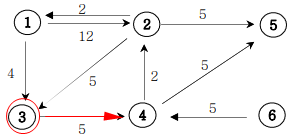
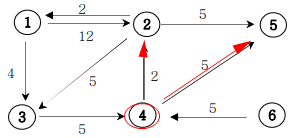
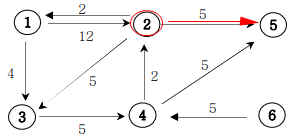
priority_queue<자료형, 구현체(container), 비교 연산자(compare 함수)>
구현하기전 필수사항
#include <algorithm>
#include <queue>
#include <functional>최소 힙 (= queue에 가장 top이 가장 작은 값으로 올라 오는 경우)
priority_queue<int, vector<int>, greater<int>> min_pq; //오름차순
min_pq.push(3);
min_pq.push(4);
min_pq.push(5);
min_pq.push(6); //3,4,5,6
최대 힙 (= queue에 가장 top이 가장 큰 값으로 올라는 오는 경우)
priority_queue<int, vector<int>, less<int >> max_pq;// 내림차순
max_pq.push(1);
max_pq.push(10);
max_pq.push(100);
max_pq.push(33); //100,33,10,1
'Algorithm > Algorithm_Tip' 카테고리의 다른 글
| [형변환 정리] String<->char , char<->int, int<->String (0) | 2020.10.24 |
|---|---|
| [pair 정렬] vector를 이용한 pair 정렬 (0) | 2020.10.21 |
| [Tip] 문자열 짜르기 (0) | 2020.09.17 |
| [C++] 대문자 <-> 소문자 변경 (0) | 2020.09.16 |
| [강의] 투포인트 알고리즘 (0) | 2020.09.12 |