹은 쓰레드풀 내에서 지정된 갯수의 쓰레드만을 재사용하면서 실행 될 수도 있습니다. (ThreadPoolTaskExecutor)
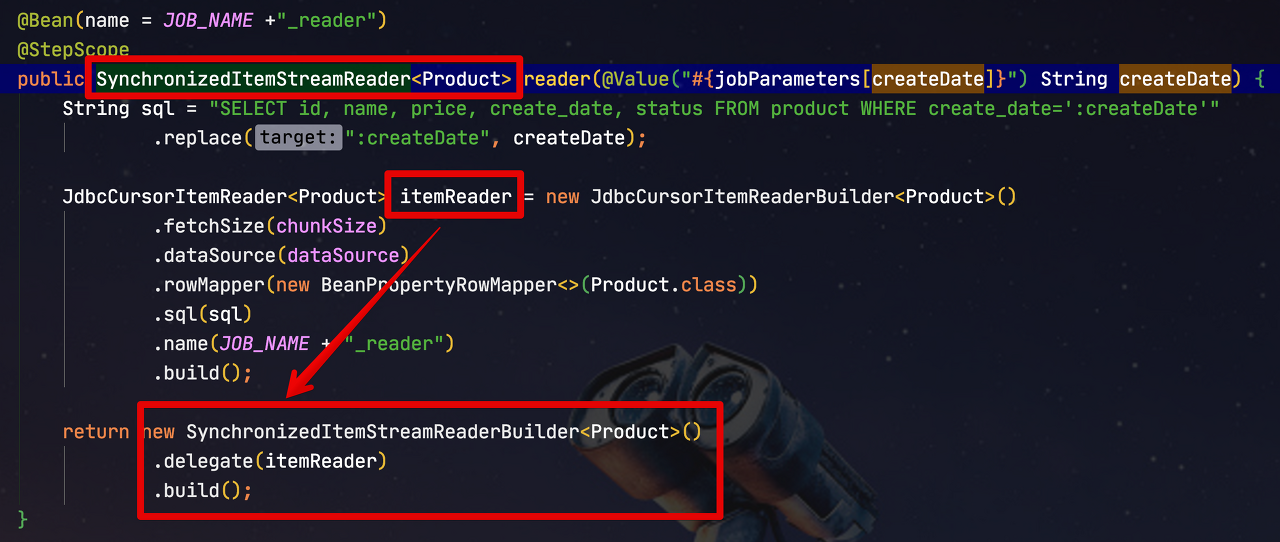
Spring Batch에서 멀티쓰레드 환경을 구성하기 위해서 가장 먼저 해야할 일은 사용하고자 하는Reader와 Writer가 멀티쓰레드를 지원하는지확인하는 것 입니다.
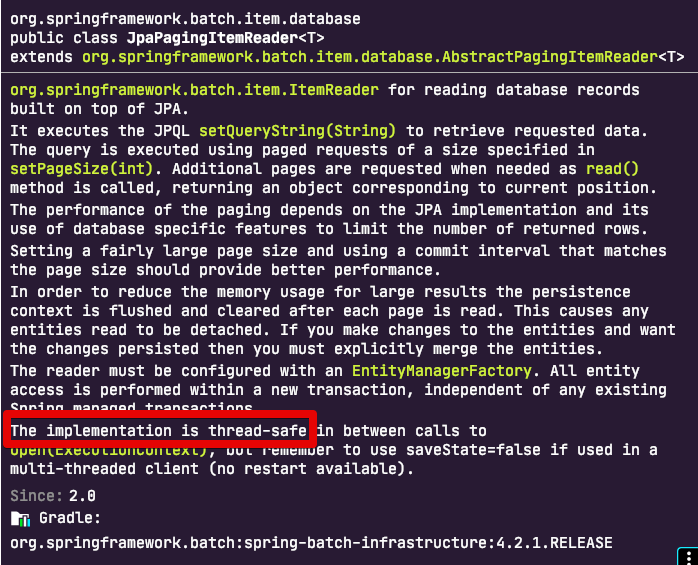
JpaPagingItemReader의 Javadoc
각 Reader와 Writer의 Javadoc에 항상 저thread-safe문구가 있는지 확인해보셔야 합니다. 만약 없는 경우엔 thread-safe가 지원되는 Reader 와 Writer를 선택해주셔야하며, 꼭 그 Reader를 써야한다면SynchronizedItemStreamReader등을 이용해thread-safe로 변환해서 사용해볼 수 있습니다.
그리고 또 하나 주의할 것은 멀티 쓰레드로 각 Chunk들이 개별로 진행되다보니 Spring Batch의 큰 장점중 하나인 실패 지점에서 재시작하는 것은 불가능 합니다. 이유는 간단합니다. 단일 쓰레드로 순차적으로 실행할때는 10번째 Chunk가 실패한다면 9번째까지의 Chunk가 성공했음이 보장되지만, 멀티쓰레드의 경우 1~10개의 Chunk가 동시에 실행되다보니 10번째 Chunk가 실패했다고 해서 1~9개까지의 Chunk가 다 성공된 상태임이 보장되지 않습니다.
그래서 일반적으로는 ItemReader의 saveState 옵션을 false 로 설정하고 사용합니다.
이건 예제 코드에서 설정을 보여드리겠습니다.
자 그럼 실제로 하나씩 코드를 작성하면서 실습해보겠습니다.
2. PagingItemReader 예제
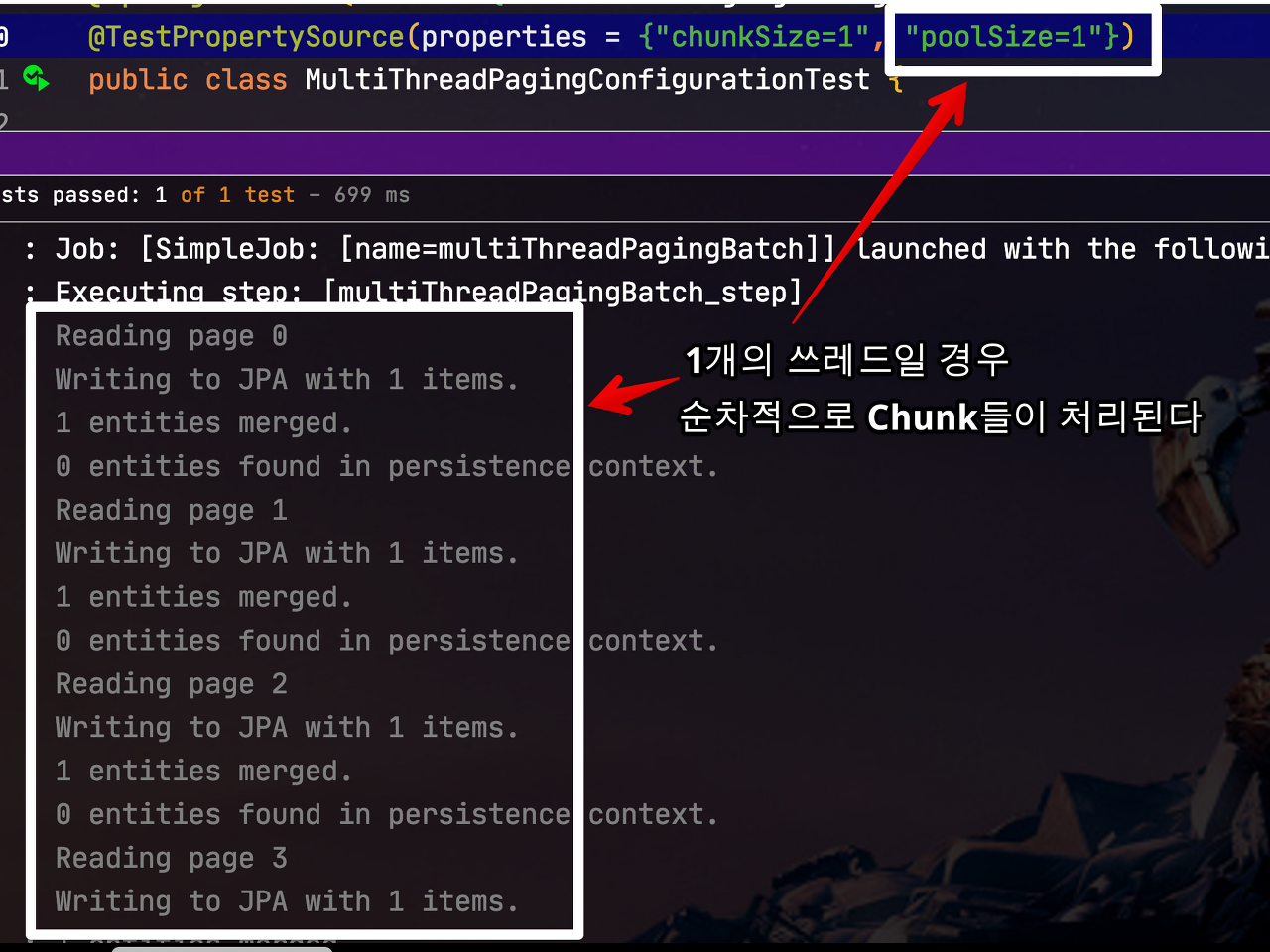
가장 먼저 알아볼 것은 PagingItemReader를 사용할때 입니다. 이때는 걱정할 게 없습니다. PagingItemReader는Thread Safe하기 때문입니다.
멀티 쓰레드로 실행할 배치가 필요하시다면 웬만하면 PagingItemReader로 사용하길 추천드립니다.
1) 부모 Entity를 insert 하고 생성된 Id 반환 2) 자식 Entity에선 1) 에서 생성된 부모 Id를 FK 값으로 채워서 insert
위 과정를 진행하는 쿼리를 모아서 실행하는게 Hibernate의 방식인데, 이때 Batch Insert과 같은 대량 등록의 경우엔 이 방식을 사용할 수가 없습니다. (부모 Entity를 한번에 대량 등록하게 되면, 어느 자식 Entity가 어느 부모 Entity에 매핑되어야하는지 알 수 없겠죠?)
그럼 ID 생성 전략을 Auto Increment가 아닌 Table (Sequence)를 선택하면 되지 않을까 생각하게 되는데요. 아래 글에서 자세하게 설명하고 있지만,성능상 이슈와Dead Lock에 대한 이슈로 Auto Increment를 강력하게 추천합니다.
@Testpublicvoidnon_auto_increment_test_jdbc()throws Exception {
//given
JdbcBatchItemWriter<Person2> writer = new JdbcBatchItemWriterBuilder<Person2>()
.dataSource(dataSource)
.sql("insert into person(id, name) values (:id, :name)")
.beanMapped()
.build();
writer.afterPropertiesSet();
List<Person2> items = new ArrayList<>();
for (long i = 0; i < TEST_COUNT; i++) {
items.add(new Person2(i, "foo" + i));
}
// when
writer.write(items);
}
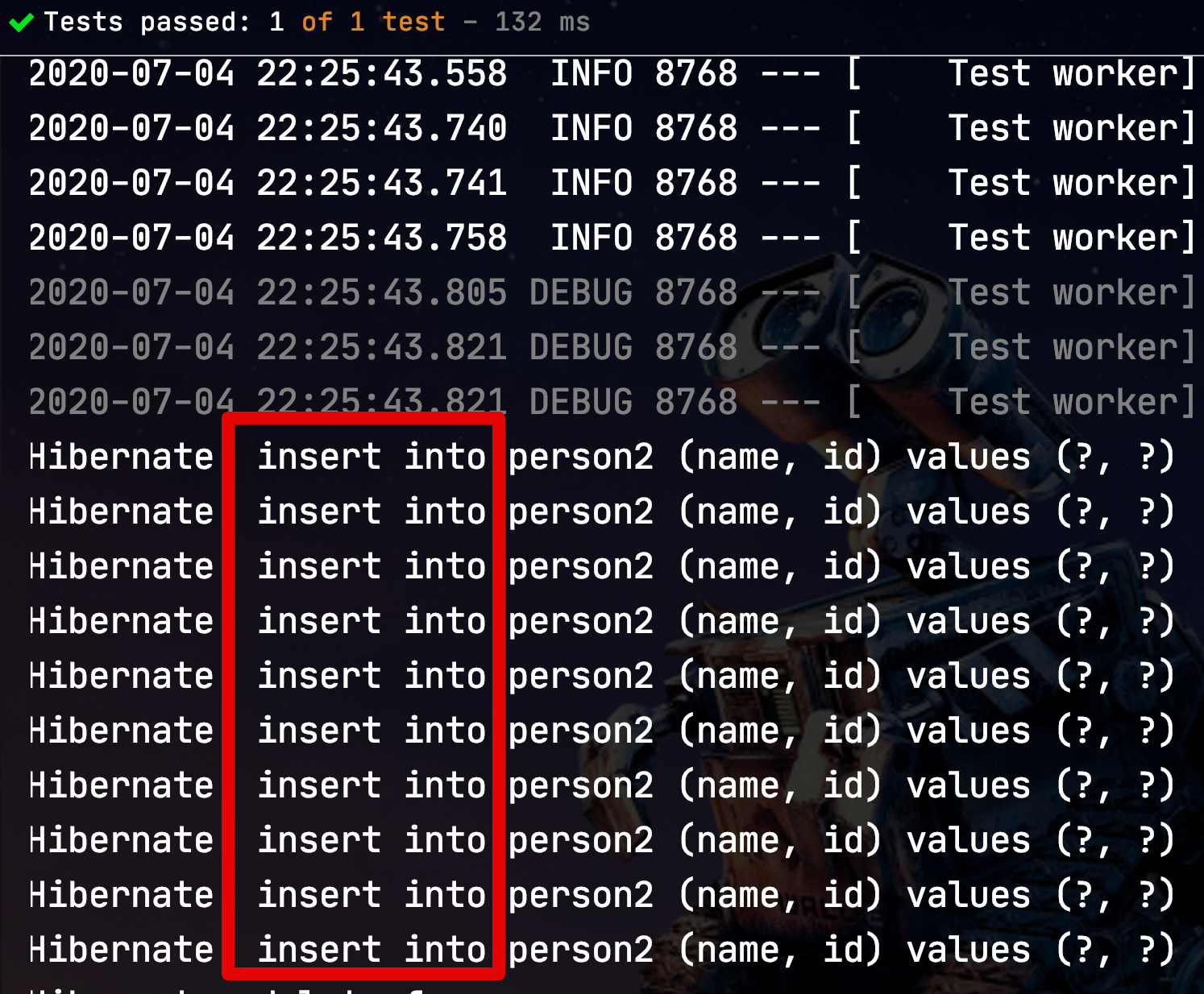
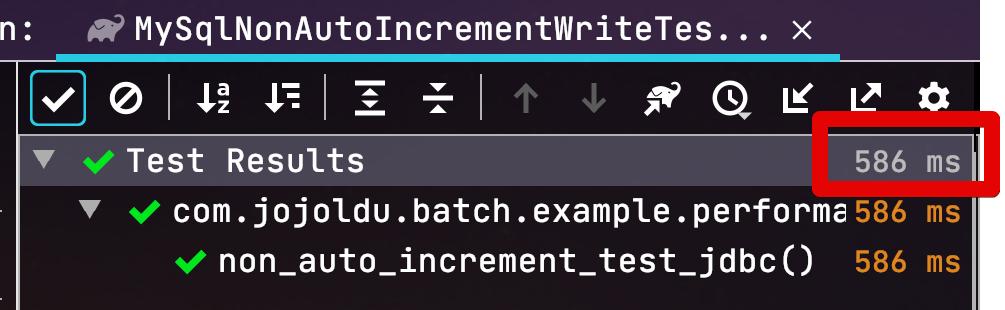
1만건을 요청하는 위 코드를 직접 MySQL에 요청을 해보면?
0.586초라는 JpaItemWriter에 비해 압도적인 성능을 보여줍니다.
3-2. Auto Increment 성능
그럼 Auto Increment일 경우엔 어떻게 될까요?
@Testpublicvoidauto_increment_test_jdbc()throws Exception {
//given
JdbcBatchItemWriter<Person> writer = new JdbcBatchItemWriterBuilder<Person>()
.dataSource(dataSource)
.sql("insert into person(name) values (:name)")
.beanMapped()
.build();
writer.afterPropertiesSet();
List<Person> items = new ArrayList<>();
for (long i = 0; i < TEST_COUNT; i++) {
items.add(new Person( "foo" + i));
}
// when
writer.write(items);
}
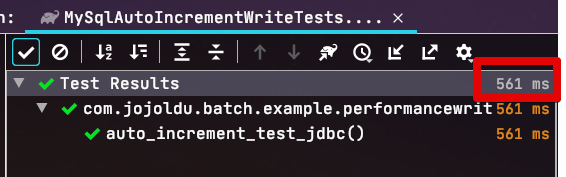
동일하게 1만건을 요청할 경우에도 마찬가지로0.561초라는 결과를 보여줍니다.
순수하게 단일 테이블의 등록면에 있어서는 Jdbc Batch Insert의 성능이 비교가 안될 정도로 좋다는 것을 알 수 있습니다.
다만 무조건 많은 양의 row를 한번에 요청하는게 빠른 방법은 아닙니다. 한번에 몇개의 insert value를 만들지 MySQL의max_allowed_packet,Buffer Size,bulk_insert_buffer_size등 여러 옵션들에 따라 상이하니 적절한 성능 테스트를 통해 값을 찾아야 합니다.
3. 최종 비교
최종적으로 Spring Batch ItemWriter들의 성능을 비교하면 다음과 같습니다.
ItemWriter ModeNon Auto Increment (10,000 row)Auto Increment (10,000 row)
ItemWriter Mode
Non Auto Increment
Auto Increament
Jpa.Merge
2m 16s
1m 1s
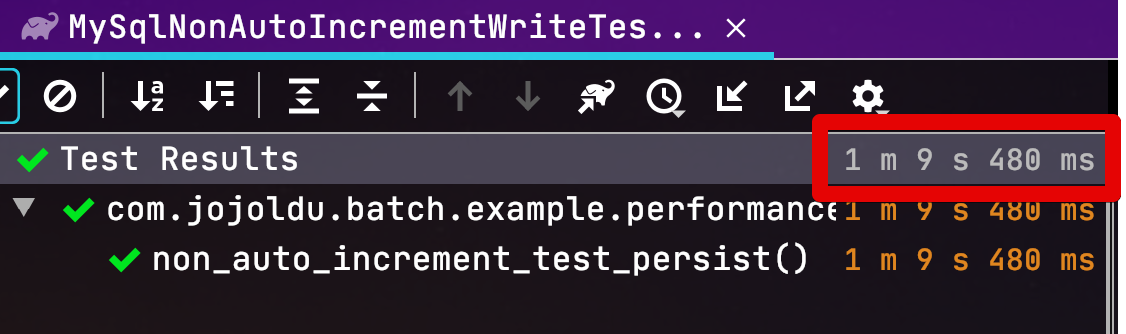
Jpa.Persist
1m 9s
1m 2s
Jdbc Batch Insert
0.586s
0.586s
순수하게단일 테이블에 대량으로 등록할 경우 Jdbc의 Batch Insert 방식이 압도적인 성능을 보여줍니다. 다만, 무조건 Jdbc Batch Insert 방식을 사용하기엔 아래와 같은 단점들이 있습니다.
OneToMany, ManyToMany와 같이 복잡한 Entity 관계가 insert가 필요할 경우 직접 구현해야할 부분이 너무나 많이 존재
컴파일체크, 타입힌트, 자동완성등 유지보수가 어려운 개발 환경
그래서 다음과 같이혼합 방식을 선택하기도 합니다.
이를 테면 OneToMany의 관계가 등록이 필요할 경우
부모 Entity는 JpaItemWriter를 이용하여 ChunkSize별로 저장하여 PK값과 Entity를 확보
PK가 확보된 부모 Entity를 통해 자식 Entity들을 생성 (부모 ID값을 갖고 생성)
성능 향상을 위해서 Batch Insert를 도입하는 과정 중 JPA, Mysql 환경에서의 Batch Insert에 대한 방법과 제약사항들에 대해서 정리했습니다. 결과적으로는 다른 프레임워크를 도입해서 해결했으며 본 포스팅은 JPA Batch Insert의 정리와, 왜 다른 프레임워크를 도입을 했는지에 대해한 내용입니다.
insert rows 여러 개 연결해서 한 번에 입력하는 것을 Batch Insert라고 말합니다. 당연한 이야기이지만 Batch Insert는 하나의 트랜잭션으로 묶이게 됩니다.
Batch Insert With JPA
위 Batch Insert SQL이 간단해 보이지만 실제 로직으로 작성하려면 코드가 복잡해지고 실수하기 좋은 포인트들이 있어 유지 보수하기 어려운 코드가 되기 쉽습니다. 해당 포인트들은 아래 주석으로 작성했습니다.JPA를 사용하면 이러한 문제들을 정말 쉽게 해결이 가능합니다.
// 문자열로 기반으로 SQL을 관리하기 때문에 변경 및 유지 보수에 좋지 않음val sql = "insert into payment_back (id, amount, order_id) values (?, ?, ?)"val statement = connection.prepareStatement(sql)!!
funaddBatch(payment: Payment) = statement.apply {
// code 바인딩 순서에 따라 오동작 가능성이 높음// 매번 자료형을 지정해서 값을 입력해야 함this.setLong(1, payment.id!!)
this.setBigDecimal(2, payment.amount)
this.setLong(3, payment.orderId)
this.addBatch()
}
// connection & statement 객체를 직접 close 진행, 하지 않을 경우 문제 발생 가능성이 있음funclose() {
if (statement.isClosed.not())
statement.close()
}
쓰기 지연 SQL 지원 이란 ?
EntityMaanger em = emf.createEnttiyManager();
ENtityTranscation transaction = em.getTransaction();
// 엔티티 매니저는 데이터 변경 시 트랜잭션을 시작해야 한다.
transaction.begin();
em.persist(memberA);
em.persist(memberB);
// 여기까지 InsertSQL을 데이터베이스에 보내지 않는다.
//Commit을 하는 순간 데이터베이스에 InsertSQL을 보낸다
transaction.commit();
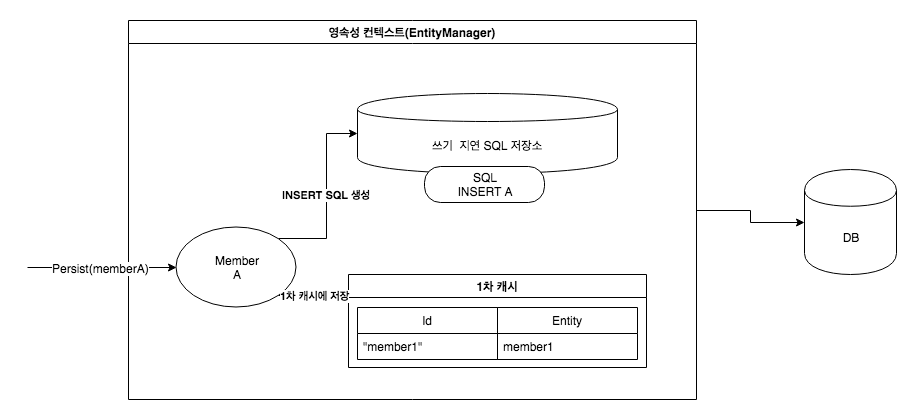
엔티티 매니저는 트랜잭션을 커밋 하기 직전까지 데이터베이스에 엔티티를 저장하지 않고 내부 쿼리 저장소에 INSERT SQL을 모아둔다. 그리고 트랜잭션을 커밋 할 때 모아둔 쿼리를 데이터베이스에 보내는데 이것을 트랜잭션을 지원하는 쓰기 지연이라 한다.
회원 A를 영속화했다. 영속성 컨텍스트는 1차 캐시에 회원 엔티티를 저장하면서 동시에 회원 엔티티 정보로 등록 쿼리를 만든다. 그리고 만들어진 등록 쿼리를 쓰기 지연 SQL 저장소에 보관한다.
다음으로 회원 B를 영속화했다. 마찬가지로 회원 엔티티 정보로 등록 쿼리를 생성해서 쓰지 지연 SQL 저장소에 보관한다. 현재 쓰기 지연 SQL 저장소에는 등록 쿼리가 2건이 저장되어 있다.
마지막으로 트랜잭션을 커밋 했다. 트랜잭션을 커밋 하면 엔티티 매니저는 우선 영속성 컨텍스트를 플러시 한다. 플러시는 영속성 컨텍스트의 변경 내용을 데이터베이스에 동기화하는 작업인데 이때 등록, 수정, 삭제한 엔티티를 데이터베이스에 반영한다.이러한 부분은 JPA 내부적으로 이루어지기 때문에 사용하는 코드에서는 코드의 변경 없이 이러한 작업들이 가능하다.
addBatch 구분을 사용하기 위해서는rewriteBatchedStatements=true속성을 지정해야 합니다. 기본 설정은false이며, 해당 설정이 없으면 Batch Insert는 동작하지 않습니다. 정확한 내용은 공식 문서를 참고해 주세요.
MySQL Connector/J 8.0 Developer Guide : 6.3.13 Performance Extensions Stops checking if every INSERT statement contains the “ON DUPLICATE KEY UPDATE” clause. As a side effect, obtaining the statement’s generated keys information will return a list where normally it wouldn’t. Also be aware that, in this case, the list of generated keys returned may not be accurate. The effect of this property is canceled if set simultaneously with ‘rewriteBatchedStatements=true’.
hibernate.jdbc.batch_size: 50Batch Insert의 size를 지정합니다. 해당 크기에 따라서 한 번에 insert 되는 rows가 결정됩니다. 자세한 내용은 아래에서 설명드리겠습니다.
@Entity@Table(name = "payment_back")
class PaymentBackJpa(
@Column(name = "amount", nullable = false)
var amount: BigDecimal,
@Column(name = "order_id", nullable = false, updatable = false)
val orderId: Long
){
@Id@Column(name = "id", updatable = false) // @GeneratedValue를 지정하지 않았음
var id: Long? = null
}
interface PaymentBackJpaRepository: JpaRepository<PaymentBackJpa, Long>
엔티티 클래스는 간단합니다. 중요한 부분은@GeneratedValue을 지정하지 않은 부분입니다.
paymentBackJpaRepository.saveAll()를 이용해서 batch inset를 진행합니다. JPA 기반으로 Batch Insert를 진행할 때 별다른 코드가 필요 없습니다. 컬렉션 객체를saveAll()으로 저장하는 것이 전부입니다.hibernate.show_sql: true으로 로킹 결고를 확인해보겠습니다.
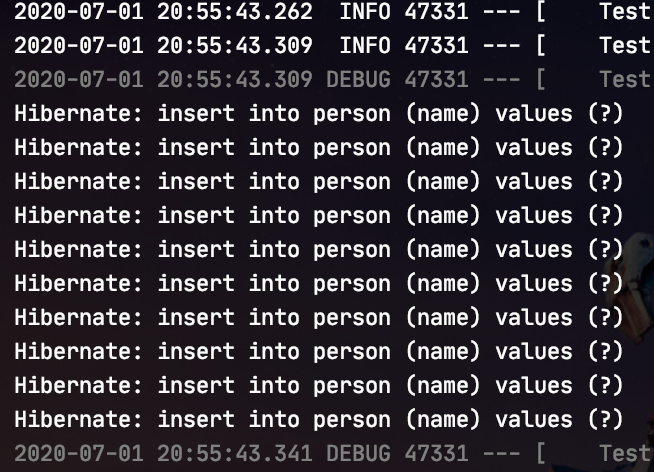
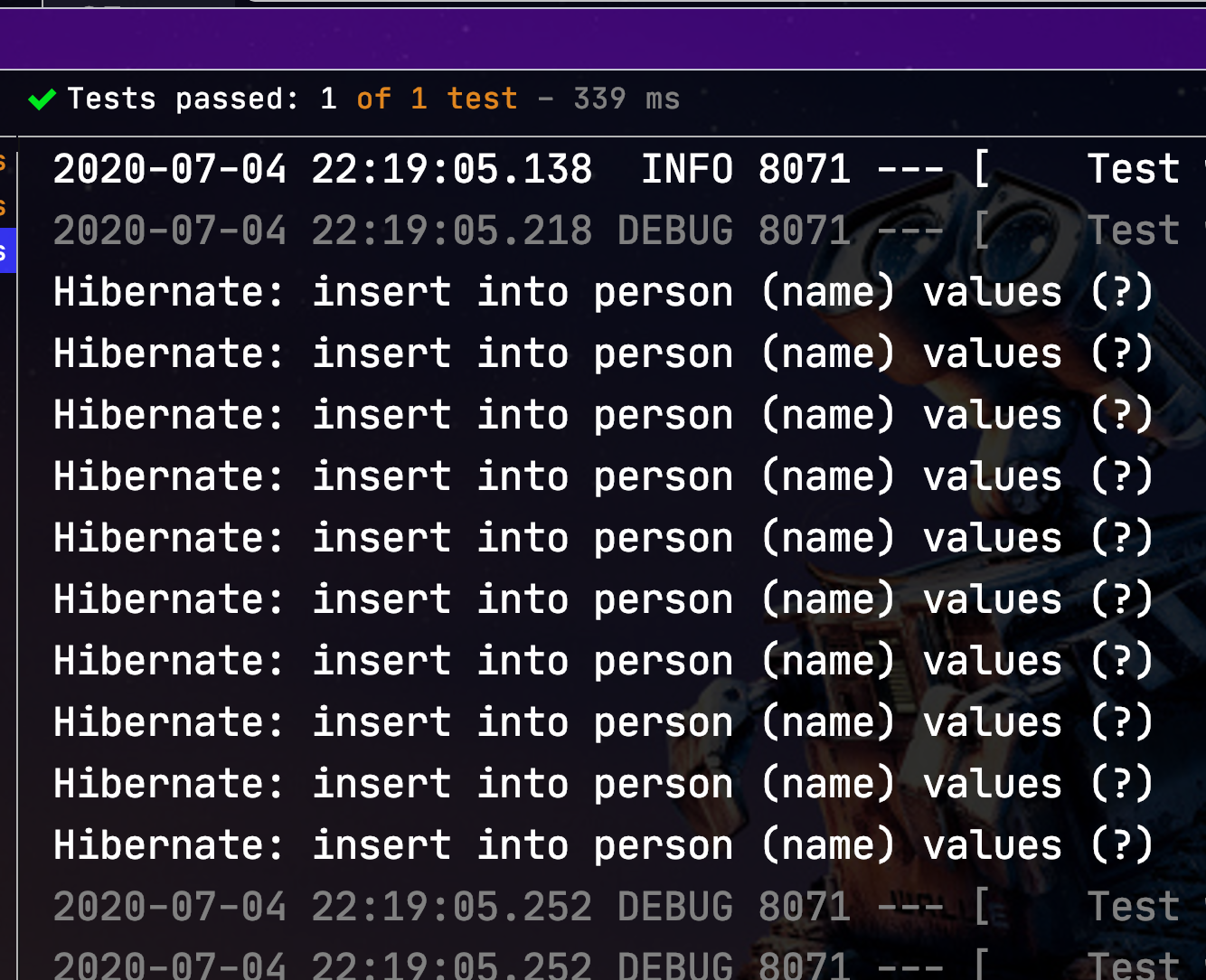
로그상으로는 Batch Insert가 진행되지 않은 것처럼 보입니다. 결론부터 말씀드리면 실제로는 Batch Insert가 진행됐지만hibernate.show_sql: true기반 로그에는 제대로 표시가 되지 않습니다. Mysql의 실제 로그로 확인해보겠습니다.
show variables like'general_log%'; # general_log 획인
setglobal general_log ='ON'; # `OFF` 경우 `ON` 으로 변경
해당 로그 설정은 성능에 지장을 줄 수 있기 때문에 테스트, 개발 환경에서만 지정하는 것을 권장합니다.해당 기능은 실시간으로 변경 가능하기 때문에 설정 완료 이후/var/lib/mysql/0a651fe44d20.log파일에 로그를 확인할 수 있습니다.
실제 mysql 로그에서는 Batch Insert를 확인할 수 있습니다. 그런데 왜 2번에 걸쳐서 Batch Insert가 진행되었을까요?hibernate.jdbc.batch_size: 50설정으로 Batch Insert에 대한 size를 50으로 지정했기 때문에 rows 100를 저장할 때 2번에 걸쳐 insert를 진행하는 것입니다.만약hibernate.jdbc.batch_size: 100이라면 1번의 insert로 저장됩니다.
위 쿼리는hibernate.jdbc.batch_size: 100으로 지정한 결과입니다. 그렇다면 왜batch_size옵션을 주어서 한 번에 insert 할 수 있는 데이터의 크기를 제한하는 것일까요? 아래 코드에서 해답을 찾을 수 있습니다.
When you make new objects persistent, employ methods flush() and clear() to the session regularly, to control the size of the first-level cache.
하이버네이트 공식 가이드의 내용입니다.batchSize값을 기준으로flush();,clear();를 이용해서 영속성 컨텍스트를 초기화 작업을 진행하고 있습니다.batchSize에 대한 제한이 없으면 영속성 컨텍스트에 모든 엔티티가 올라가기 때문에OutOfMemoryException발생할 수 있고, 메모리 관리 측면에서도 효율적이지 않기 때문입니다. 하이버네이트의 공식 가이드에서도 해당 부분의 언급이 있습니다.
Hibernate caches all the newly inserted Customer instances in the session-level cache, so, when the transaction ends, 100 000 entities are managed by the persistence context. If the maximum memory allocated to the JVM is rather low, this example could fail with an OutOfMemoryException. The Java 1.8 JVM allocated either 1/4 of available RAM or 1Gb, which can easily accommodate 100 000 objects on the heap.
long-running transactions can deplete a connection pool so other transactions don’t get a chance to proceed
JDBC batching is not enabled by default, so every insert statement requires a database roundtrip. To enable JDBC batching, set the hibernate.jdbc.batch_size property to an integer between 10 and 50.
쓰기 지연 SQL 제약 사항
batchSize: 50경우PaymentBackJpa객체를 50 단위로 Batch Insert 쿼리가 실행되지만, 중간에 다른 엔티티를 저장하는 경우 아래처럼 지금까지의PaymentBackJpa에 대한 지정하기 때문에 최종적으로batchSize: 50단위로 저장되지 않습니다.
em.persist(new PaymentBackJpa()); // 1em.persist(new PaymentBackJpa()); // 2em.persist(new PaymentBackJpa()); // 3em.persist(new PaymentBackJpa()); // 4em.persist(new Orders()); // 1-1, 다른 SQL이 추가 되었기 때문에 SQL 배치를 다시 시작 해야 한다.em.persist(new PaymentBackJpa()); // 1em.persist(new PaymentBackJpa()); // 2
이러한 문제는hibernate.order_updates: true,hibernate.order_inserts: true값으로 해결 할 수 있습니다.
JPA Batch Insert의 가장 큰 문제…
위에서 설명했던 부분들은 Batch Insert에 필요한 properties 설정, 그리고 내부적으로 JPA에서 Batch Insert에 대한 동작 방식을 설명한 것입니다.실제 Batch Insert를 진행하는 코드는 별다른 부분이 없고 컬렉션 객체를saveAll()메서드로 호출하는 것이 전부입니다.이로써 JPA는 Batch Insert를 강력하게 지원해 주고 있습니다.하지만 가장 큰 문제가 있습니다.@GeneratedValue(strategy = GenerationType.IDENTITY)방식의 경우 Batch Insert를 지원하지 않습니다.
Hibernate disables insert batching at the JDBC level transparently if you use an identity identifier generator.
공식 문서에도 언급이 있듯이@GeneratedValue(strategy = GenerationType.IDENTITY)경우 Batch Insert를 지원하지 않습니다. 정확히 어떤 이유 때문인지에 대해서는 언급이 없고, 관련 내용을 잘 설명한StackOverflow를 첨부합니다.
제가 이해한 바로는 하이버네이트는Transactional Write Behind방식(마지막까지 영속성 컨텍스트에서 데이터를 가지고 있어 플러시를 연기하는 방식)을 사용하기 때문에GenerationType.IDENTITY방식의 경우 JDBC Batch Insert를 비활성화함.GenerationType.IDENTITY방식이란auto_increment으로 PK 값을 자동으로 증분 해서 생성하는 것으로 매우 효율적으로 관리할 수 있다.(heavyweight transactional course-grain locks 보다 효율적). 하지만 Insert를 실행하기 전까지는 ID에 할당된 값을 알 수 없기 때문에Transactional Write Behind을 할 수 없고 결과적으로 Batch Insert를 진행할 수 없다.
Mysql에서는 대부분GenerationType.IDENTITY으로 사용하기 때문에 해당 문제는 치명적입니다. 우선GenerationType.IDENTITY으로 지정하고 다시 테스트 코드를 돌려 보겠습니다.
@Entity@Table(name = "payment_back")
class PaymentBackJpa(
@Column(name = "amount", nullable = false)
var amount: BigDecimal,
@Column(name = "order_id", nullable = false, updatable = false)
val orderId: Long
){
@Id@GeneratedValue(strategy = GenerationType.IDENTITY) // GenerationType.IDENTITY 지정
var id: Long? = null
}
internal class BulkInsertJobConfigurationTest(
private val paymentBackJpaRepository: PaymentBackJpaRepository
) {
@Test
internal fun `jpa 기반 bulk insert`() {
(1..100).map {
PaymentBackJpa(
amount = it.toBigDecimal(),
orderId = it.toLong()
)
.apply {
// this.id = it.toLong() // ID를 자동 증가로 변경 했기 때문에 코드 주석
}
}.also {
paymentBackJpaRepository.saveAll(it)
}
}
}
나는 주로 그 동안 자바를 메인으로 사용하기 때문에 자바랑 비교 해 보자면 무지 간단하다. java는 설정이 꽤나 복잡하다. JDK, 메이븐, 스프링 설정, web.xml 등 DB 설정등 무지 많다. 근데 php 는 xampp 하나만 깔면 새로 프로그램을 깔거나 할 것이 없다. editor 정도만 깔아 주면 된다.
괜찮은 MVC 프레임웍이 있다.
사실 설정이 간단한 건 ASP도 간단하다. 하지만 old asp는 만들거나 기존 소스가 없으면 db connection 부터 화면단까지 모두 개발자의 몫이다. 프레임웍이 없다는 건 생산성에도 문제가 있지만 프레임웍 없이 만든 코드는 가독성역시 떨어지고 유지보수도 어렵다. php에는 CI(code igniter)라고 하는 괜찮은 MVC 프레임웍이 있다. Java 의 스프링 만큼 좋은 것은 아니겠지만 web 개발하는데는 충분하다. MVC라는 구조를 아는 사람이라면 쉽게 접근할 수 있다. 이 건 동일한 스크립트 언어인 ASP와 비교해볼 때 우위를 가지는 장점이다.
스크립트 언어다.
스크립트 언어라는 것의 의미는 변경사항이 생겼을 때 서버 재시작이 필요 없는 것을 의미 한다. java 의 경우에는 query 등 java 파일을 변경하는 경우에는 기본적으로 서버를 리스타트가 필요하다. 실제 개발할 때 수정 내용을 바로 반영해서 화면을 보는 것과 서버를 다시 리스타트해서 보는 것 사이에는 작게는 몇배에서 크게는 몇 십배 아니 몇 백배의 시간 차이가 난다. 하지만 스크립트 언어라 가지는 단점도 존재한다. 간단하게는 에러가 나봐야 안다. 하지만 그만큼의 생산성이 단점을 커버할만하다고 생각한다.
멀티라인 문자열 변수를 사용할 수 있다.(?)
이건 Java 대비 가지는 장점인데 java는 멀티라인 스트링 변수를 사용할 수 없다. 때문에 복잡한 query나 설정은 xml 에 저장해야 한다. 이거 무지 번거롭다. 파일 위치를 정해야 하고 web 이라는 특성상 절대경로를 사용하기에는 부담스럽다. xml을 읽어서 parsing 해야 한다. 아님 mybatis 등 프레임웍을 설정해야 한다. 또 java 개발의 경우에는 java 파일 외에 properties 나 xml 파일을 다룰 줄 알아야 한다. 이렇게 하던 저렇게 하던 비용(시간)이 든다. php는 단순히 변수에 저장하면 되므로 간단하다. 또 문자열 연결도 무지 간단하다.
PHP 라는 Web 개발언어는 호불호가 많이 갈리는 언어이다. 그 나름의 주장이 의미가 있다.내가 장점으로 보는 것은 생산성 측면에서 좋다는 것이다. 그리고 스크립트 언어라는 단점 때문에 대용량이나 안정성이 중요하게 요구 되는 시스템에서는 적절하지 않을 수 있다. 다만 간단한 게시판 성의 내용이고 UI가 중요하다면 서버는 최대한 간단하게 php로 구축하고 UI를 유행하는 javascript 프레임웍(jquery, angular.js, react)으로 꾸며서 작업할 것이다. 또 내 경험으로 예전에 java 로 서버를 개발하고 html 에서 ajax를 만들어 보기가 쉽지 않았다. 지금은 RestController 등이 있어서 쉽게 json 형태로 변환이 되지만 얼마전까지는 쉽지 않았던 기억이 난다. 결론은 내가 100 이내의 사용자가 사용하는 내부 시스템을 만들어야 하는 상황이라면 PHP를 최우선으로 고려해 볼 듯 하다.
PHP(Hypertext Preprocessor)는 C언어와 유사한 문법으로 비교적 쉽게 배울 수 있어 진입장벽이 낮은 서버 사이드 언어에 속합니다. 상대적으로 높은 점유율과 풍부한 레퍼런스들로 인해 웹 개발을 처음 시작하는 초보 개발자들에게 적극적으로 채택되어왔습니다.Node.js가 등장하기 전 PHP는 JavaScript와 떼려야 뗄 수 없는 단짝이었습니다. 클라이언트 사이드 언어인 JavaScript는 브라우저의 디테일을, 서버사이드 언어인 PHP는 서버 수준의 동적인 작업 전반을 담당하고 있었기 때문입니다. 하지만 2009년 Ryan Dahl이 JavaScript를 활용해 서버 스택을 구축할 수 있는 Node.js를 고안한 이후 JavaScript와 PHP의 긴 협력의 역사가 마감됩니다.Node.js는 클라이언트 개발에만 국한해 활용되던 JavaScript로 서버 사이드 개발을 가능케 하는 런타임 환경입니다. Node.js는 Window, Linux, Mac OS에서 모두 실행이 가능하고, Node.js 내에 HTTP 서버 라이브러리를 포함하고 있기 때문에 WAS 없이는 동작할 수 없는 PHP와 달리 별도의 WAS 없이도 웹 서버에서 동작할 수 있습니다.Node.js의 등장으로 인해 JavaScript만으로 클라이언트와 서버단을 모두 개발할 수 있게 되었습니다. 추가적인 언어를 학습하지 않아도 JavaScript로 서버단을 개발할 수 있어 프런트엔드(Front-end) 개발자들에게는 Node.js는 더욱 중요한 의미를 지닙니다. PHP와 Node.js의 차이점을 구분하지 못하는 경우가 종종 있습니다. PHP와 Node.js를 보다 명확히 이해하기 위해 각각이 지닌 장점에 대해 정리해보겠습니다.
PHP의 장점
코드와 콘텐츠의 혼합
HTML과 CSS를 활용해 웹사이트를 구축하는 와중에 PHP를 통해 특정 프로세스를 웹에 추가하거나, 데이터베이스에서 가져온 데이터를 웹상의 내용과 결합해 보여주는 것이 가능합니다. 이 경우 바로 PHP 스크립트를 열어 원하는 내용을 추가하기만 하면 됩니다.
단단한 기반을 갖춘 언어
워드프레스나 드루팔, 줌라와 같은 인기 CMS(콘텐츠 관리 시스템)들이 모두 웹 서버 구축에 PHP를 활용하고 있습니다. 또한 짧지 않은 역사로 인해 현존하는 대다수의 웹 서버에는 PHP 언어로 작성된 코드가 넘쳐납니다. 긴 역사로 인해 다양한 플러그인이 개발되었고, 오픈소스로 공개된 코드도 많다는 장점이 있습니다.
진입장벽이 낮은 서버 사이드 언어
PHP는 문법을 익히는 것이 어렵지 않아 진입장벽이 낮은 언어에 속합니다. 그 때문에 웹 개발을 처음 시작하는 입문자가 접근하기 쉽고 관련 레퍼런스 또한 어렵지 않게 찾을 수 있어 어렵지 않게 서버 개발을 할 수 있다는 장점이 있습니다.
Node.js의 장점
코드와 콘텐츠의 분리
PHP와 달리 코드와 컨텐츠를 분리하는 점이 Node.js의 장점이 될 수 있습니다. 코드와 컨텐츠를 하나로 융합할 경우 완성도가 떨어지거나 복잡한 논리 구조로 전락할 가능성이 있습니다. 하지만 이 둘을 분리하는 경우 코드를 체계적으로 관리할 수 있어, 소스 코드를 직접 작성하지 않은 프로그래머도 쉽게 내용을 파악하고 유지/보수를 할 수 있습니다.
Non-blocking I/O 처리 방식
Node.js는 Non-blocking I/O(NIO) 처리 방식을 채택하고 있습니다. 이는 곧 한 개의 요청이 완료될 때까지 시스템이 기다릴 필요가 없음을 의미합니다. 서버 입장에서 NIO는 당연한 처리 방식일 수 있지만, 클라이언트 개발의 전유물이었던 JavaScript로 NIO 처리가 가능한 서버 개발을 할 수 있게 된 점은 그 자체로 의미가 있습니다.
다양한 모듈 생태계와 활발한 커뮤니티
Node.js 관련 패키지를 관리해주는 NPM(Node Package Manager)과 같은 모듈이 여럿 존재합니다. 따라서 모든 기능을 직접 개발할 필요 없이 패키지를 다운받아 사용할 수 있고, 이는 개발 과정을 훨씬 수월하게 만듭니다. 또한 활발한 커뮤니티 활동으로 개발 과정에서 발생할 수 있는 이슈를 해결하고, 다른 개발자들의 지원을 받는 것이 용이합니다.
Node.js는 파일을 업로드하거나 스트리밍하는 애플리케이션, 많은 양의 데이터가 오고 가는 채팅이나 게임 애플리케이션에 적합한 플랫폼으로 손꼽힙니다. 하지만 복잡한 컴퓨팅이 필요하거나 성능이 무거운 애플리케이션에는 Node.js를 채택하지 않는 것이 바람직합니다. 그 이유는 Node.js의 단일 스레드(Single Thread)가 많은 컴퓨팅을 요하는 웹 서비스에 적합하지 않기 때문입니다. 또한 서버단의 로직이 복잡한 경우 콜백 함수의 늪에 빠질 수 있어 서버 체크로직이 많은 경우에도 적합하지 않습니다.
미항공우주국 NASA를 비롯해 넷플릭스나 링크드인, 우버와 같은 글로벌 기업들조차도 적극적으로 Node.js를 도입해 활용하고 있습니다. 또한 가비아의 하이웍스 메신저 서버 또한 Node.js로 개발/운영되고 있습니다. 하이웍스 메신저의 동시 접속자 수가 6만 명에 육박하는 것을 고려하면 Node.js로 충분히 안정적인 서비스를 운영할 수 있음을 알 수 있습니다. JavaScript가 익숙한 개발자들에게 Node.js는 개발 가능한 범위를 넓혀줬다는 점에서 그리고 활발한 커뮤니티 활동으로 지속해서 고도화를 거듭하고 있다는 점에서 앞으로도 그 인기는 쉬이 식지 않을 것으로 보입니다.
서비스하고자 하는 애플리케이션이 Node.js를 도입하기에 적합한 경우라면 간단한 채팅 서버 개발부터 시작해볼 수 있습니다.
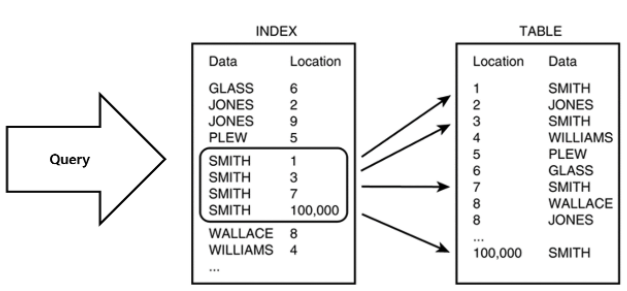
만약 인덱스 처리를 하면 다음과 같이 처리 할 수 있다. 마치 책에 있는 목차라고 생각하면 된다.
실제 DB 관련 작업을 할 때 대부분의 속도 저하는 바로 select문 특히 조건 검색 where절에서 발생하는데 가장 먼저 생각해 볼 수 있는 대안으로 Index를 생각할 수 있기도 하고, SQL 튜닝에서도 Index와 관련된 문제사항과 해결책이 많기 때문이다.
인덱스(Index)를 사용하는 이유 : 조건 검색 Where 절의 효율성
인덱스의 가장 큰 특징은 데이터들이 정렬이 되어있다는 점이다. 이 특징으로 조건 검색이라는 영역이 굉장히 장점이 된다. 테이블을 만들고 안에 데이터가 쌓이게 되면 테이블의 레코드는 내부적으로 순서가 없이 뒤죽박죽 저장된다. 하지만 인덱스 테이블은 데이터들이 정렬되어 있기 때문에 해당조건 where에 맞는 데이터들을 빠르게 찾아낼 수 있다. 위의 Index 테이블에서 SMITH 부분은 정렬이 되어있다.
인덱스(Index)를 사용하는 이유 : 정렬 Order by 절의 효율성
인덱스(Index)를 사용하면 Order by에 의한 Sort 과정을 피할 수 있다. Order by는 굉장히 부하가 많이 걸리는 작업이다. 정렬과 동시에 1차적으로 메모리에서 정렬이 이루어지고 메모리보다 큰 작업이 필요하다면 디스크 I/O도 추가적으로 발생된다. 하지만 인덱스를 사용하면 이러한 전반적인 자원의 소모를 하지 않아도 된다. 이미 정렬 되어 있기 때문에 가져오기만 하면 된다.
인덱스(Index)를 사용하는 이유 : MIN ,MAX의 효율적인 처리가 가능하다.
이것 또한 데이터가 정렬되어 있기에 얻을 수 있는 장점입니다. MIN값과 MAX값을 레코드의 시작값과 끝 값 한건씩만 가져오면 되기에 FULL TABLE SCAN 할 필요없다.
인덱스의 단점
인덱스가 주는 혜택이 있으면 그에 따른 부작용도 있습니다.인덱스의 가장 큰 문제점은 정렬된 상태를 계속 유지 시켜줘야 한다는 점입니다.그렇기에 레코드 내에 데이터값이 바뀌는 부분이라면 악영향을 미칩니다. INSERT, UPDATE, DELETE를 통해 데이터가 추가되거나 값이 바뀐다면 INDEX 테이블 내에 있는 값들을 다시 정렬을 해야겠죠. 그리고 INDEX 테이블, 원본 테이블 이렇게 두 군데에 데이터 수정 작업해줘야 한다는 단점도 있습니다.
그리고 검색시에도 인덱스가 무조건 좋은 것이 아닙니다. 인덱스는 테이블의 전체 데이터 중에서 10~15% 이하의 데이터를 처리하는 경우에만 효율적이고 그 이상의 데이터를 처리할 땐 인덱스를 사용하지 않는 것이 더 낫습니다. 그리고 인덱스를 관리하기 위해서는 데이터베이스의 약 10%에 해당하는 저장공간이 추가로 필요합니다. 무턱대고 INDEX를 만들어서는 결코 안 될 말입니다.
인덱스(Index)의 관리
앞서 설명했듯이 인덱스는 항상 최신의 데이터를 정렬된 상태로 유지해야 원하는 값을 빠르게 탐색할 수 있습니다. 그렇기 때문에 인덱스가 적용된 컬럼에 INSERT, UPDATE, DELETE가 수행된다면 계속 정렬을 해주어야 하고 그에 따른 부하가 발생합니다. 이런 부하를 최소화하기 위해 인덱스는 데이터 삭제라는 개념에서 인덱스를 사용하지 않는다 라는 작업으로 이를 대신합니다.
INSERT: 새로운 데이터에 대한 인덱스를 추가합니다.
DELETE: 삭제하는 데이터의 인덱스를 사용하지 않는다는 작업을 진행합니다.
UPDATE: 기존의 인덱스를 사용하지 않음 처리하고, 갱신된 데이터에 대해 인덱스를 추가합니다.
인덱스 생성 전략
생성된 인덱스를 가장 효율적으로 사용하려면 데이터의 분포도는 최대한으로 그리고 조건절에 호출 빈도는 자주 사용되는 컬럼을 인덱스로 생성하는 것이 좋습니다. 인덱스는 특정 컬럼을 기준으로 생성하고 기준이 된 컬럼으로 정렬된 Index 테이블이 생성됩니다. 이 기준 컬럼은 최대한 중복이 되지 않는 값이 좋습니다. 가장 최선은 PK로 인덱스를 거는것이겠죠. 중복된 값이 없는 인덱스 테이블이 최적의 효율을 발생시키겠고. 반대로 모든 값이 같은 컬럼이 인덱스 컬럼이 된다면 인덱스로써의 가치가 없다고 봐야 할 것입니다.
1.조건절에 자주 등장하는 컬럼
2.항상 = 으로 비교되는 컬럼
3.중복되는 데이터가 최소한인 컬럼 (분포도가 좋은) 컬럼
4.ORDER BY 절에서 자주 사용되는 컬럼
5.조인 조건으로 자주 사용되는 컬럼
B * Tree 인덱스
인덱스에는 여러가지 유형이 있지만 그 중에서도 가장 많이 사용하는 인덱스의 구조는 밸런스드 트리 인덱스 구조입니다. 그리고 B TREE 인덱스 중에서도 가장 많이 사용하는것은 B*TREE 와 B+TREE 구조를 가장 많이 사용되는 인덱스의 구조입니다.
B * Tree 인덱스는 대부분의 DBMS 그리고 오라클에서 특히 중점적으로 사용하고 있는 가장 보편적인 인덱스입니다. 구조는 위와 같이 Root(기준) / Branch(중간) / Leaf(말단) Node로 구성됩니다. 특정 컬럼에 인덱스를 생성하는 순간 컬럼의 값들을 정렬하는데, 정렬한 순서가 중간 쯤 되는 데이터를 뿌리에 해당하는 ROOT 블록으로 지정하고 ROOT 블록을 기준으로 가지가 되는 BRANCH블록을 정의하며 마지막으로 잎에 해당하는 LEAF 블록에 인덱스의 키가 되는 데이터와 데이터의 물리적 주소 정보인 ROWID를 저장합니다.
인덱스 사용 예시
인덱스 생성
--문법
CREATE INDEX [인덱스명] ON [테이블명](컬럼1, 컬럼2, 컬럼3.......)
--예제CREATE INDEX EX_INDEX ON CUSTOMERS(NAME,ADDRESS);
--예제 컬럼 중복 XCREATE[UNIQUE] INDEX EX_INDEX ON CUSTOMERS(NAME,ADDRESS);
위와같이 쿼리문을 작성하면 INDEX를 생성할 수 있습니다. UNIQUE 키워드를 붙이면 컬럼값에 중복값을 허용하지 않는다는 뜻입니다.
인덱스 조회
SELECT*FROM USER_INDEXES WHERE TABLE_NAME ='CUSTOMERS';
인덱스를 생성하면 USER_INDEXES 시스템 뷰에서 조회할 수 있습니다. 방금 CUSTOMERS 테이블에 만들었던 EX_INDEX가 첫번째 ROW에 있군요.
인덱스 삭제
--문법DROP INDEX [인덱스 명]
--예제DROP INDEX EX_INDEX;
인덱스는 조회성능을 극대화하기 위해 만든 객체인데 너무 많이 만들면 insert, delete, update시에 부하가 발생해 전체적인 데이터베이스 성능을 저하합니다. 고로 안쓰는 인덱스는 삭제시키는것이 좋습니다.
인덱스 리빌드
인덱스를 리빌드하는 이유
인덱스 파일은 생성 후 insert, update, delete등을 반복하다보면 성능이 저하됩니다. 생성된 인덱스는 트리구조를 가집니다. 삽입,수정,삭제등이 오랫동안 일어나다보면 트리의 한쪽이 무거워져 전체적으로 트리의 깊이가 깊어집니다. 이러한 현상으로 인해 인덱스의 검색속도가 떨어지므로 주기적으로 리빌딩하는 작업을 거치는것이 좋습니다.
인덱스(Index)를 남발하지 말아야 하는 이유
개발을 진행할때에 대개 개발서버와 운영서버를 나누어서 관리합니다. 대부분 개발서버에서 개발을 할때에는 적은량의 데이터를 가지고 로직검사를 하며 로직검사에 통과한 코드들이 운영서버에 업데이트가 되죠. 하지만 개발서버에는 잘 동작하던 로직들이 운영서버의 많은량의 데이터들을 처리하다보면 성능이슈가 많이 발생합니다. 그 성능이슈의 주요원인은 바로 데이터베이스에 있습니다. 데이터베이스 관리자는 성능문제가 발생하면 가장 빨리 생각하는 해결책이 인덱스 추가 생성입니다.
문제를 쉽게 해결을 위해 쿼리 속도 문제가 날때마다 인덱스를 추가하는것은 바람직하지 못합니다. 성능 이슈가 나서 인덱스를 만들고 또 다른 SQL에서문에서 성능이슈가 발생하여 또 인덱스를 만들었다고 합시다. 이렇게 문제가 발생할때마다 인덱스를 생성하면서 인덱스가 계속 추가되면 생성된 인덱스를 참조하는 하나의 쿼리문을 빠르게는 만들 수 있지만 전체적인 데이터베이스의 성능 부하를 초래합니다. 그렇기에 인덱스를 생성하는것 보다는 SQL문을 좀 더 효율적으로 짜는 방향으로 나가야합니다. 인덱스생성은 꼭 마지막 수단으로 강구해야 할 문제입니다.
정리
인덱스(Index)는 데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조를 일컫는다. 인덱스는 테이블 내의 1개의 컬럼, 혹은 여러 개의 컬럼을 이용하여 생성될 수 있다. 고속의 검색 동작뿐만 아니라 레코드 접근과 관련 효율적인 순서 매김 동작에 대한 기초를 제공한다. 인덱스를 저장하는 데 필요한 디스크 공간은 보통 테이블을 저장하는 데 필요한 디스크 공간보다 작다. (왜냐하면 보통 인덱스는 키-필드만 갖고 있고, 테이블의 다른 세부 항목들은 갖고 있지 않기 때문이다.) 관계형 데이터베이스에서는 인덱스는 테이블 부분에 대한 하나의 사본이다.
인덱스는 고유 제약 조건을 실현하기 위해서도 사용된다. 고유 인덱스는 중복된 항목이 등록되는 것을 금지하기 때문에 인덱스의 대상인 테이블에서 고유성이 보장된다.
위에서 말씀드렸듯이 검색의 속도를 높여주기 때문입니다. 근데 어떻게 검색의 속도를 높여주는것이며 어떻게 사용되는지 감이 안잡히기 때문에 이 내용에 대하여 설명해보겠습니다!
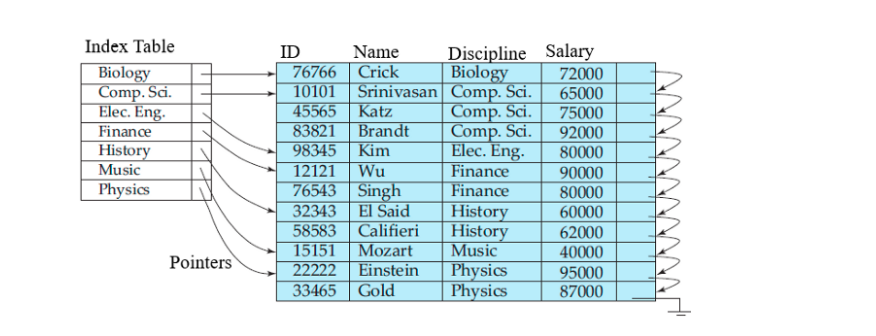
예를 들어 오른쪽 테이블의 Physics값을 조회해본다고 가정해보겠습니다. 해당 과정을 표현하면
Select 절을 활용하여 조회
어느 위치에 데이터가 존재하는지 모르기 때문에 Table Full scan 진행
이처럼 테이블의 전체 데이터를 조회하기 때문에 데이터의 수가 적은 테이블이면 영향이 덜하겠지만,
만약 수십만개의 데이터가 들어있는 테이블의 데이터를 조회하는데 조회 기능이 자주 사용되는 서비스라면 성능이 굉장히 떨어지게 될것입니다!
그렇기 때문에 왼쪽과 같이 인덱스를 따로 생성하여 해당 데이터만 빠르게 찾을 수 있게 됨으로써 다이나믹한 성능 향상을 기대할 수 있는 부분입니다!
어떻게 동작하는것인가?
위의 예시를 이어서 설명하겠습니다!
해당 테이블을 생성시 생성하고 싶은 인덱스 컬럼을 지정
생성 후 인덱스 조회 시, WHERE 절이 포함된 쿼리로 조회
인덱스로 저장된 Key-Value값을 참조해서 결과 출력
위와 같이 진행되게 됩니다!
다음과 같이 B-tree 알고리즘을 통하여 조회하게 되고, 리프노드로 도착하기 까지 자식 노드에 대한 포인터가 저장되어 있어 탐색에 있어서 한개의 경로만 조회하면 되기 때문에 조회에 있어서 굉장히 효율적인 알고리즘이라고 합니다!
언제 사용해야하나?
주로 검색 및 조회를 할때 큰 효율성을 낼 수 있다고 합니다!
기본적으로 이진 트리를 사용하기 때문에 이미 정렬이 되어있는 상태에서 추가, 수정, 삭제가 자주 일어나게 되면 인덱스에서도 마찬가지로 해당 동작들이 수행되기 때문에 성능 저하를 초래할 수 있다고 합니다!
예를 들어, 한 쇼핑몰에 여러가지 카테고리가 존재할때 해당 카테고리의 상품들을 조회할때 이러한 인덱스 기능을 잘 사용하게 된다면 큰 효율을 발휘하게 되지만, 인스타그램같은 소셜 서비스들은 끊임없이 게시글이 작성되고 수정, 삭제되기 때문에 오히려 인덱싱을 하게되면 엄청난 성능 저하가 되기 때문입니다!
인덱스 선정 기준
인덱스는 하나 혹은 여러 개의 컬럼에 대해 설정할 수 있습니다. 단일 인덱스를 여러 개 생성할 수도, 여러 컬럼을 묶어 복합 인덱스를 설정할 수도 있습니다.
그러나 무조건 많이 설정하는게 검색 속도 향상을 높여주지는 않습니다. 인덱스는 데이터베이스 메모리를 사용하여 테이블 형태로 저장되므로 개수와 저장 공간은 비례합니다. 따라서,
조회시 자주 사용하고
고유한 값 위주로
인덱스를 설정하는게 좋습니다.
그럼 어떤 컬럼에 인덱스를 설정하는게 좋을까?
인덱스는 한 테이블당 보통 3~5개 정도가 적당합니다. 물론 테이블의 목적 등에 따라 개수는 달라질 수 있습니다.
인덱스는 컬럼을 정해서 설정하는 것이므로 후보 컬럼의 특징을 잘 파악해야 합니다. 아래 4가지 기준을 사용하면 효율적으로 인덱스를 설정할 수 있습니다.
카디널리티 (Cardinality)
선택도 (Selectivity)
활용도
중복도
카디널리티 (Cardinality)
✔️카디널리티가 높을 수록 인덱스 설정에 좋은 컬럼입니다. = 한 컬럼이 갖고 있는 값의 중복 정도가 낮을 수록 좋습니다.
컬럼에 사용되는 값의 다양성 정도, 즉 중복 수치를 나타내는 지표입니다. 후보 컬럼에 따라 상대적으로 중복 정도가 낮다, 혹은 높다로 표현됩니다.
예를 들어, 10개 rows를 가지는 ‘학생’ 테이블에 ‘학번’과 ‘이름’ 컬럼이 있다고 해봅시다.
‘학번’은 학생마다 부여 받으므로 10개 값 모두 고유합니다.
중복 정도가 낮으므로 카디널리티가 낮습니다.
‘이름’은 동명이인이 있을 수 있으니 1~10개 사이의 값을 가집니다.
중복 정도가 ‘학번’에 비해 높으므로 카디널리티가 높다고 표현할 수 있습니다.
면접 답변 : 고유한 값이 도출되는 것을 기반으로 인덱싱을 잡는 편 입니다. 예를들면 상품명이나 옵션보다는 상품번호, 주문번호, 배송번호 등 고유한 값에 인덱싱을 거는 편입니다.
선택도 (Selectivity)
✔️ 선택도가 낮을 수록 인덱스 설정에 좋은 컬럼입니다. 5~10% 정도가 적당합니다.
데이터에서 특정 값을 얼마나 잘 선택할 수 있는지에 대한 지표입니다. 선택도는 아래와 같이 계산합니다.
= 컬럼의 특정 값의 row 수 / 테이블의 총 row 수 * 100 = 컬럼의 값들의 평균 row 수 / 테이블의 총 row 수 * 100
예를 들어, 10개 rows를 가지는 ‘학생’ 테이블에 ‘학번’, ‘이름’, ‘성별’ 컬럼이 있다고 해봅시다. 학번은 고유하고, 이름은 2명씩 같고, 성별은 남녀 5:5 비율입니다.
‘학번’의 선택도 = 1/10*100 = 10%
SELECT COUNT(1) FROM '학생' WHERE '학번' = 1;(모두 고유하므로 특정 값: 1)
‘이름’의 선택도 = 2/10*100 = 20%
SELECT COUNT(1) FROM '학생' WHERE '이름' = "김철수";(2명씩 같으므로 특정 값: 2)
‘성별’의 선택도 = 5/10*100 = 50%
SELECT COUNT(1) FROM '학생' WHERE '성별' = F;(5명씩 같으므로 특정 값: 5)
즉, 선택도는 특정 필드값을 지정했을 때 선택되는 레코드 수를 테이블 전체 레코드 수로 나눈 것입니다.
즉 , 위의 예시에선 '학번' 정도를 index로 잡는 것이 좋다.
면접 답변 : 고유한 값이 도출되는 것을 기반으로 인덱싱을 잡는 편 입니다. 예를들면 상품명이나 옵션보다는 상품번호, 주문번호, 배송번호 등 고유한 값에 인덱싱을 거는 편입니다.
활용도
✔️활용도가 높을 수록 인덱스 설정에 좋은 컬럼입니다.
해당 컬럼이 실제 작업에서 얼마나 활용되는지에 대한 값입니다. 수동 쿼리 조회, 로직과 서비스에서 쿼리를 날릴 때 WHERE 절에 자주 활용되는지를 판단하면 됩니다.
면접 답변 : 저희 팀에서 자주 사용하는 기초 데이터 중 order_srl, buy_srl 같은 활용도가 높은 컬럼을 인덱싱하는 편 입니다.
중복도
✔️중복도가 없을 수록 인덱스 설정에 좋은 컬럼입니다.
중복 인덱스 여부에 대한 값입니다.
인덱스 성능에 대한 고려 없이 마구잡이로 설정하거나, 다른 부서 다른 작업자의 분리된 요청으로 같은 컬럼에 대해 인덱스가 중복으로 생성된 경우를 볼 수 있습니다.
인덱스도 속성을 가집니다. 인덱스는 테이블 형태로 생성되므로, 속성을 컬럼으로 관리합니다.
면접 답변 : 타팀에서 같은 테이블을 사용할 때 이미 인덱싱 처리되어 있는 것을 확인하고 인덱싱 신청을 하는 편 입니다.