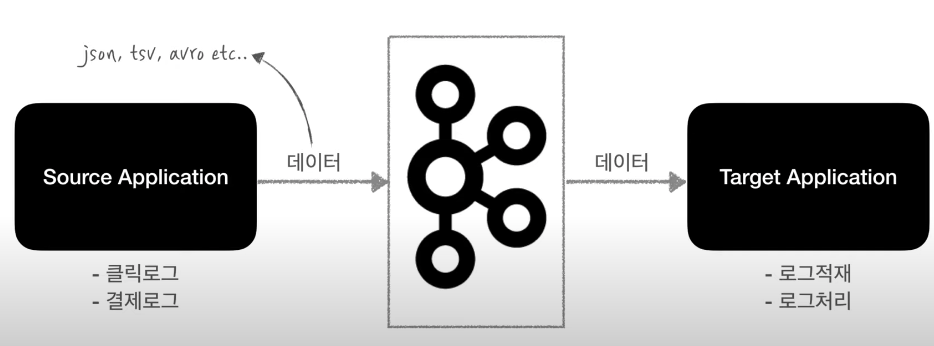
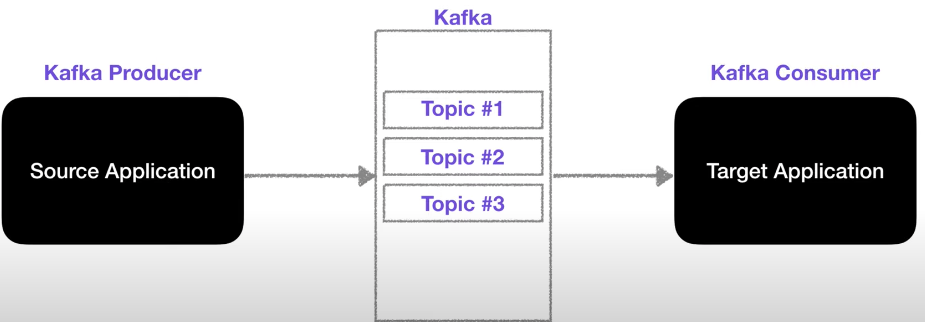
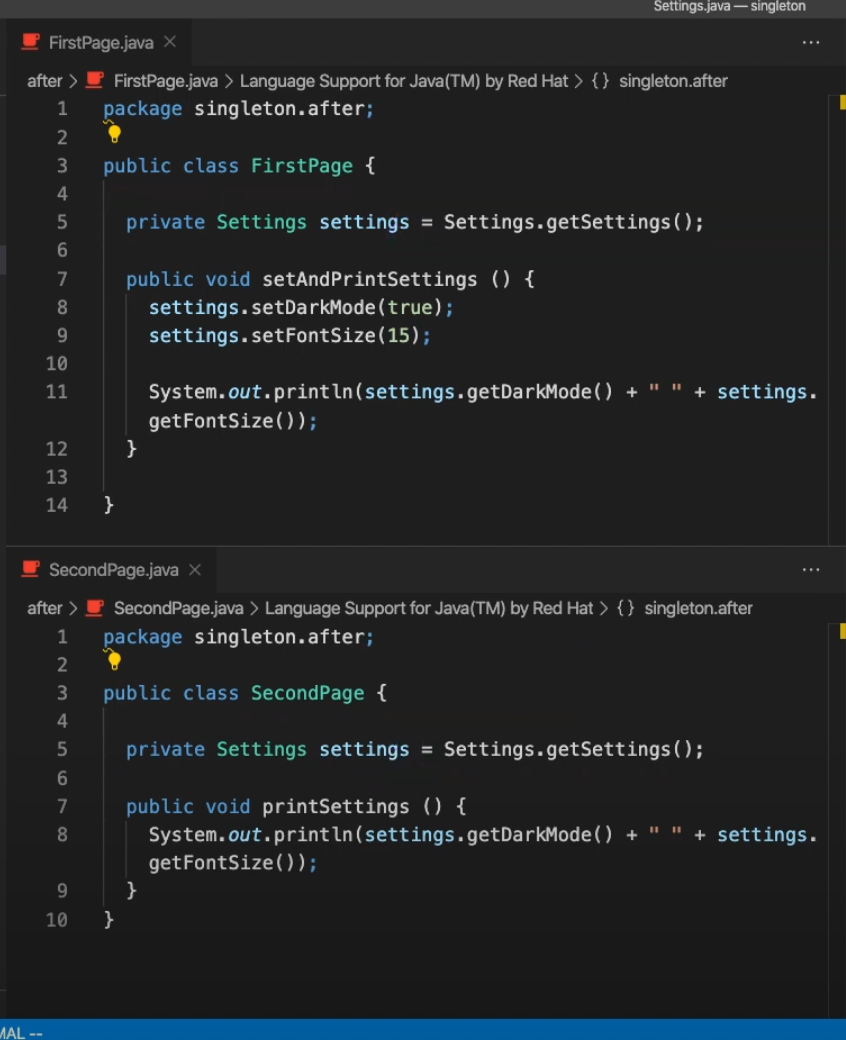
다음과 같이 매우 복잡한 구조로 변모했다. 추후에 변경이 발생하였을 때 유지 보수하기 매우 어려워 졌다.
이러한 어려운 점을 해결하기 위해 링크드인에서 내부적으로 개발하였고 현재는 오픈소스로 뿌려줬다.
카프카의 탄생배경
2011년 링크드인에 의해 처음 공개 되었다. 링크드인은 당시 데이터파이프라인 처리를 위해 기존 redis나 rabbitMQ등 여러 애플리케이션들을 혼용해서 사용해야 했다. 하지만 이런 애플리케이션 각각의 특징이 워낙 뚜렷하다보니 데이터 처리에 있어 파편화가 심각했다.
카프카는 데이터 처리를 각각 여러 애플리케이션에서 처리하는 것이 아니라 중앙 집중화 및 실시간 스트림 처리한다. (=중추신경)
실시간 데이터 처리와 데이터 파이프라인으로 용이한 시스템
왜 많이 사용할까?
High throughput message capacity
짧은 시간 내에 엄청난 양의 데이터를 컨슈머까지 전달 가능하다.
파티션을 통한 분산 처리가 가능하기 때문에 데이터 양이 많아 질수록 컨슈머 갯수를 늘려 병렬처리가 가능하고 이를 통해 데이터 처리를 더욱 빠르게 할 수 있습니다.
Scalability와 Fault tolerant
확장성이 뛰어나다. 이미 기존에 카프카 브로커가 있다해도 브로커를 추가해서 수평 확장이 가능하다.
이렇게 수평확장된 브로커가 죽더라도 이미 replica로 복제된 데이터는 안전하게 보관되어 있으므로 복구하여 처리가능하다.
Undeleted log
다른 플랫폼과 달리 카프카 토픽에 들어간 데이터는 컨슈머가 데이터를 가지고 가더라도 데이터가 사라지지 않습니다.
다른 플랫폼에서는 복잡한 방식이다.
하지만 카프카에서는 컨슈머의 그룹 아이디만 다르다면 카프카 토픽에 들어간 데이터를 손실하지 않고 재사용이 가능하다.
데이터 처리가 많은 카카오, 네이버에서만 사용 가능할까?
아니요. 카프카는 소규모 스타트업에서 적용하기에도 굉장히 좋다. 이유는 스타텁에서 중요한 것은 안정적인 운영과 빠른 확장성이다. 소규모로 시작하여도 추후를 생각해 확장성이 용이하다는 점이 좋다.( = scale out : 카프카 클러스터 내부의 브로커 갯수를 늘려서 원활하게 데이터를 처리할 수 있습니다.)
Kafka features
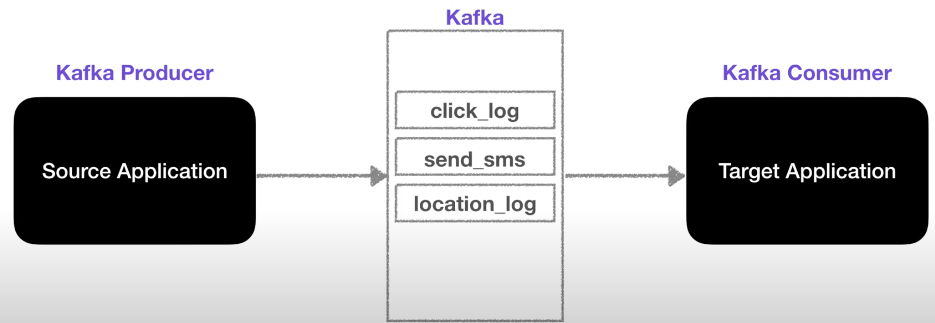
카프카는 source와 target의 커플링을 약하게 하기 위해서 탄생했다.
source단에서 클릭로그, 결제로그를 다양한 포맷으로 전달할 수 있다.
카프카는 다양한 Topic 을 담을 수 있는데 쉽게 생각해서 queue라고 볼 수 있다.
queue에 데이터를 넣는 역할은 Producer가 하고 queue에서 데이터를 가져가는 역할은 Consumer가 한다. 둘다 라이브러로 되어있으므로 언제든지 구현 가능하다. 결론적으로 Kafka는 아주 유연한 고가용성 queue라고 볼 수 있다.
Kafka Topic
카프카에서는 토픽을 여러개 생성할 수 있다. 토픽은 데이터 베이스의 테이블이나 파일시스템의 폴더와 유사한 성징을 가지고 있다.
Kafka의 토픽은 다음과 같이 click_log, send_log 등 이름을 명시하면 유지 보수시 편리하게 관리할 수 있다.
Kafka Topic의 내부
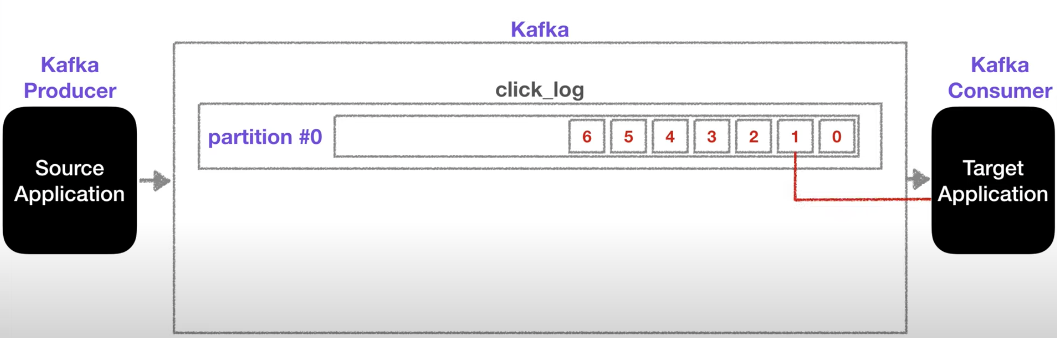
하나의 토픽은 여러개의 파티션으로 구성될 수 있으며 첫 번째 파티션 번호는 0번부터 시작한다.
컨슈머는 가장 오래된 순서대로 가져간다.(선입선출) 더 이상 데이터가 없다면 또 다른 데이터가 들어 올때까지 대기한다.
특이한 점은 컨슈머가 데이터를 가져가더라도 데이터는 삭제 되지 않고 그대로 남는다.
그렇다면 남는 데이터들은 누가 가져가는 것일까? 바로 새로운 컨슈머가 붙었을 때 다시 0번부터 가져가서 사용가능하다.
(단, 다른 컨슈머여야 하고 auto.offset.reset = earliest 여야 합니다.)
이처럼 사용할 경우 동일한 데이터에 대해서 2번 사용이 가능한데 이는 카프카를 사용하는 아주 중요한 이유이기도 하다.
* 클릭로그를 분석하기 위해 ES에 저장하기도 하고, 클릭로그를 백업하기 위해 Haddop에 저장하기도 한다. 각각은 다른 기능을 위해서 사용하는 topic이다.
만약 다음과 같이 파티션을 하나 더 늘렸다면(7번 직전에) 7번은 어디로 들어갈까?
1) 만약 키가 null이고, 기본 파티셔너 사용할 경우 -> 라운드 로빈
2) 만약 키가 있고, 기본 파티셔너 사용할 경우
-> 키의 해시(hash) 값을 구하고, 특정 파티션에 할당
따라서 해당 경우는 라운드 로빈에 의해서 파티션#1에 할당된다.
그 이후에 다음과 같이 라운드 로빈으로 쭉 적재된다.
파티션을 늘리는 것은 아주 조심해야한다.
이유는 파티션은 늘리는 것은 마음대로이지만 줄이는 것은 불가능하다. 왜 그러면 파티션을 늘리는 것일까? 파티션을 늘리면 컨슈머의 갯수를 늘려서 데이터 처리를 분산 시킬 수 있다.
이렇게 데이터가 늘어나면 파티션의 데이터는 언제 삭제 될까요?
삭제되는 타이밍은 옵션에 따라 다르다. 다음을 저장하면 일정한 기간, 용량 동안만 데이터를 저장하고 적절하게 삭제 될 수있다.
log.retentios.ms : 최대 record 보존 시간
log.retention.byte : 최대 record 보존 크기(byte)
카프카 프로듀셔
프로듀서는 데이터를 카프카에 보내는 역할을 한다. 예를들어 엄청난 양의 클릭로그들을 대량으로, 그리고 실시간으로 카프카에 적재할 때 프로듀셔를 사용할 수 있다.
프로듀서는 이름 그대로 데이터를 생산하는 역할을 합니다. 즉 데이터를 kafka topic에 생성한다는 말이다.
카프카 프로듀서의 역할
Topic에 해당 메시지를 생성
특정 Topic으로 데이터를 publish
처리 실패 / 재시도
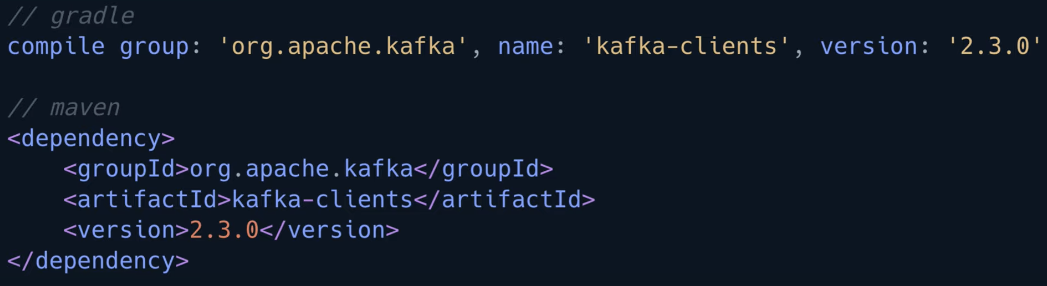
카프카를 사용하기 위해서는 위와 같이 아파치 카프카 라이브러리를 추가 해야한다. 주의해야할 점은 버전입니다. 카프카는 브로커 버전과 클라이언트 버전의 하위호환성이 완벽하게 모든 버전에 대해서 지원하지는 않습니다.
//자바 프로퍼티 객체를 통해 프로듀서의 설정 정의
Properties configs = new Properties();
configs.put("bootstrap.servers", "localhost:9092");
configs.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
configs.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
부트 스트랩 서버 설정을 localhost:9092를 바라보게 설정
카프카의 주소 목록(ip, port)을 되도록 2개 이상 권장 --> 둘 중 하나의 브로커가 고장나도 다른 한쪽으로 로드밸런싱 하기 위해서이다.
Key와 Value 설정을 StringSerializer로 직렬화하여 삽입한다.
시리얼라이저는 키 혹은 value를 직렬화하기 위해 사용하는데 Byte array, String, Integer 시리얼라이즈를 사용할 수 있습니다.
키는 메시지를 보내면, 토픽의 파티션이 지정될 때 쓰인다.
카프카 프로듀서 인스턴스 생성
//카프카 프로듀서 인스턴스 생성
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(configs);
전송할 객체 생성 및 전송
//전송할 객체 생성 및 전송
ProducerRecord record = new ProducerRecord<String,String>("click_log" , "login");
//키 포함
ProducerRecord record = new ProducerRecord<String,String>("click_log" ,"1","login");
producer.send(record);
producer.close();
click_log 토픽에 login 이라는 value를 보낸다. 만약 키를 포함하고 싶을 경우 2번째 파라미터에 담아서 보낸다. (위에서는 1)
send 메서드 : send 메서드에 Recod를 보내면 전송이 이루어진다.
close 메서드 : 종료해준다.
Input(프로듀서)
파티션 내부
설명
경우 1 : key null 인 경우
- key가 null인 경우, 파티션#0에 보내는 경우 - 아래와 같이 한개 씩 쌓이기 시작한다. - 만약 파티션이 2개이면 라운드 로빈 방식으로 차곡 차곡 쌓인다.
경우 2 : key 있는 경우
-key가 각각 1, 2 이다. 카프카는 key를 특정한 hash값으로 변경 시켜 파티션과 1:1 매칭을 시킵니다.
- 만약 파티션이 한개 더 추가되면 어떻게 될까? 키와 파티션의 갯수가 일치하지 않기 때문에 매칭이 보장되지 않고 일관성 없게 쌓인다.
카프카 브로커와 Replication, ISR
카프카의 핵심 구성요소이다.
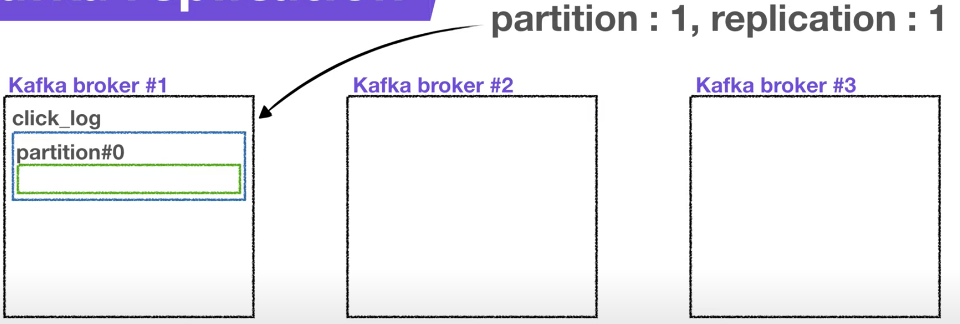
카프카가 설치되어 있는 서버 단위를 말한다. 보통 3개 이상의 브로커로 구성하여 사용하는 것을 권장한다.
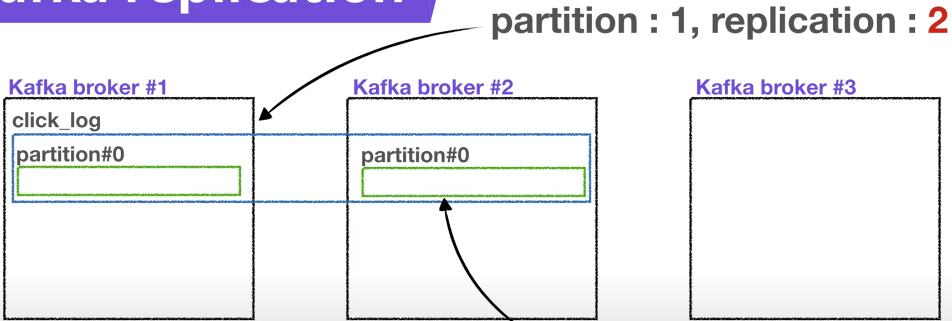
만약 파티션이 1개이고 replicatiion이 1인 topic이 존재하고 브로커가 3대라면 브로커 3대 중 1대에 해당 토픽의 정보(데이터)가 저장됩니다.
replication(복제)
replication은 partition의 복제를 뜻합니다.
replication이 1인 경우
replication이 1이라면 partition(복제본)이 한개만 존재한다는 뜻이다.
Replication이 2이 인 경우
만약 replication이 2라면 partition은 원본 1개와 복제본 1개로 총 2개가 존재한다.
Replication이 3이 인 경우
만약 replication이 2라면 partition은 원본 1개와 복제본 2개로 총 3개가 존재한다. 원본 1은 Leader Partition, 복제본 2개는 Follower partition이다.
단, broker에 갯수에 따라서 replica의 갯수가 제한되는데 브로커갯수가 3이면 replica은 4가 될수 없다는 뜻이다. 즉 replication <= broker 이다.
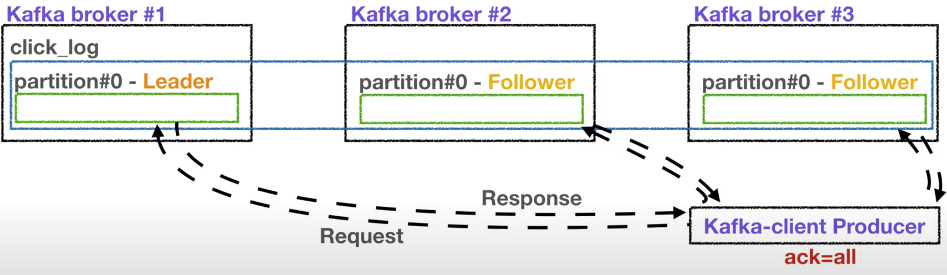
ISR(In Sync Replica)
leader partition + follower partition = ISR
왜 Replication을 사용할까?
Replication은 partition의 고가용성을 위해 사용한다. replication 2 이상일 경우는 브로커 한개가 죽더라도 다른 복제본 브로커로 돌릴수 있기 때문에 사용하면 좋다. follwer partition이 leader partition역할을 승계하게 되는 것 입니다.
프로듀서의 Ack 옵션
프로듀서가 토픽의 파티션에 데이터를 전달할 때, 전달받는 주체가 바로 Leader Partition이다.
프로듀서는 ack = 0, 1, all 세가지 상세 옵션이 있다.
Ack = 0 인 경우
Leader Partition에 값을 전달한 후 응답 값을 받지 않습니다. 따라서 데이터 유실이 일어났는지 알 수없습니다. 단 속도는 빠릅니다.
Ack = 1 인 경우
1인 경우는 Leader partition에 데이터를 전송하고 응답은 받지만 적절하게 replication 되었는지는 확인하지 않아 데이터 유실가능성이 있습니다. 단 속도는 빠릅니다.
Ack = 2 인 경우
replication까지 복제가 잘 되었는지 확인하는 절차까지 받습니다. 따라서 데이터 유실가능성은 없다. 단 속도가 현저히 느리다.
Replication 갯수가 많아지면..?
replication이 고가용성을 위해 중요한 역할을 한다면 broker갯수 만큼 무조건 늘리는게 답일까?
아니다. 그렇다면 브로커의 리소스 사용량도 늘어나게 된다. 즉, 적당한게 좋다. 3개이상의 브로커를 사용하는 경우 replication을 3으로 해두는 것을 추천한다.
카프카 설치 및 실행
brew를 이용하여 kafka를 다운로드한다.카프카를 사용하기 위해 다양한 디펜던시가 있고 그중에 대표적인 것이 zookeeper이다.
brew install kafka
카프카를 실행하기 위해서는 먼저 zookeeper를 실행한다.
brew services start zookeeper
카프카를 실행한다.
brew services start kafka
토픽을 만들고 데이터를 넣고, 조회하기
먼저, 카프카에서는 다양한 script를 제공한다. 하단의 명령을 통해 script를 확인 할 수 있다. 하단의 명령어를 통해 카프카가 깔린 곳으로 이동한다.
brew info kafka
.../usr/local/Cellar/kafka/3.1.0
cd /usr/local/Cellar/kafka/3.1.0/bin
*미들웨어 서비스하는 애플리케이션들을 보다 효율적으로 아키텍처들을 역결하는 요소들로 작동하는 소프트웨어를 뜻한다.
메시지 브로커에 있는 큐에 데이터를 보내고 받는 프로듀서와컨슈머를 통해 메시지를 통신하고 네트워크를 맺는 용도로 사용해왔습니다.
특징
메시지를 받아서 적절히 처리하고 나면 즉시 또는 짧은 시간 내에 삭제되는 구조이다.
데이터를 보내고, 처리하고 삭제한다.
ex ) 레디스 큐, 레빗엠 큐
이벤트 브로커
이벤트 브로커는 메시지 브로커 역할을 할 수 있다.
특징
이벤트 또는 메시지라고도 불리는 이 레코드 이 장부를 딱 하나만 보관하고 인덱스를 통해 개별 엑세스를 관리합니다.
업무상 필요한 시간동안 이벤트를 보존할 수 있다.
이벤트 브로커는 삭제하지 않는다.
왜 데이터를 처리했는데 삭제하지 않을까? 단서는 '이벤트' 라는 단어에 숨어있다. 이벤트 브로커는 서비스에서 나오는 이벤트를 마치 데이터 베이스에 저장하듯이 이벤트 브로커의 큐에 저장하는데요. 이렇게 저장하면서 얻는 명확한 이점이 있다. 첫번째 이점은 딱 한번 일어난 이벤트 데이터를 브로커에 저장함으로써 단일 진실 공급원으로 사용할 수 있다. 두번째는 장애가 발생했을 때 장애가 일어난 시점부터 재처리할 수 있습니다. 세번째는 많은 양의 실시간 스트림 데이터를 효과적으로 처리할 수 있다는 특징이 있다. 그외에도 다양한 MSA에서 중요한 역할을 맡을 수 있다.
ex) 카프카나 aws 키네시스가 대표적이다.
이벤트 브로커로 클러스터를 구축하면 이벤트 기반 마이크로 서비스 아키텍처로 발전하는데 아주 중요한 역할을 한다. 메시지 브로커로서도 사용할 수 있으니깐 팔방미인이다.
JPA 장점 - 우선 CRUD SQL을 작성할 필요가 없다. - JPA가 제공하는 네이티브 SQL 기능을 사용해서 직접 SQL을 작성할 수도 있고, 데이터베이스 쿼리 힌트도 사용할 수 있는 방법이 있다.(성능걱정x) - 개발 단계에서 MySQL DB를 사용하다가 오픈 시점에 갑자기 Oracle로 바꿔도 코드를 거의 수정할 필요가 없다.
목차
강의 : JPA 소개 - SQL 중심적인 개발의 문제점
SQL 직접 다룰 때 발생하는 문제점
반복 또 반복
// 1. 회원 등록용 SQL 작성
String sql = "INSERT INTO MEMBER(MEMBER_ID,NAME) VALUES(?,?)";
//2. 회원 객체의 값을 꺼내서 등록 SQL에 전달한다.
pstmt.setString(1, member.getMemberId();
pstmt.setString(2, member.getName());
//3.JDBC API를 사용해서 SQL을 실행한다.
pstmt.executeUpdate(sql);
객체를 데이터베이스에 CRUD 하려면 너무 많은 SQL과 JDBC API를 코드로 작성해야 한다는 점이다.
그리고 테이블마다 이런 비슷한 일을 반복해야 하는데, 개발하려는 애플리케이션에서 사용하는 데이터베이스 테이블이 100개라면 무수히 많은 SQL을 작성해야 하고 이런 비슷한 일은 100번은 더 반복해야 한다.
데이터 접근 계층 (DAO)을 개발하는 일은 이렇듯 지루함과 반복의 연속이다.
SQL에 의존적인 개발
갑자기 회원의 연락처도 함께 저장해달라는 요구사항이 추가 되었다. = 새롭게 쿼리를 다 짜야한다...
등록코드 변경
public class Member{
private String memberId;
private String name;
private String tel; //추가
...
}
연락처를 저장할 수 있도록 INSERT SQL을 수정했다.
String sql = "INSERT INTO MEMBER (MEMBER_ID, NAME, TEL) VALUE(?,?,?)";
그 다음 회원 객체의 연락처 값을 꺼내서 등록 SQL에 전달했다.
pstmt.setString(3, member.getTel());
조회 코드 변경
다음 처럼 회원 조회용 SQL을 수정한다.
SELECT MEMBER_ID, NAME, TEL FROM MEMBER WHERE MEMBER_ID = ?
//조회 결과를 Member 객체에 추가로 매핑한다.
String tel = rs.getString("TEL");
member.setTel(tel); //추가
JPA와 문제해결
JPA를 사용하면 객체를 데이터베이스에 저장하고 관리할 때, 개발자가 직접 SQL을 작성하는 것이 아니라 JPA가 제공하는 API를 사용하면 된다. 그러면 JPA가 개발자 대신에 적절한 SQL을 생성해서 데이터베이스에 전달한다.
저장 기능
jpa.persist(member); //저장
조회 기능
String memberId = "helloId";
Member member = jpa.find(Member.class, memberId); //조회
수정 기능
Member member = jpa.find(member.class, memberId);
member.setName("이름변경") // 수정
JPA는 별도의 수정 메서드를 제공하지 안흔다. 대신에 객체를 조회해서 값을 변경만 하면 트랜잭션을 커밋할 때 데이터베이스에 적절한 UPDATE SQL이 전달된다. (마법 같은 일-> 추후에 공부)
연관된 객체 조회
Member member = jpa.find(Member.class. memberId);
Team team = member.getTeam(); //연관된 객체 조회
JPA는 연관된 객체를 사용하는 시점에 적절한 SELECT SQL을 실행한다. 따라서 JPA를 사용하면 연관된 객체를 마음껏 조회할 수 있다.(마법 같은 일2->추후에 공부)
패러다임의 불일치
비즈니스 요구사항을 정의한 도메인 모델도 객체로 모델링하면 객체지향 언어가 가진 장점들을 활용할 수 있다. 문제는 이렇게 정의한 도메인 모델을 저장할 때 발생한다.
객체의 기능은 클래스에 정의되어 있으므로 객체 인스턴스의 상태인 속성만 저장 했다가 필요할 때 불러 와서 복구하면 된다.
관계형 데이터베이스는 데이터 중심으로 구조화되어 있고, 집합적인 사고를 요구한다. 그리고 객체 지향에서 이야기하는 추상화, 상속, 다형성 같은 개념이 없다.
객체와 관계형 데이터베이스는 지향하는 목적이 서로 다르므로 둘의 기능과 표현 방법도 다르다. 이것을 객체와 관계형 데이터베이스의 패러다임 불일치 문제라 한다. 따라서 객체 구조를 테이블 구조에 저장하는 데는 한계가 있다.
문제는 이런 객체와 관계형 데이터베이스 사이의 패러다임 불일치 문제를 해결하는 데 너무 많은 시간과 코드를 소비하는 데 있다.
상속
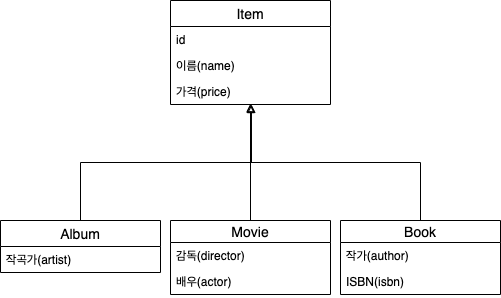
객체는 상속 이라는 기능을 가지고 있지만 테이블은 상속 이라는 기능이 없다. 따라서 패러다임의 불일치가 시작한다.
객체 상속 모델
위의 관계형데이터에서 만약 Album을 조회한다. 1. 각각의 테이블에 따른 조인 SQL 작성 2. 각각의 객체 생성 3. 상상만 해도 복잡... 4. 더 이상 설명은 생략한다. 5. 그래서 DB에 저장할 객체에는 상속 관계 안쓴다!!!
만약 자바 컬렉션에 저장하면?
list.add(album);
자바 컬렉션을 조회하면?
Album album = list.get(albumId);
//부모 타입으로 조회 후 다형성 활용
Item item = list.get(albumId);
JDBC를 이용한 상속 구현
JDBC API를 사용해서 상속 관계의 객체를 저장 하려면 부모 객체에서 부모 데이터만 꺼내서 INSERT SQL을 작성하고 자식 객체에서 자식 데이터만 꺼내서 INSERT SQL을 별도로 작성해야 한다.
class Member {
String id; // MEMBER_ID 컬럼 사용
Long temId; // TEAM_ID FK 컬럼 사용
String username; // USERNAME 컬럼 사용
}
class Team {
Long id; // TEAM_ID PK 사용
String name; // NAME 컬럼 사용
}
그런데 여기서 TEAM_ID 외래 키의 값을 그대로 보관하는 teamId 필드에는 문제가 있다. 객체는 연관된 객체의 참조를 보관해야 다음처럼 참조를 통해 연관된 객체를 찾을 수 있어야 하는데 하지 못하게 된다.
이런 방식을 따르면 좋은 객체 모델링은 기대하기 어렵고 결국 객체 지향의 특징을 잃어버리게 된다.
엔티티를 직접 참조하는 것과 간접 참조하는 것에 대한 장단점이 무엇이 있을까? 직접 참조 장점 : 연관된 데이터를 한번에 추출할 수 있다.단점 : 연관된 데이터에 대한 수정이 발생할 경우 영향의 범위가 커질 수 있다. 간접 참조 장점 : 복잡도를 낮출 수 있고, 응집도를 높이고 결합도를 낮출 수 있다.단점 : 연관된 데이터를 한번에 추출 하려면 구현해야 하는 로직이 복잡하다.
참조를 사용하는 객체 모델
class Member {
String id; // MEMBER_ID 컬럼 사용
Long temId; // TEAM_ID FK 컬럼 사용
Team team; // 참조로 연관관계를 맺는다.
}
class Team {
Long id; // TEAM_ID PK 사용
String name; // NAME 컬럼 사용
}
JDBC를 이용한 연관 관계 구현
만약 JDBC로 저장하는 로직을 만들기 위해서는 team 필드를 TEAM_ID 외래 키 값으로 변환해야 한다.
member.getId(); // MEMBER_ID PK에 저장
member.getTeam().getId(); // TEAM_ID FK에 저장
member.getUsername(); // USERNAME 컬럼에 저장
또는 조회하는 로직에도 객체를 생성하고 연관관계를 설정해서 반환하는 로직이 필요하다.
public Member find(String memberId) {
// SQL 실행
...
Member member = new Member();
...
// 데이터베이스에서 조회한 회원 관련 정보를 모두 입력
Team team = new Team();
...
// 데이터베이스에서 조회한 팀 관련 정보를 모두 입력
// 회원과 팀 관계 설정
member.setTeam(team);
return member;
}
JPA와 연관관계 구현
개발자는 회원과 팀의 관계를 설정하고 회원 객체를 저장하면 된다. JPA는 team의 참조를 외래 키로 변환해서 적절한 INSERT SQL을 데이터베이스에 전달한다.
member.setTeam(team);
jpa.persist(member);
객체를 조회할 때 외래 키를 참조로 변환하는 일도 JPA가 처리 해준다.
Member member = jpa.find(Member.class, memberId);
Team team = member.getTeam();
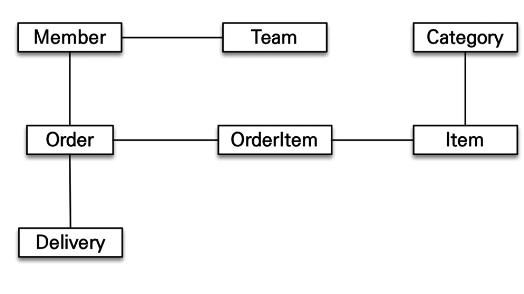
객체 그래프 탐색
SQL을 직접 다루면 처음 실행하는 SQL에 따라 객체 그래프를 어디까지 탐색할 수 있는지 정해진다. 이것은 객체지향 개발자에겐 너무 큰 제약이다. 왜냐하면 비즈니스 로직에 따라 사용하는 객체 그래프가 다른데 언제 끊어질지 모를 객체 그래프를 함부로 탐색할 수는 없기 때문이다.
결국, 어디까지 객체 그래프 탐색이 가능한지 알아보려면 데이터 접근 계층인 DAO를 열어서 SQL을 직접 확인해야 한다.
class MemberService {
...
public void process() {
Member member = memberDAO.find(memberId);
member.getTeam(); // member->team 객체 그래프 탐색이 가능한가?
member.getOrder().getDelivery(); // ???
}
}
위의 코드에서 memberDAO.find에 주목하자. 그것은 무엇을 조회했을까? 무엇을 조회했길래 '팀 정보(getTeam)', '배송+주문 정보'를 가져올수 있을까? 알수없다. 즉, find구현한 Repo를 가서 무슨 쿼리인지를 까봐야한다. 즉 위의 코드는 신뢰가 안간다.
JPA를 사용하면 연관된 객체를 신뢰하고 마음껏 조회할 수 있다. 이 기능은 실제 객체를 사용하는 기점까지 데이터베이스 조회를 미룬다고 해서 지연 로딩이라 한다.
// 처음 조회 시점에 SELECT MEMBER SQL
Member member = jpa.find(Member.class, memberId);
Order order = member.getOrder();
order.getOrderDate(); // Order를 사용하는 시점에 SELECT ORDER SQL
여기서 마지막 줄의 order.getOrderDate() 같이 실제 Order 객체를 사용하는 시점에 JPA는 데이터베이스에서 ORDER 테이블을 조회한다.
JDBC로 구현한 비교
데이터베이스와 같은 로우로 조회했지만 객체의 동일성 비교에는 실패한다.
class MemberDAO {
public Member getMember(String memberId) {
String sql = "SELECT * FROM MEMBER WHERE MEMBER_ID + ?";
...
// JDBC API, SQL 실행
return new Member(...);
}
}
String memberId = "100";
Member member1 = memberDAO.getMember(memberId);
Member member2 = memberDAO.getMember(memberId);
member1 == member2; // false
JPA로 구현한 비교(=자바 컬렉션)
String memberId = "100";
Member member1 = jpa.find(Member.class,memberId);
Member member2 = jpa.find(Member.class,memberId);
member1 == member2; // true
정리
객체 모델과 관계형 데이터베이스 모델은 지향하는 패러다임이 서로 다르다. 더 어려운 문제는 객체 지향 애플리케이션 답게 정교한 객체 모델링을 할수록 패러다임의 불일치 문제가 더 커진다는 점이다. 이는 결국 객체 모델링은 힘을 잃고 점점 데이터 중심의 모델로 변해간다. JPA는 패러다임의 불일치 문제를 해결 해주고 정교한 객체 모델링 유지하게 도와준다.
데이터 주도 설계와 도메인 주도 설계의 장단점은 무엇일까?
강의 JPA소개 - JPA소개
JPA란 무엇인가?
JPA(Java Persistence API)는 자바 진영의 ORM 기술 표준이다.
그렇다면 ORM이란 무엇일까?
ORM?
ORM(Object-Relational Mapping)은 이름 그대로 객체와 관계형 데이터베이스를 매핑 한다는 뜻이다. ORM 프레임워크는 객체와 테이블을 매핑 해서 패러다임의 불일치 문제를 개발자 대신 해결해준다.
따라서 객체 측면에서는 정교한 객체 모델링을 할 수 있고 관계형 데이터베이스는 데이터베이스에 맞도록 모델링하면 된다. 그리고 둘을 어떻게 매핑 해야 하는지 매핑 방법만 ORM 프레임워크에게 알려주면 된다
왜 JPA를 사용해야 하는가?
생산성
이전에 DAO에서 작업하던 지루하고 반복적인 일은 JPA가 대신 처리 해준다. 이런 기능들을 사용하면 데이터베이스 설계 중심의 패러다임을 객체 설계 중심으로 역전시킬 수 있다.
유지보수
이전엔 엔티티 필드 하나만 수정해도 관련된 DAO 로직의 SQL문을 모두 변경해야 했다. 반면에 JPA는 대신 처리해주므로 필드를 추가하거나 삭제해도 수정해야 할 코드가 줄어든다.
패러다임의 불일치 해결
성능
JPA는 애플리케이션과 데이터베이스 사이에 동작하여 최적화 관점에서 시도해 볼 수 있는 것들이 많다. 예를 들어 동일한 조건으로 조회 했을 경우엔 SELECT SQL을 한 번만 데이터베이스에 전달하고 두 번째 조회한 회원 객체는 재사용할 수 있다.
Member member = memberDAO.find(memberId); //selcet * from member
Team team = member.getTeam();
String teamName = team.getName(); //select * from team
즉시로딩
Member member = memberDAO.find(memberId); //select M.*, T.* from member join team
Team team = member.getTeam();
String teamName = team.getName();
JPA, Hibernate, Spring Data JPA 차이점
JPA(=껍데기)
JPA공부를 시작함에 있어서 가장헷갈렸던 부분이 JPA와 Hibernate와의 관계였다. 동영상강의에서는 처음에 EntityManager를 활용하여 Data를 삭제 저장 업데이트를 하지만, 실제 실무에서는 EntityManager를 사용하지 않고 Repository 인터페이스 만을 이용해서 JPA를 사용한다.
JPA는 Java Persistence API의 약자로,자바 어플리케이션에서 관계형 데이터베이스를 사용하는 방식을 정의한 인터페이스이다. 여기서 중요하게 여겨야 할 부분은, JPA는 말 그대로 인터페이스라는 점이다. JPA는 특정 기능을 하는 라이브러리가 아니다. 마치 일반적인 백엔드 API가 클라이언트가 어떻게 서버를 사용해야 하는지를 정의한 것처럼, JPA 역시 자바 어플리케이션에서 관계형 데이터베이스를 어떻게 사용해야 하는지를 정의하는 한 방법일 뿐이다.
JPA는 단순히 명세이기 때문에 구현이 없다. JPA를 정의한javax.persistence패키지의 대부분은interface,enum,Exception, 그리고 각종Annotation으로 이루어져 있다. 예를 들어, JPA의 핵심이 되는EntityManager는 아래와 같이javax.persistence.EntityManager라는 파일에interface로 정의되어 있다.
package javax.persistence;
import ...
public interface EntityManager {
public void persist(Object entity);
public <T> T merge(T entity);
public void remove(Object entity);
public <T> T find(Class<T> entityClass, Object primaryKey);
// More interface methods...
}
Hibernate(JPA를 구현한 구현체)
Hibernate는 JPA 명세의 구현체이다. javax.persistence.EntityManager와 같은 JPA의 인터페이스를 직접 구현한 라이브러리이다.
위 사진은 JPA와 Hibernate의 상속 및 구현 관계를 나타낸 것이다. JPA의 핵심인EntityManagerFactory,EntityManager,EntityTransaction을 Hibernate에서는 각각SessionFactory,Session,Transaction으로 상속받고 각각Impl로 구현하고 있음을 확인할 수 있다.
“Hibernate는 JPA의 구현체이다”로부터 도출되는 중요한 결론 중 하나는 JPA를 사용하기 위해서 반드시 Hibernate를 사용할 필요가 없다는 것이다. Hibernate의 작동 방식이 마음에 들지 않는다면 언제든지 DataNucleus, EclipseLink 등 다른 JPA 구현체를 사용해도 되고, 심지어 본인이 직접 JPA를 구현해서 사용할 수도 있다. 다만 그렇게 하지 않는 이유는 단지 Hibernate가 굉장히 성숙한 라이브러리이기 때문일 뿐이다.
Spring Data JPA
필자는 Spring으로 개발하면서 단 한 번도 EntityManager를 직접 다뤄본 적이 없다. DB에 접근할 필요가 있는 대부분의 상황에서는 Repository를 정의하여 사용했다. 아마 다른 분들도 다 비슷할 것이라 생각한다. 이 Repository가 바로 Spring Data JPA의 핵심이다.
Spring Data JPA는 Spring에서 제공하는 모듈 중 하나로, 개발자가 JPA를 더 쉽고 편하게 사용할 수 있도록 도와준다. 이는JPA를 한 단계 추상화시킨 Repository라는 인터페이스를 제공함으로써 이루어진다. 사용자가Repository 인터페이스에 정해진 규칙대로 메소드를 입력하면, Spring이 알아서 해당 메소드 이름에 적합한 쿼리를 날리는 구현체를 만들어서 Bean으로 등록해준다.
Spring Data JPA가 JPA를 추상화했다는 말은,Spring Data JPA의 Repository의 구현에서 JPA를 사용하고 있다는 것이다. 예를 들어,Repository인터페이스의 기본 구현체인SimpleJpaRepository의 코드를 보면 아래와 같이 내부적으로EntityManager을 사용하고 있는 것을 볼 수 있다.