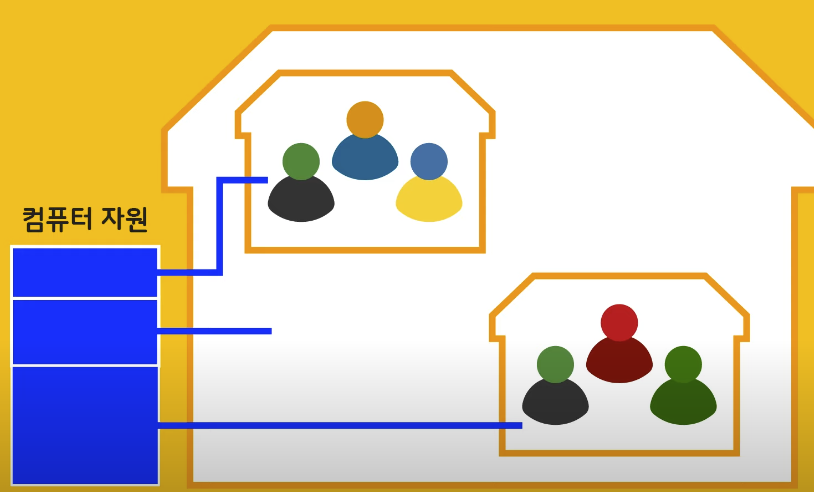
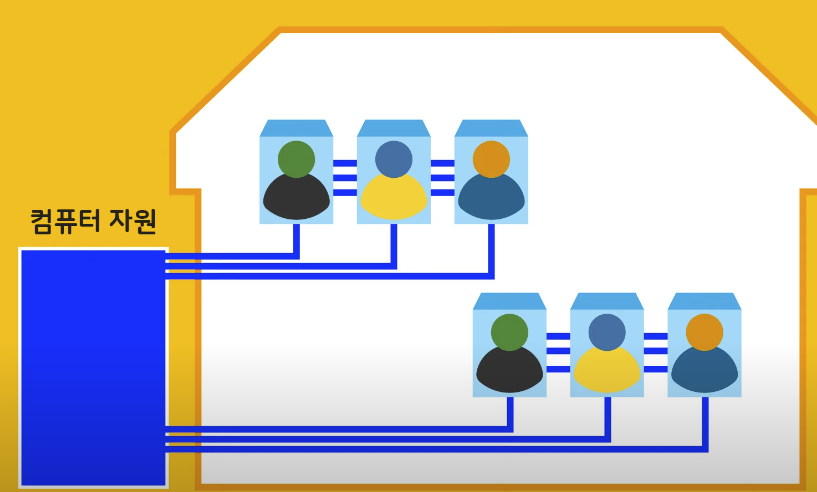
즉시로딩(EAGER:이거)은 예측이 어렵고, 어떤 SQL이 실행될지 추적하기 어렵다. 특히 JPQL을 실행할 때 N+1 문제가 자주 발생한다.
실무에서 모든 연관관계는 지연로딩(LAZY)으로 설정해야 한다.
연관된 엔티티를 함께 DB에서 조회해야 하면, fetch join 또는 엔티티 그래프 기능을 사용한다.
@XToOne(OneToOne, ManyToOne) 관계(어쩌고 One관계)는 기본이 즉시로딩(EAGER)이므로 반드시 직접 지연로딩으로 설정해야 한다.
OneToMany는 기본이 LAZY이다.
예시
기존 LAZY(지연로딩)에서 EAGER(즉시로딩)로 바꾼다면
public class Order {
@ManyToOne(fetch = FetchType.LAZY) ->@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "member_id")
private Member member; //주문 회원
}
N+1 문제
em.find같은 경우(한 건 조회)에서는 문제가 발생하지 않는다.
JPQL과 같이 'select o From order o;' 의 경우에는 SQL select * from order로 번역되고 100개가 조회 되었다고 가정하면,
member가 EAGER이면 해당 100개가 member를 가져오기 위해서 100번 발생한다. 왜냐하면 EAGER라는게 조인해서 한 번에 가져온다는 것이 아니고 order를 조회하는 시점에 member 테이블을 꼭 같이 조회하겠다는 뜻
노트북을 하나 사면 간단한 프로젝트로 라도 개발 환경 셋팅을 하루 종일 해야한다. 만약 개발자가 서버를 돌리기 위한 환경을 구축한다면 훨씬 더 많은 리소스가 들 것이다. (언어, 웹서버, 데이터베이스, 자동배포툴 등등..) 서로 잘 동작할 수 있도록 버전관리도 잘 해줘야한다. 서버도 스케일업 할 수도있으며 해당 서버들도 모두 환경 셋팅을 해줘야한다. 도커는 이런 문제를 깔끔하게 해준다.
해결방법
먼저 각 요쇼들이 설치된 모습을 '이미지'란 형태로 박제해서 저장한다. '이미지'는 각 제품 마다 공식적으로 제공되는 이미지도 있고 개인이 설정할 수 있다. git에 저장하는 것 처럼 '이미지'를 도커허브에 업로드돼서 공유되고 다운받아질 수 있다. (어느 컴퓨터에서 동작할 수 있도록 녹화하는 느낌) 도커허브에서 언제든지 다운로드 가능하며 도커 컨테이너라고 불리는 독립된 가상 공간을 만들어내서 복원한다.
VirtualBox 같은 가상컴퓨터 처럼 돌릴 수 있는데 도커는 가상 컴퓨팅과는 또 다른 구조이다. 가상컴퓨팅은 물리적 자원을 서로 분할 해서 쓰기 때문에 성능에 한계가 생기게 된다. 도커는 실행 환경만 독립적으로 돌리는 거라서 컴퓨터에 직접 설치 한 것이랑 별 차이 없는 성능을 낼 수 있고 가상 컴퓨팅보다 훨씬 가볍고 빠르게 각각을 설치, 사용이 가능하다.
위의 코드는 간단한 웹 프로그램이다. 실행 하려면 node와 http-server가 로컬 컴퓨터에 깔려있어야한다. 하지만, 내 컴퓨터에는 아직 셋팅이 안되었다고 가정하자.
docker 사용하기
docker run -it node / sudo docer run -it node
위의 명령어를 사용한다.
위의 명령어를 사용하면 docker에서 뭔가를 다운로드하며 콘솔창처럼 입력이 가능한 모드로 바뀐다. run 명령어는 허브상의 이미지를 내 컴퓨터에서 해동해서 컨테이너로 만든다. 이미지는 컨테이너를 무한대로 재생산 할 수 있다. 즉 이미지는 무한생산이 가능한 컨테이너 조립키드라고 생각해도 된다.
-it 명령어 : 이 컨테이너를 연다음 그 환경안에서 CLI를 사용한다는 것이다. 컨테이너를 만든다음 컨테이너에 난 창문으로 그 안에 있는 근무자랑 대화를 하겠다는 뜻 그래서 자바 스크립트 콘솔을 사용할 수 있다.
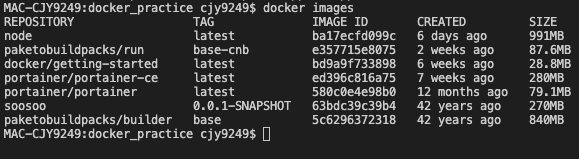
docker images
위의 명령어를 사용하면 내 로컬에 도커 이미지들을 확인 가능하다.
docker ps //현재 사용하고 있는 컨테이너 표시
docker ps -a //사용하고 있지는 않은 모든 컨테이너 표시
위의 명령어를 사용하면 docker container 내부의 다양한 정보를 보여준다. 단 지금 사용하고 있는 환경만 보여준다.
docker exec -it agitated_poincare bash
위의 NAMES에 하나를 골라 위의 명령어를 실행하면 내부로 접근가능하다. 가상의 리눅스 환경으로 들어간 것이다.
ls 로 둘러보기
ls 명령어로 둘러 보기도 가능하다. 종료는 ctrl + c
# 이미지 생성 명령어 (현 파일과 같은 디렉토리에서)
# docker build -t {이미지명} .
docker build -t frontend-img .
도커 이미지 다운로드 중...
docker 이미지 생성 완료
# 컨테이너 생성 & 실행 명령어
# docker run --name {컨테이너명} -v $(pwd):/home/node/app -p 8080:8080 {이미지명}
docker run --name frontend-con -v ${pwd}:/home/node/app -p 8080:8080 frontend-img
docker --name frontend-con : 이전에는 도커에서 임의 컨테이너명을 지어줬지만, 이번에는 생성될 컨테이너의 이름을 내가 정한다.
-v 옵션 : volume의 약자로 도커에서 볼륨이란, 컨테이너와 특정 폴더를 공유하는 것을 말한다. 내가 작성한 코드 (pwd:현재위치)가 home/node/app이라는 사전같은 곳에 부록으로 들어가는 것으로 언제든지 부록에서 꺼내서 컨테이너에서 사용할 수 있게 한다. 따라서 위에 CMD 명령어로 사용가능한 것이다.
-p 옵션 : 포트 옵션이다. 집의 내선번호와 컨테이너를 연결하는 것이다. 집에 8080과 컨테이너 8080을 연결한다. 만약 한개 더 컨테이너를 만든다면 -p8080:8081로 연결한다 (8081:컨티이너 내선번호) 동시에 컨테이너 8080에 접속할 순 없다.
Data Base image 말기
#이미지 만들기
docker build -t database-img .
#이미지 돌리기
docker run --name database-con -p 3306:3306 database-img
기존 front 방식과 동일하며 db인 mysql은 3306포트가 기본이고 집에서도 3306으로 연결한다.
위와 같이 3306 포트가 열린 것을 확인할 수 있다.
위와 같이 3306 포트가 열린 것을 확인할 수 있다.
만약 위 처럼 한다면 해당 터미널을 사용하지 못한다. 따라서 디비는 다음과 같이 사용한다.
docker run --name database-con -d 3306:3306 database-img
-p가 아닌 -d로 사용하면 해당 터미널 사용가능.
한방에 도커를 설정 하는 방법
docker-compose.yml 활용
위는 docker-compose.yml 이며, db, front, backend 모두가 작성되어있다.
#실행(경로는 맨위)
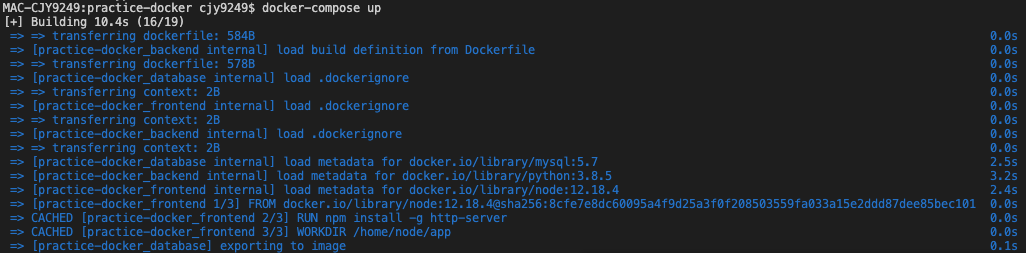
docker-compose up
시간이 꽤 걸린다...
완료...!
docker file
docker file은 나만의 설계도 이다.
docker file은 front, back, db에 각각 하나 씩 무조건 들어가 있다.
FROM 명령어 : 해당 버전을 명시한다.
RUN 명령어 : 이미지 생성 과정에서 실행할 명령어
CMD 명령어는 이미지로 부터 컨테이너가 만들어져 가동될 때 기본적으로 바로 실행하는 명령어 (시작프로그램)
도커 허브 탐방하기
도커 허브 사이트에 방문하여 node를 검색하면 위와 같이 공식 이미지가 올라와 있다. 도커의 이미지라는 것은 리눅스 컴퓨터의 특정 상태를 캡처해서 박제(클라우드에 올려놓은 것) 해놓은 것을 의미한다. (즉, 위의 집에 입주 시켜놓은 상태)
for(int i = 0 ; i < n ; i ++){
String tempStr = br.readLine();
arr[i] = tempStr.substring(4,tempStr.length()-4);
}
k = k - 5;
beforeCheck();
dfs(0,0);
System.out.println(max);
}
while (!q.isEmpty()) {
Pair now = q.poll(); // 큐의 맨앞
int nowx = now.x; //현재 토마토 x값
int nowy = now.y; //현재 토마토 y값
for (int i = 0; i < 4; i++) {
int nextX = nowx + dx[i];
int nextY = nowy + dy[i];
//범위 밖 패스
if (nextX < 0 || nextY < 0 || nextX >= N || nextY >= M) {
continue;
}
if (arr[nextX][nextY] != 0) {
continue;
}
//다음값 = 현재 일수 + 1
arr[nextX][nextY] = arr[nowx][nowy] + 1;
q.add(new Pair(nextX, nextY));
}
}
답 도출
토마토 상자에서 가장 큰 숫자를 출력
토마토 상자에 만약 0이 있다면 (익지 못한 상황) -1 출력 종료
int max = 0;
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
if (arr[i][j] == 0) {
//토마토가 모두 익지 못한 상황이라면 -1 을 출력한다.
System.out.println(-1);
return;
}
max = Math.max(max, arr[i][j]);
}
}
//그렇지 않다면 최대값을 출력한다.
System.out.println(max - 1);
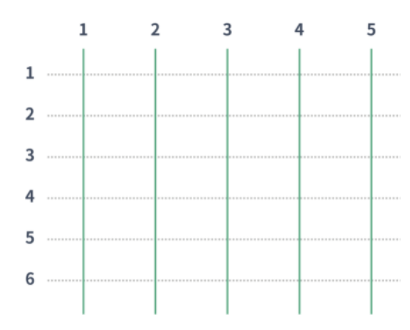
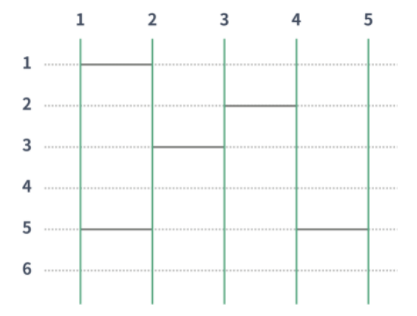
N x M 사다리가 주어진다. N은 세로선, M은 가로점선이다. 위는 N=5, M=6이다.
H는 6이다. (가로실선을 놓아 연결할 수 있는 최대 갯수)
초록선은 세로선이며, 점선은 가로선이다. 가로선은 인접한 두 세로선사이를 연결해야한다. 단, 두 가로선이 연속하거나 서로 접하면 안된다.
1번말은 3번으로 갔고, 2번말은 2번으로 갔다.
사다리를 가로선에 추가해서, 사다리 게임의 결과를 조작하려고 한다. 이때 i번 세로선의 결과가 i번이 나와야 한다. 그렇게 하기 위해 추가해야하는 가로선 갯수의 최소값을 구하는 프로그램을 작성하시오.
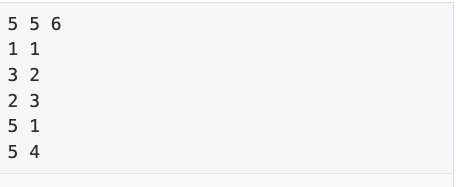
입력 예시
설명
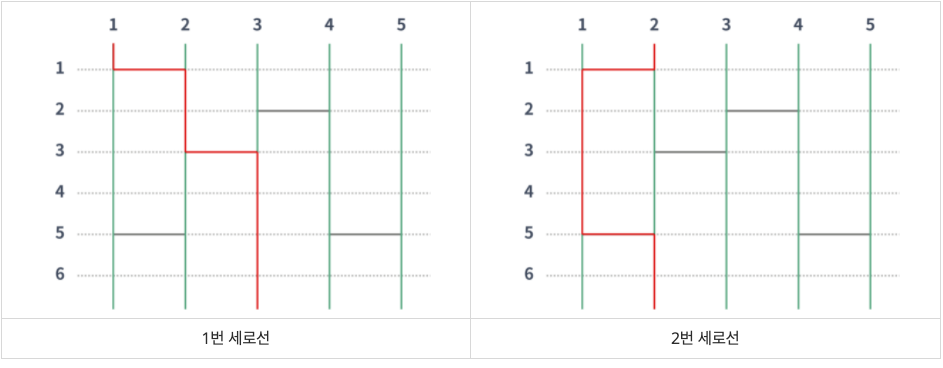
가로선의 정보는 a, b로 주어진다. b번 세로선과 b+1 세로선을 a번 점선 위치에서 연결했는의미이다. ex) 5 1 : 1번과 2번 세로선을 5번 가로선에서 연결한다. 2 3 : 3번과 4번 세로선을 3번 가로선에서 연결한다.
출력
i번 세로선의 결과가 i번이 나오도록 사다리 게임을 조작하려면, 추가해야 하는 가로선 개수의 최소값을 출력한다. 만약 정답이 3보다 크면 -1을 출력한다. 또 불가능한 경우에도 -1을 출력한다.
풀이방법
당연히 최소라는 말이 많이 나와 bfs로 접근했지만 시간초과 뜸.
dfs로 접근
check 함수 생성 (가로선을 그을 때 마다 가능한지 여부 체크)
모든 경우에 가로선을 하나 씩 늘려감
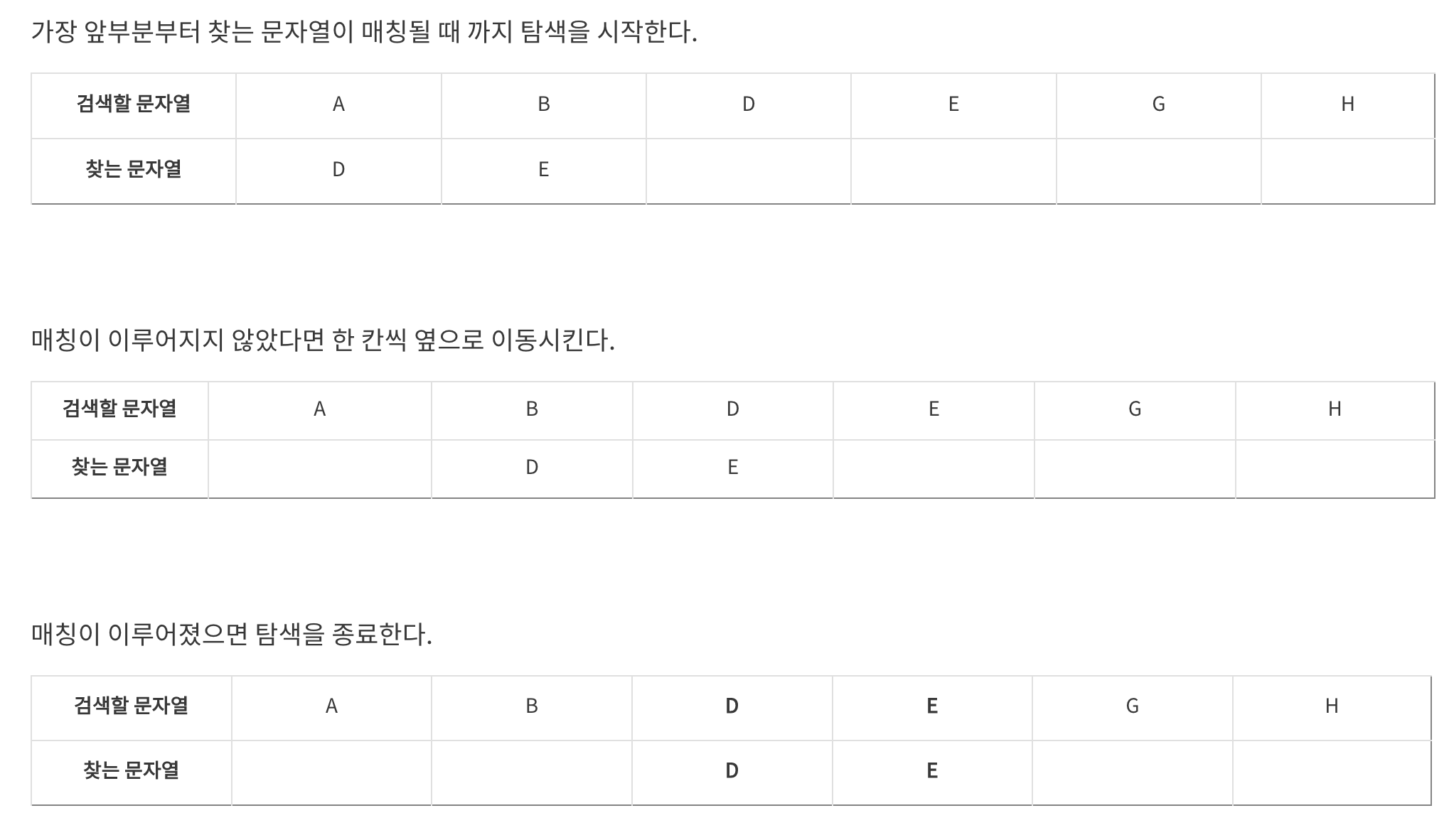
Check 함수
세로줄을 검사하면서 1을 만나면 우측으로(y++), 2를만나면 좌측으로(y--) 해준다.
해당 말의 결과와 숫자가 같으면 true 해주고 계속 다른 말 검사, 해당 말의 결과와 숫자가 다르면 바로 false return
public static boolean check(){
for(int i =0 ; i < n ; i++){
int x = 1, y = i; // 가로줄1번부터 시작, y는 말
for(int j = 0 ; j < h ; j++){
if(map[x][y] == 1) { //만약 해당 칸이 1이면 우측으로 이동 = y++
y++;
}
else if(map[x][y] ==2){
y--; //만약 해당 칸이 2면 왼쪽으로 이동 y--;
}
x++; //만약 해당 칸에 가로선이 없으면 아래로 이동
}
if(y != i) return false; // 결국 해당 말이 결과가 다르다면 바로 false
}
return true;
}
dfs 부분
가로선을 그을 수 있는 곳 (=map[i][j] = 0 && map[i][j+1] ==0 인곳)에 모두 가로선을 그어준다.
가로선을 긋고 바로 check해준다. 되면 해당 count값을 반환 안되면, 가로선을 그을 수 있을 만큼 계속 그어준다.
public static void dfs(int x, int count){
if(answer < count) return ;
else{
if(check()){
answer = count;
return;
}
}
for(int i = x ; i < h + 1 ; i++){
for (int j = 1; j < n ; j++){
if(map[i][j] == 0 && map[i][j+1] ==0){
map[i][j] = 1;
map[i][j+1] = 2;
dfs(i,count+1);
map[i][j] = map[i][j+1] = 0 ;
}
}
}
}
insert, update, delete (Command)의 성능을희생하고 대신select (Query)의 성능을 향상시킵니다. 여기서 주의하실 것은 update, delete 행위가 느린것이지,update, delete를 하기 위해 해당 데이터를 조회하는것은 인덱스가 있으면 빠르게 조회가 됩니다. 인덱스가 없는 컬럼을 조건으로 update, delete를 하게 되면 굉장히 느려 많은 양의 데이터를 삭제 해야하는 상황에선 인덱스로 지정된 컬럼을 기준으로 진행하는것을 추천드립니다.
B-tree 인덱스
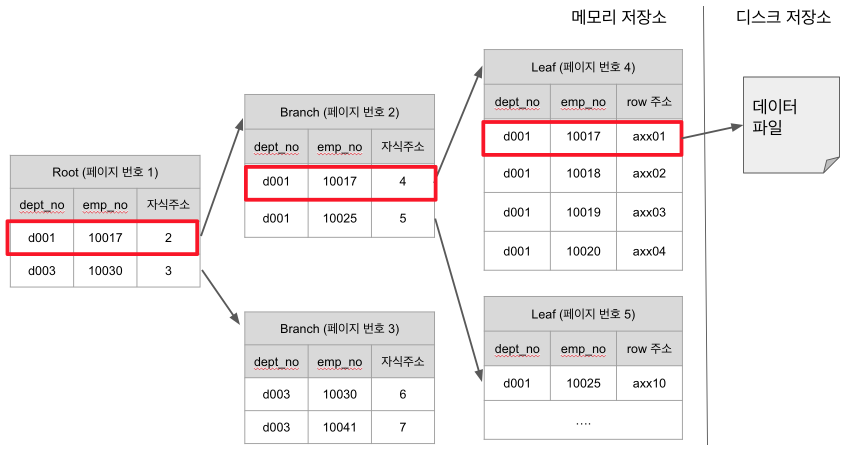
인덱스 탐색은 Root -> Branch -> Leaf -> 디스크 저장소 순으로 진행됩니다.
예를 들어 Branch (페이지번호 2) 는 dept_no가 d001이면서 emp_no가 10017 ~ 10024까지인 Leaf의 부모로 있습니다.
즉,dept_no=d001 and emp_no=10018로 조회하면 페이지 번호 4인 Leaf를 찾아 데이터파일의 주소를 불러와 반환하는 과정을 하게 됩니다.
인덱스의두번째 컬럼은 첫 번째 컬럼에 의존해서 정렬되어 있습니다.
즉, 두번째 컬럼의 정렬은 첫번째 컬럼이 똑같은 열에서만 의미가 있습니다.
만약 3번째, 4번째 인덱스 컬럼도 있다면 두번째 컬럼과 마찬가지로 3번째 컬럼은 2번째 컬럼에 의존하고, 4번째 컬럼은 3번째 컬럼에 의존하는 관계가 됩니다.
디스크에서 읽는 것은 메모리에서 읽는것보다 성능이 훨씬 떨어집니다.
결국 인덱스 성능을 향상시킨다는 것은 디스크 저장소에 얼마나 덜 접근하게 만드느냐, 인덱스 Root에서 Leaf까지 오고가는 횟수를 얼마나 줄이느냐에 달려있습니다.
인덱스의 갯수는 3~4개 정도가 적당합니다.
너무 많은 인덱스는 새로운 Row를 등록할때마다 인덱스를 추가해야하고, 수정/삭제시마다 인덱스 수정이 필요하여 성능상 이슈가 있습니다.
인덱스 역시 공간을 차지합니다. 많은 인덱스들은 그만큼 많은 공간을 차지합니다.
특히 많은 인덱스들로 인해옵티마이저가 잘못된 인덱스를 선택할 확률이 높습니다.
인덱스 키 값의크기
InnoDB (MySQL)은 디스크에 데이터를 저장하는 가장 기본 단위를 페이지라고 하며,인덱스 역시 페이지 단위로 관리됩니다. (B-Tree 인덱스 구조에서 Root, Branch, Leaf 참고)
페이지는 16KB 로 크기가 고정되어 있습니다.
만약 본인이 설정한 인덱스 키의 크기가 16 Byte 라고 하고, 자식노드(Branch, Leaf)의 주소(위 인덱스 구조 그림 참고)가 담긴 크기가 12 Byte 정도로 잡으면,16*1024 / (16+12) = 585로 인해 하나의 페이지에는 585개가 저장될 수 있습니다. 여기서 인덱스 키가 32 Byte로 커지면 어떻게 될까요? 16*1024 / (32+12) = 372로 되어 372개만 한 페이지에 저장할 수 있게 됩니다.
조회결과로 500개의 row를 읽을때 16byte일때는 1개의 페이지에서 다 조회가 되지만, 32byte일때는 2개의 페이지를 읽어야 하므로 이는 성능 저하가 발행하게 됩니다.
인덱스의 키는 길면 길수록 성능상 이슈가 있습니다.
인덱스 컬럼 기준
먼저 말씀드릴 것은 1개의 컬럼만 인덱스를 걸어야 한다면, 해당 컬럼은카디널리티(Cardinality)가 가장 높은 것을 잡아야 한다는 점입니다.
카디널리티(Cardinality)란 해당 컬럼의중복된 수치를 나타냅니다. 예를 들어 성별, 학년 등은 카디널리티가 낮다고 얘기합니다. 반대로 주민등록번호, 계좌번호 등은 카디널리티가 높다고 얘기합니다.
인덱스로 최대한 효율을 뽑아내려면,해당 인덱스로 많은 부분을 걸러내야 하기 때문입니다. 만약 성별을 인덱스로 잡는다면, 남/녀 중 하나를 선택하기 때문에 인덱스를 통해 50%밖에 걸러내지 못합니다. 하지만 주민등록번호나 계좌번호 같은 경우엔인덱스를 통해 데이터의 대부분을 걸러내기 때문에빠르게 검색이 가능합니다.
여러 컬럼으로 인덱스 구성시 기준
자 그럼 여기서 궁금한 것이 있습니다. 여러 컬럼으로 인덱스를 잡는다면 어떤 순서로 인덱스를 구성해야 할까요? 카디널리티가 낮은->높은순으로 구성하는게 좋을까요? 카디널리티가 높은->낮은순으로 구성하는게 좋을까요? 실제 실험을 통해 확인해보겠습니다.
테스트 환경은 AWS EC2 Ubuntu 16.04를 사용했습니다. 최대한 극적인 비교를 위해 메모리는 1G, 디스크는 마그네틱(SSD X)을 사용했습니다.
테이블 형태는 아래와 같습니다.
CREATE TABLE `salaries` (
`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT,
`emp_no` int(11) NOT NULL,
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
`is_bonus` tinyint(1) unsigned zerofill DEFAULT NULL,
`group_no` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
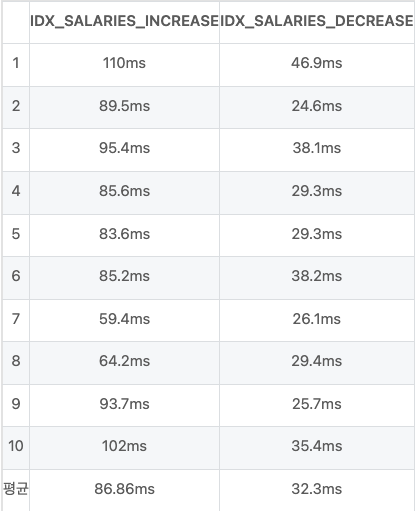
첫번째 인덱스는is_bonus, from_date, group_no순으로카디널리티가 낮은순에서 높은순 (중복도가 높은 순에서 낮은순으로)으로, 두번째 인덱스는group_no, from_date, is_bonus순으로카디널리티가 높은순에서 낮은순 (중복도가 낮은 순에서 높은순으로)으로 생성했습니다.
CREATE INDEX IDX_SALARIES_INCREASE ON salaries
(is_bonus, from_date, group_no);
CREATE INDEX IDX_SALARIES_DECREASE ON salaries
(group_no, from_date, is_bonus);
사용한 쿼리
select SQL_NO_CACHE *
from salaries
use index (IDX_SALARIES_INCREASE)
where from_date = '1998-03-30'
and group_no in ('abcdefghijklmn10494','abcdefghijklmn3968', 'abcdefghijklmn11322', 'abcdefghijklmn13902', 'abcdefghijklmn100', 'abcdefghijklmn10406')
and is_bonus = true;
select SQL_NO_CACHE *
from salaries
use index (IDX_SALARIES_DECREASE)
where from_date = '1998-03-30'
and group_no in ('abcdefghijklmn10494','abcdefghijklmn3968', 'abcdefghijklmn11322', 'abcdefghijklmn13902', 'abcdefghijklmn100', 'abcdefghijklmn10406')
and is_bonus = true;
즉, 여러 컬럼으로 인덱스를 잡는다면카디널리티가 높은순에서 낮은순으로 (group_no, from_date, is_bonus) 구성하는게 더 성능이 뛰어납니다
인덱스
책의 제일 끝에 있는 찾아보기 (목차랑은 다른개념이다.)
데이터 : 책의 내용 / 인덱스 : 찾아보기
책의 찾아보기와 인덱스의 공통점 : 정렬
프로그래밍 언어의 자료구조로 인덱스와 데이터 파일을 비교
SortedList : 인덱스와 같은 자료구조
저장되는 값을 항상 정렬된 상태로 유지하는 자료구조
장점 : 이미 정렬되어 있기 때문에 아주 빠르게 원하는 값을 찾을 수 있음(Select)
ArrayList : 데이터와 파일과 같은 자료구조
값을 저장되는 순서대로 그대로 유지하는 자료구조
DBMS의 인덱스는 데이터의 저장(Insert, update, delete) 성능을 희생하고 대신 데이터의 읽기 속도를 높이는 기능
Select 문장의 Where 조건절에 사용되는 모든 컬럼을 인덱스로 생성하면 저장성능이 떨어지고, 인덱스 크기가 커져 오히려 역효과
인덱스 데이터 저장 방식(알고리즘) 별로 구분
B-tree 인덱스
컬럼의 값을 번형하지 않고, 원래의 값을 이용하여 인덱싱
Hash 인덱스
컬럼의 값으로 해시 값을 계산해서 인덱싱
매우 빠른 검색을 지원
실습으로 DB 인덱싱 알아보기
실습1 : 모든 동물 테이블을 검색하고, nocope를 검색한다. 그리고 인덱싱 처리해서 실행시간을 비교한다.
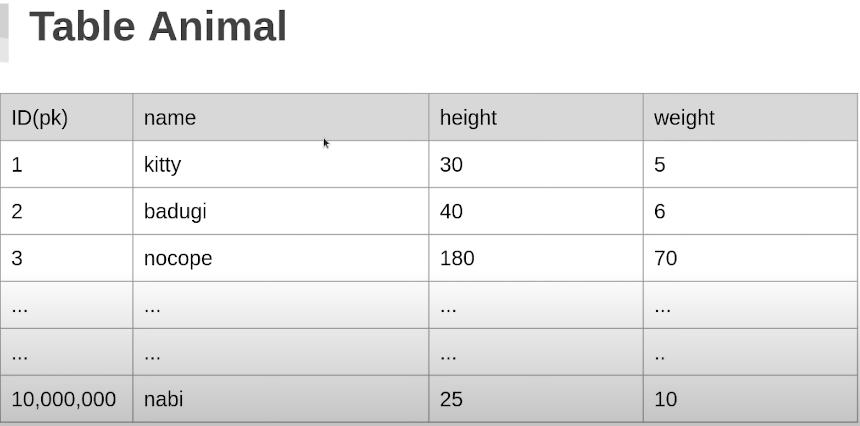
위와 같은 Animal 테이블이 있다고 가정하자.
그리고 천만 건의 데이터 중를 모두 select count(*) from Animals; 해주고 또 nocope를 검색하는 쿼리를 날려준다.
각각 3.6초, 4.5초가 걸렸다. 엄청 오래 걸린다...즉, 서비스에서는 못쓴다는 것이다.
인덱스 추가하기
CREATE INDEX ANIMAL_NAME ON ANIMALS(NAME);
동물 이름에 index를 추가해보자
그러고 성능비교를 해보자 그랬더니 0.003초로 엄청나게 빨라졌다.
어떻게 동작하는 것인가?
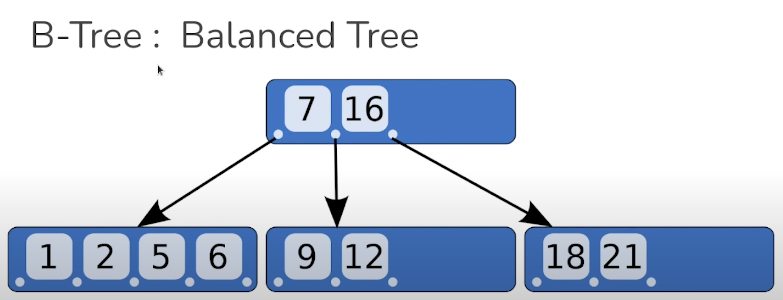
B-Tree : Balanced Tree
위의 그림에서 5를 찾고 싶다라고 가정하면 7과 비교해서 작은 왼쪽트리로 가고 만약 9를 찾고 싶다하고 하면 가운데 트리로 이동하는 개념이다.
위의 상황을 살펴보자. 동물이름은 비트리안에서 오름차순으로 정렬이 되어있다. 만약 nabi를 찾고 싶다면 meow와 비교해서 뒷편에 있을 테니 2번째 브랜치로 이동하여 탐색하는 개념이다.
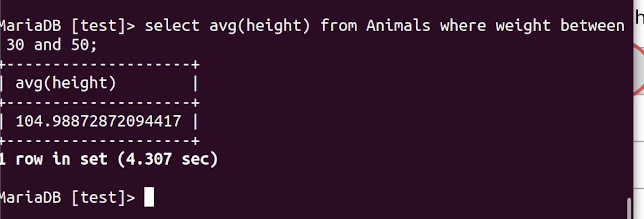
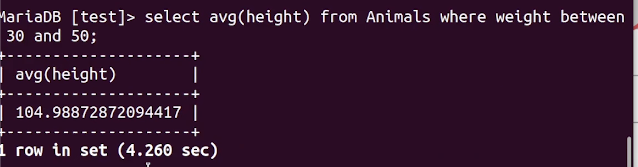
실습2 : 동물 테이블에서 키가 30cm~50cm 사이인 동물의 평균 키는?
해당 쿼리를 실행 시켜보았다. 4.3초... 이것도 서비스에서는 못쓴다.
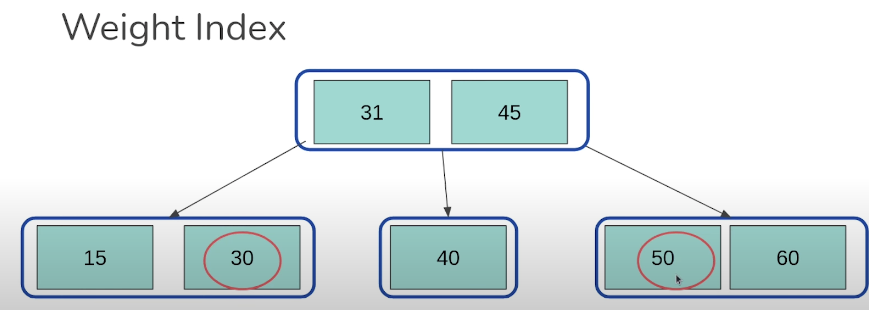
인덱스 적용하기
CREATE INDEX ANIMAL_WEIGHT ON ANIMALS(weight);
몸무게에 where절이 걸렸으므로 weght에 인덱스를 걸어준다.
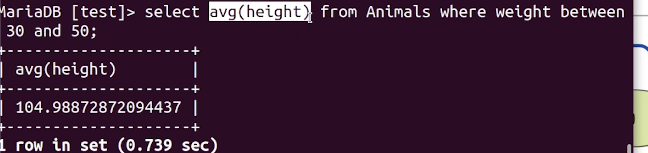
하지만...
같은 쿼리를 실행하면 4.2초로 성능 차이가 없다. weight가 전혀 인덱스를 안탄것인데 왜 그런지 알아보자.
between 이므로 시작점 30과 끝점 50을 찾는다.
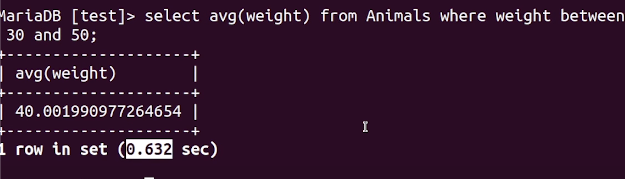
만약 위처럼 평균 키(height)가 아닌 평균 몸무게(weight)로 검색했다면 인덱스를 잘 타고 0.6초 만에 검색이 되었을 것이다. 왜냐면 해당 쿼리문을 실행 시키기 위한 모든 정보가 인덱스 안에 있기 때문이다.
즉, 위의 쿼리는 키에 따른 몸무게 정보를 알기 위해서 full scan 과정을 또 겪었을 것이며 인덱스를 타지 않았다.
해결 방법
각 몸무게에 대한 키정보를 인덱싱한다.
다음과 같이 키, 몸무게 정보를 담은 인덱싱을 한다.
CREATE INDEX animal_wh on Animal(weight,height)
결과
0.7초로 단축하며 인덱스를 타는 것을 알 수 있다.
마지막으로 인덱스를 잘 타는지 확인하고 싶다면 analyze 키워드를 맨 앞에 쓰면 된다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
static int[][] map, visited;
static boolean[] successCheck;
static int N, M, num = 1, ans = 0;
static int[][] dt = {{-1, 0}, {0, 1}, {1, 0}, {0, -1}};
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
N = Integer.parseInt(st.nextToken());
M = Integer.parseInt(st.nextToken());
map = new int[N][M];
visited = new int[N][M];
successCheck = new boolean[N * M + 1];
for (int i = 0; i < N; i++) {
String input = br.readLine();
for (int j = 0; j < M; j++) {
char c = input.charAt(j);
if (c == 'U') map[i][j] = 0;
else if (c == 'R') map[i][j] = 1;
else if (c == 'D') map[i][j] = 2;
else map[i][j] = 3;
}
}
for (int i = 0; i < N; i++) {
for (int j = 0; j < M; j++) {
if (visited[i][j] != 0) continue;
dfs(i, j, 0);
num++;
}
}
System.out.println(ans);
br.close();
}
public static void dfs(int x, int y, int count) {
//만약 처음 탈출했다면.
if (check(x, y)) {
successCheck[num] = true;
ans += count;
return;
//만약 처음 탈출이 아니라면
} else if (visited[x][y] != 0) {
if (successCheck[visited[x][y]]) {
successCheck[num] = true;
ans += count;
}
return;
}
visited[x][y] = num; //visit 체크해주기
dfs(x + dt[map[x][y]][0], y + dt[map[x][y]][1], count + 1); // 방향 별로 넣어주기
}
//탈출조건 체크
public static boolean check(int x, int y) {
return x < 0 || x >= N || y < 0 || y >= M;
}
}